Conda是一个开源的包管理系统和环境管理系统,主要用于简化软件包安装和管理,同时还能创建和管理独立的环境。这些功能使得Conda在数据科学、机器学习和科学计算领域非常受欢迎。 Conda的安装 安装Conda有两种主…

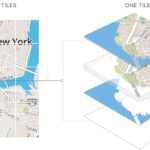
地图提供商瓦片服务地图规则 瓦片地图简介 瓦片地图(TileMap)是地理信息系统(GIS)和网络地图应用中一种常见的地图显示方式。通过将地图切分成若干小块(称为"瓦片"),用户可以在浏览时仅加载当前视角所需的部…
地理空间数据的获取 OWSLib OWSLib 是一个 Python 库,专为与开放地理空间联盟 (Open Geospatial Consortium, OGC) 的标准服务进行交互而设计。OGC 定义了一系列标准协议,旨在促进地理空间数据和服务的互操作性。O…

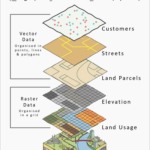
地理空间数据库(Geospatial Database)是一种专门用于存储、查询和管理地理空间数据的数据库。地理空间数据库的特点: 空间数据类型:不仅支持传统的文本、数值等数据类型,还支持地理空间数据类型,如点(Poi…

地理空间数据格式用于存储和描述与地理位置相关的数据。这些数据可以是栅格(图像)数据或矢量数据。不同的格式有各自的特点和适用场景。 以下是一些常见的地理空间数据格式: 矢量数据格式 矢量数据格式是地理…
mapclassify简介 mapclassify是一个Python库,主要作用是为空间数据提供分类和分级的方法,以便在地图上进行可视化和分析。通过将连续的数值数据分成离散的类别或等级,mapclassify能够帮助用户更清晰地理解和展示…
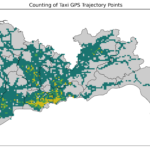
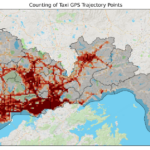
TransBigData 简介 TransBigData 是一个为交通时空大数据处理、分析和可视化而开发的 Python 包。TransBigData 为处理常见的交通时空大数据(如出租车 GPS 数据、共享单车数据和公交车 GPS 数据)提供了快速而简洁…
NVM简介 NVM(Node Version Manager)是一个命令行工具,用于在一台计算机上方便地安装、切换和管理多个Node.js版本。它最初由Tim Caswell开发,现在由一个社区维护的团队进行更新和维护。NVM主要用于Unix-like系统…

kepler.gl简介 Kepler.gl是一个开源的地理空间数据可视化工具,由Uber开发并开源。它旨在帮助用户快速、直观地探索和展示大型地理空间数据集。 主要特点 用户友好界面,提供了一个直观的界面,使用户能够轻松…

基本语法 注释和文档字符串 在Python编程中,注释和文档字符串是非常重要的工具,用于提高代码的可读性和可维护性。它们可以帮助你更好地解释代码的功能和逻辑,方便他人或自己在将来阅读和理解代码。 注释 注释是…
