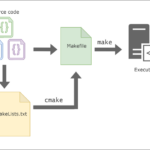
CMake简介 CMake是一个项目构建工具,并且是跨平台的。关于项目构建我们所熟知的还有Makefile(通过make命令进行项目的构建),大多是IDE软件都集成了make,比如:VS的nmake、linux下的GNU make、Qt的qmake等,如果…
希腊字母被用于数学、科学、工程和其他方面。在数学方面,希腊字母通常用于常数、特殊函数和特定的变量,而且通常大写和小写都有分别,而且互不相关。有些希腊字母因字形和拉丁字母一样,而不被使用,如:A, B, E, …

在日常的工作中,使用较多的是 Presto,原因是它比 Spark 快非常多。当然,使用过程中也会遇到一些问题,其中主要的是一些内置函数与SparkSQL 存在较大的差异。这里对 Presto SQL 一个简单的整理。关于 Presto 的相…
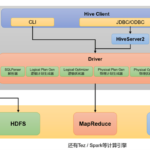
Apache Hive 是一个开源的数据仓库框架,用于查询和分析大数据集存储在 Hadoop 文件系统中。 Hive 提供了一种类 SQL 的查询语言,叫做 HiveQL,它使得熟悉 SQL 的用户可以在 Hive 上查询、汇总和分析数据。同时,…
Markdown简介 Markdown是一种轻量级标记语言,它允许人们使用易读易写的纯文本格式编写文档,然后转换成有效的HTML,或者其他格式的文件。Markdown也可以理解为将以MARKDOWN语言编写的语言转换成HTML内容的工具,最…

日常工作很多自动化的任务使用的是 Spark 运行,这里抽时间地 SparkSQL 进行系统的学习。 SparkSQL 与 HiveSQL 的区别 Hive 和 Spark 都是 Apache 的开源框架,而HiveSQL 和 SparkSQL 是这两种框架上运行的 SQL …

在知识管理过程中,需要给信息进行分类,这看起来是个很简单的工作,实际确超复杂,原因是有些知识点是在难以进行分类。于是网上找了一些方法,供自己思考与完善。 信息分类的要求 构建一个良好分类法的关键要素: …

在机票搜索中,最关键的三要素通常包括: 出发地和目的地:这是任何机票搜索的基本核心。你需要知道从哪里出发,以及你想要去哪里。 日期:你需要知道出发和返回的日期。这一信息将直接影响航班的可用性和价…

公司记录日志的时候,将请求数据和返回数据以JSON格式存储到了数据库中,为了更高的处理这部分JSON数据,就用到了SparkSQL自带的一些JSON函数。这里做这些函数的方法做了一些整理。 get_json_object(json_txt, pa…

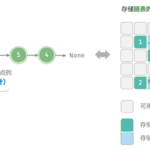
链表简介 链表(LinkedList)是一种基础的数据结构,是由一系列节点(Node)组成的集合。每个节点包括两部分:一部分是数据,另一部分是指向下一个节点的引用(在双向链表中,还有指向前一个节点的引用)。 这是链…