Confusion Matrix混淆矩阵
在机器学习领域,混淆矩阵(confusion matrix),又称为可能性表格或是错误矩阵。它是一种特定的矩阵用来呈现算法性能的可视化效果,通常是监督学习(非监督学习,通常用匹配矩阵:matching matrix)。其每一列代表预测值,每一行代表的是实际的类别。这个名字来源于它可以非常容易的表明多个类别是否有混淆(也就是一个class被预测成另一个class)。
假设有一个用来对猫(cats)、狗(dogs)、兔子(rabbits)进行分类的系统,混淆矩阵就是为了进一步分析性能而对该算法测试结果做出的总结。假设总共有27只动物:8只猫,6条狗,13只兔子。结果的混淆矩阵如下图:
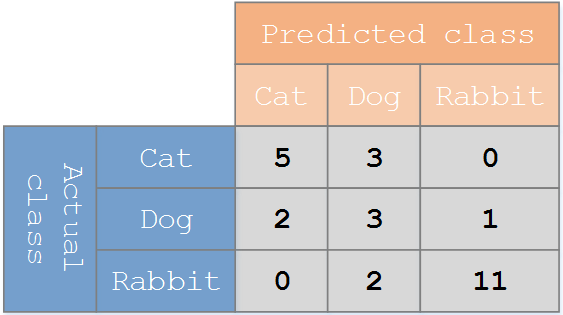
在这个混淆矩阵中,实际有8只猫,但是系统将其中3只预测成了狗;对于6条狗,其中有1条被预测成了兔子,2条被预测成了猫。从混淆矩阵中我们可以看出系统对于区分猫和狗存在一些问题,但是区分兔子和其他动物的效果还是不错的。所有正确的预测结果都在对角线上,所以从混淆矩阵中可以很方便直观的看出哪里有错误,因为他们呈现在对角线外面。
在预测分析中,混淆表格(有时候也称为混淆矩阵),是由false positives,false negatives,true positives和true negatives组成的两行两列的表格。它允许我们做出更多的分析,而不仅仅是局限在正确率。准确率对于分类器的性能分析来说,并不是一个很好地衡量指标,因为如果数据集不平衡(每一类的数据样本数量相差太大),很可能会出现误导性的结果。例如,如果在一个数据集中有95只猫,但是只有5条狗,那么某些分类器很可能偏向于将所有的样本预测成猫。整体准确率为95%,但是实际上该分类器对猫的识别率是100%,而对狗的识别率是0%。
对于上面的混淆矩阵,其对应的对猫这个类别的混淆表格如下:

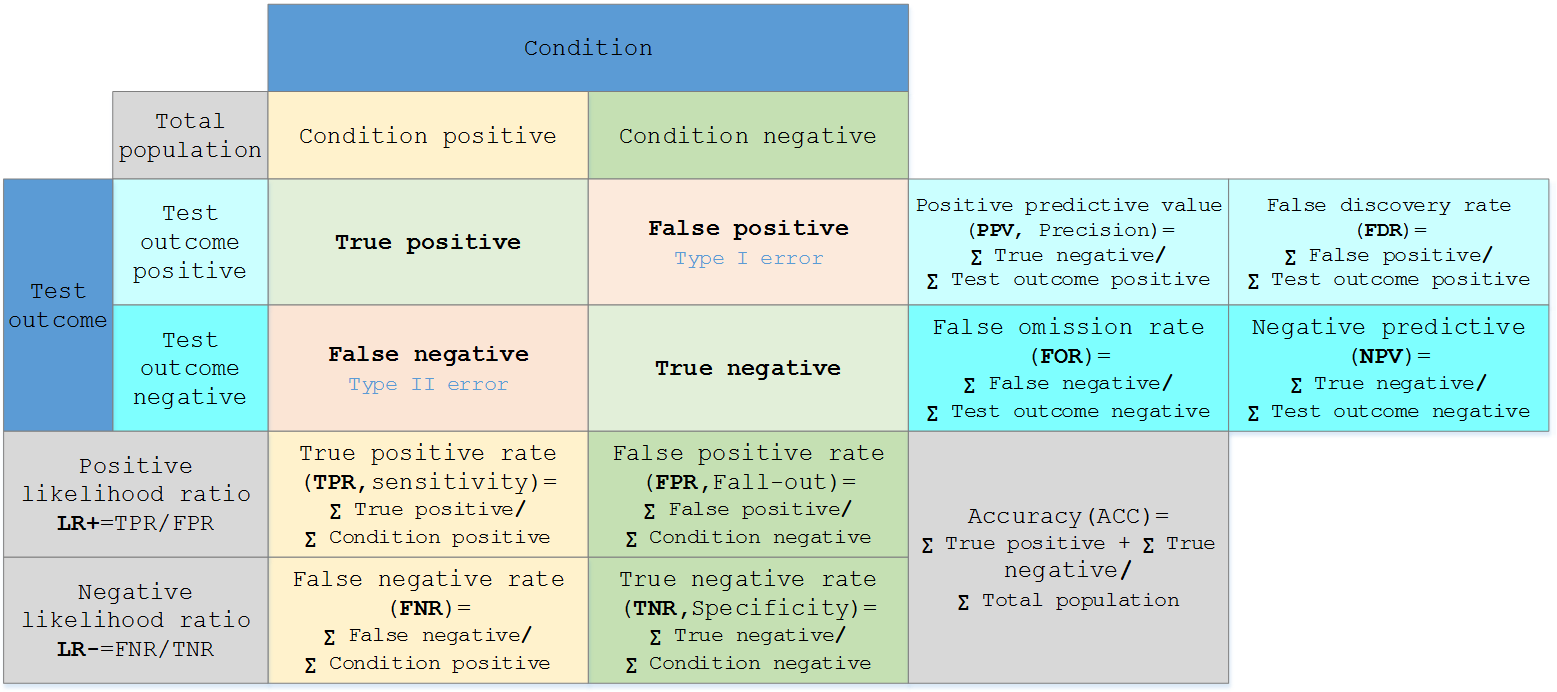
假定一个实验有 P个positive实例,在某些条件下有 N 个negative实例。那么上面这四个输出可以用下面的偶然性表格(或混淆矩阵)来表示:
参考链接:http://en.wikipedia.org/wiki/Confusion_matrix
代码实现:
knn = KNeighborsClassifier(n_neighbors=7) knn.fit(X_train, y_train) from sklearn.metrics import confusion_matrix y_pred = knn.predict(X_test) confusion_matrix(y_test, y_pred) pd.crosstab(y_test, y_pred, rownames=['True'], colnames=['Predicted'], margins=True)
Predicted 0 1 All True 0 165 36 201 1 47 60 107 All 212 96 308
Classification Report
sklearn中的classification_report函数用于显示主要分类指标的文本报告。在报告中显示每个类的精确度,召回率,F1值等信息。
主要参数:
- y_true:1维数组,或标签指示器数组/稀疏矩阵,目标值。
- y_pred:1维数组,或标签指示器数组/稀疏矩阵,分类器返回的估计值。
- labels:array,shape=[n_labels],报表中包含的标签索引的可选列表。
- target_names:字符串列表,与标签匹配的可选显示名称(相同顺序)。
- sample_weight:类似于shape=[n_samples]的数组,可选项,样本权重。
- digits:int,输出浮点值的位数。
from sklearn.metrics import classification_report print(classification_report(y_test, y_pred))
precision recall f1-score support 0 0.78 0.82 0.80 201 1 0.62 0.56 0.59 107 avg/total 0.73 0.73 0.73 308
其中,precision为精确度,recall为召回率,f1-score为F1值,support为每列标签出现的次数。
精确度&召回率
精确度和召回率有时也被称为查准率和查全率,通常用P代表Precision,R代表Recall。而从字面上看差准率和查全率更加容易理解。如下图所示,假设有若干张图片,其中12张是狗的图片其余是猫的图片.现在利用程序去识别狗的图片,结果在识别出的8张图片中有5张是狗的图片,3张是猫的图片(属于误报)。
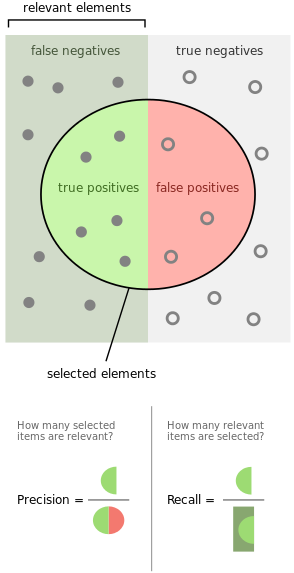
图中,实心小圆代表狗的图片,虚心小圆代表猫的图片,圆形区域代表识别结果.则该程序的精度precision=5/8,召回率recall=5/12。当一个搜索引擎返回30个页面时,只有20页是相关的,而没有返回40个额外的相关页面,其精度为20/30=2/3,而其召回率为20/60=1/3。在这种情况下,精确度是”搜索结果有多大用处”,而召回是”结果如何完整”。
from sklearn.metrics import precision_score from sklearn.metrics import recall_score print(precision_score(y_test, y_pred)) print(recall_score(y_test, y_pred))
参考链接:https://en.wikipedia.org/wiki/Precision_and_recall
F1值
如上所述,P和R指标有的时候是矛盾的,F-Measure综合这二者指标的评估指标,用于综合反映整体的指标。F-Measure是Precision和Recall加权调和平均,公式如下:
$$F=\frac{(a^2+1)P\times R}{a^2(P+R)}$$
当参数a=1时,就是最常见的F1公式:
$$F=\frac{2PR}{P+R}$$
精确度和召回率都高时,F1值也会高。F1值在1时达到最佳值(完美的精确度和召回率),最差为0。在二元分类中,F1值是测试准确度的量度。
ROC曲线和AUC值
ROC
ROC曲线指受试者工作特征曲线/接收器操作特性曲线(receiver operating characteristic curve),是反映敏感性和特异性连续变量的综合指标,是用构图法揭示敏感性和特异性的相互关系,它通过将连续变量设定出多个不同的临界值,从而计算出一系列敏感性和特异性,再以敏感性为纵坐标、(1-特异性)为横坐标绘制成曲线,曲线下面积越大,诊断准确性越高。在ROC曲线上,最靠近坐标图左上方的点为敏感性和特异性均较高的临界值。
考虑一个二分问题,即将实例分成正类(positive)或负类(negative)。对一个二分问题来说,会出现四种情况。如果一个实例是正类并且也被预测成正类,即为真正类(True positive),如果实例是负类被预测成正类,称之为假正类(False positive)。相应地,如果实例是负类被预测成负类,称之为真负类(True negative),正类被预测成负类则为假负类(false negative)。
如下表所示,1代表正类,0代表负类。
- TP:正确肯定的数目
- FN:漏报,没有正确找到的匹配的数目
- FP:误报,给出的匹配是不正确的
- TN:正确拒绝的非匹配对数

从表引入两个新名词。其一是真正类率(true positive rate, TPR),计算公式为TPR=TP/(TP+FN),刻画的是分类器所识别出的正实例占所有正实例的比例。另外一个是假正类率(false positive rate, FPR),计算公式为FPR=FP/(FP+TN),计算的是分类器错认为正类的负实例占所有负实例的比例。还有一个真负类率(True Negative Rate,TNR),也称为specificity,计算公式为TNR=TN/(FP+TN)=1-FPR。
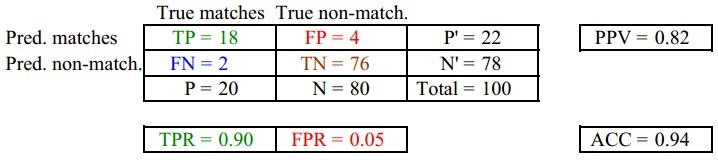
其中,两列True matches和True non-match分别代表应该匹配上和不应该匹配上的,两行Pred matches和Pred non-match分别代表预测匹配上和预测不匹配上的。
- FPR=FP/(FP+TN)负样本中的错判率(假警报率)
- TPR=TP/(TP+FN)判对样本中的正样本率(命中率)
- ACC=(TP+TN)/(P+N)判对准确率
在一个二分类模型中,对于所得到的连续结果,假设已确定一个阀值,比如说0.6,大于这个值的实例划归为正类,小于这个值则划到负类中。如果减小阀值,减到0.5,固然能识别出更多的正类,也就是提高了识别出的正例占所有正例的比类,即TPR,但同时也将更多的负实例当作了正实例,即提高了FPR。为了形象化这一变化,在此引入ROC,ROC曲线可以用于评价一个分类器。
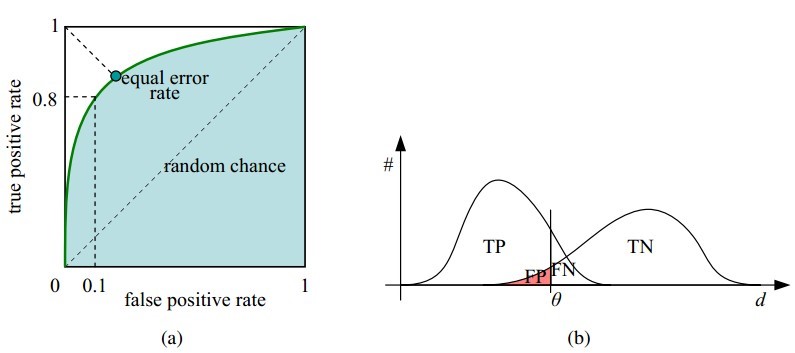
ROC曲线和它相关的比率
- 理想情况下,TPR应该接近1,FPR应该接近0。ROC曲线上的每一个点对应于一个threshold,对于一个分类器,每个threshold下会有一个TPR和FPR。比如Threshold最大时,TP=FP=0,对应于原点;Threshold最小时,TN=FN=0,对应于右上角的点(1,1)。
- P和N得分不作为特征间距离d的一个函数,随着阈值theta增加,TP和FP都增加。
- 横轴FPR:1-TNR,1-Specificity,FPR越大,预测正类中实际负类越多。
- 纵轴TPR:Sensitivity(正类覆盖率),TPR越大,预测正类中实际正类越多。
- 理想目标:TPR=1,FPR=0,即图中(0,1)点,故ROC曲线越靠拢(0,1)点,越偏离45度对角线越好,Sensitivity、Specificity越大效果越好。
- 随着阈值threshold调整,ROC坐标系里的点如何移动可以参考:
随着阈值threshold调整,ROC坐标系里的点如何移动可以参考:
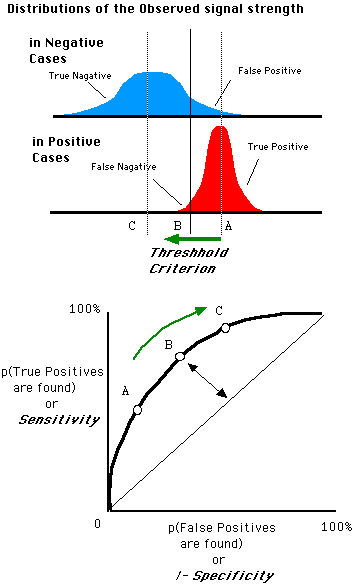
对于一个特定的分类器和测试数据集,显然只能得到一个分类结果,即一组FPR和TPR结果,而要得到一个曲线,我们实际上需要一系列FPR和TPR的值,这又是如何得到的呢?我们先来看一下Wikipedia上对ROC曲线的定义:
In signal detection theory, a receiver operating characteristic (ROC), or simply ROC curve, is a graphical plot which illustrates the performance of a binary classifier system as its discrimination threshold is varied.
问题在于“as its discrimination threashold is varied”。如何理解这里的“discrimination threashold”呢?我们忽略了分类器的一个重要功能“概率输出”,即表示分类器认为某个样本具有多大的概率属于正样本(或负样本)。通过更深入地了解各个分类器的内部机理,我们总能想办法得到一种概率输出。通常来说,是将一个实数范围通过某个变换映射到(0,1)区间。
假如我们已经得到了所有样本的概率输出(属于正样本的概率),现在的问题是如何改变“discrimination threashold”?我们根据每个测试样本属于正样本的概率值从大到小排序。下图是一个示例,图中共有20个测试样本,“Class”一栏表示每个测试样本真正的标签(p表示正样本,n表示负样本),“Score”表示每个测试样本属于正样本的概率。
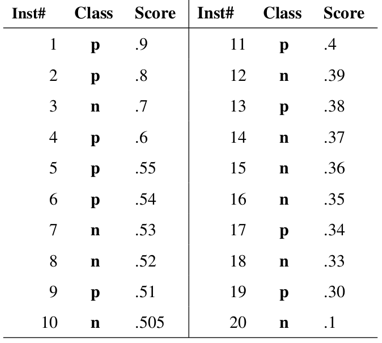
接下来,我们从高到低,依次将“Score”值作为阈值threshold,当测试样本属于正样本的概率大于或等于这个threshold时,我们认为它为正样本,否则为负样本。举例来说,对于图中的第4个样本,其“Score”值为0.6,那么样本1,2,3,4都被认为是正样本,因为它们的“Score”值都大于等于0.6,而其他样本则都认为是负样本。每次选取一个不同的threshold,我们就可以得到一组FPR和TPR,即ROC曲线上的一点。这样一来,我们一共得到了20组FPR和TPR的值,将它们画在ROC曲线的结果如下图:
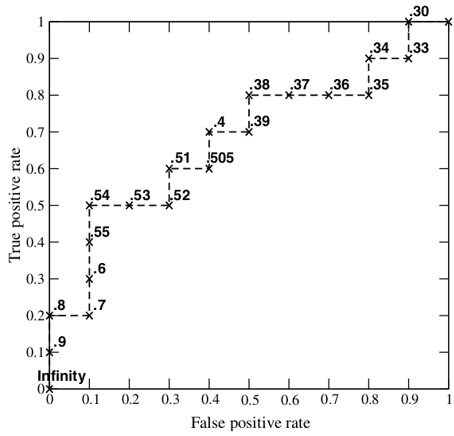
当我们将threshold设置为1和0时,分别可以得到ROC曲线上的(0,0)和(1,1)两个点。将这些(FPR,TPR)对连接起来,就得到了ROC曲线。当threshold取值越多,ROC曲线越平滑。其实,我们并不一定要得到每个测试样本是正样本的概率值,只要得到这个分类器对该测试样本的“评分值”即可(评分值并不一定在(0,1)区间)。评分越高,表示分类器越肯定地认为这个测试样本是正样本,而且同时使用各个评分值作为threshold。我认为将评分值转化为概率更易于理解一些。
from sklearn.metrics import roc_curve
y_pred_proba = knn.predict_proba(X_test)[:,1]
fpr, tpr, thresholds = roc_curve(y_test, y_pred_proba)
plt.plot([0,1], [0,1], 'k--')
plt.plot(fpr, tpr, label='Knn')
plt.xlabel('fpr')
plt.ylabel('tpr')
plt.title('Knn(n_neighbors=7) ROC curve')
plt.show()
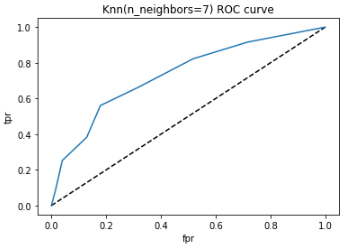
AUC
ROC曲线是根据与那条参照线进行比较来判断模型的好坏,但这只是一种直觉上的定性分析,如果我们需要精确一些,就要用到AUC,也就是ROC曲线下面积。其判定方法是AUC应该大于0.5。如图所示:
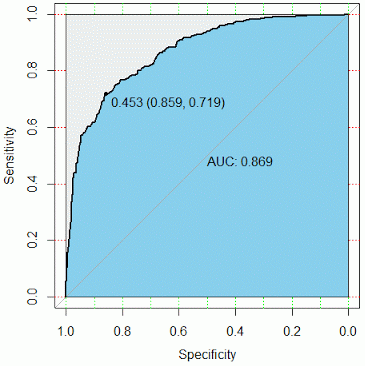
如上图所示,参考线的面积是0.5,ROC曲线与它偏离越大,ROC曲线就越往左上方靠拢,它下面的面积(AUC)也就越大,这里面积是0.869。我们可以根据AUC的值与0.5相比,来评估一个分类模型的预测效果。如果AUC的值达到0.80,那说明分类器分类非常准确;如果AUC值在0.60~0.80之间,那分类器有优化空间,可以通过调节参数得到更好的性能;如果AUC值小于0.60,那说明分类器模型效果比较差。
from sklearn.metrics import roc_auc_score roc_auc_score(y_test, y_pred_proba)
0.7345050448691124
参考链接:https://en.wikipedia.org/wiki/Receiver_operating_characteristic
对数损失(LogLoss)
若有n个样本,对于第i个样本,它的真实label为$y_i$为{0,1},预测概率为$y_i^{‘}$为{0,1},LogLoss计算公式如下:
$$LogLoss=-\frac{1}{n}\sum_{i}[y_i\log(y_i^{‘})+(1-y_i)\log(1-y_i^{‘})]$$
LogLoss衡量的是预测概率分布和真实概率分布的差异性,取值越小越好。
logloss和auc的区别:
- logloss主要是评估是否准确的,auc是用来评估是把正样本排到前面的能力,评估的方面不一样。
- logloss主要评估整体准确性,多用于数据平衡的情况。auc用来评估数据不平衡情况的,模型准确度。如果是平衡的分类问题,那么AUC和LogLoss都可以。
GridSearchCV网格搜索
GridSearchCV,它存在的意义就是自动调参,只要把参数输进去,就能给出最优化的结果和参数。但是这个方法适合于小数据集,一旦数据的量级上去了,很难得出结果。这个时候就是需要动脑筋了。数据量比较大的时候可以使用一个快速调优的方法——坐标下降。它其实是一种贪心算法:拿当前对模型影响最大的参数调优,直到最优化;再拿下一个影响最大的参数调优,如此下去,直到所有的参数调整完毕。这个方法的缺点就是可能会调到局部最优而不是全局最优,但是省时间省力,巨大的优势面前,还是试一试吧,后续可以再拿bagging再优化。回到sklearn里面的GridSearchCV,GridSearchCV用于系统地遍历多种参数组合,通过交叉验证确定最佳效果参数。
from sklearn.model_selection import GridSearchCV
param_grid = {'n_neighbors': np.arange(1,50)}
knn = KNeighborsClassifier()
knn_cv = GridSearchCV(knn, param_grid, cv=5)
knn_cv.fit(X, y)
print(knn_cv.best_score_)
print(knn_cv.best_params_)
0.7578125
{'n_neighbors':14}


