韦恩图简介
维恩图(Venn),也叫温氏图、维恩图、范氏图,用于显示元素集合重叠区域的图表。维恩图是关系型图表,通过图形与图形之间的层叠关系,来表示集合与集合之间的相交关系。

适合场景1:表示2个集合相交关系
- 场景说明:有一个集合A,有一个集合B,相交集合为C。
- 数据说明:2个维度数据,分类数据映射集合名,关系数据映射集合关系。
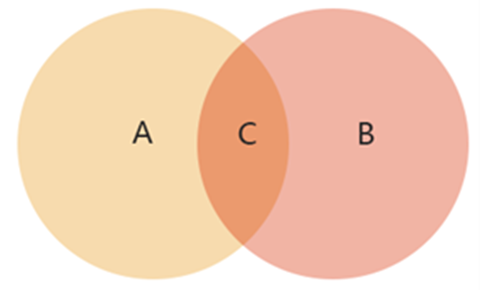
适合场景2:表示3个集合相交关系
- 场景说明:有集合A、B、C。
- 数据说明:2个维度数据,分类数据映射集合名,关系数据映射集合关系。
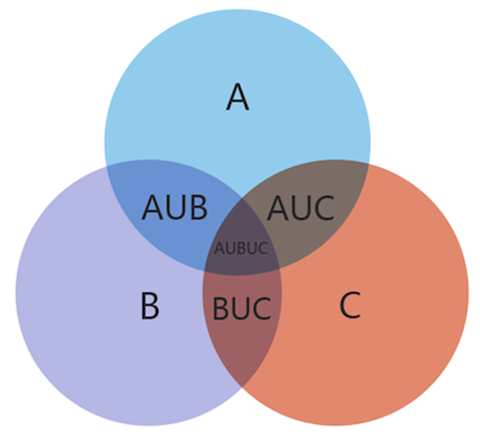
适合场景3:表示4个集合相交关系
- 场景说明:有一个集合A、B、C、D。
- 数据说明:2个维度数据,分类数据映射集合名,关系数据映射集合关系。
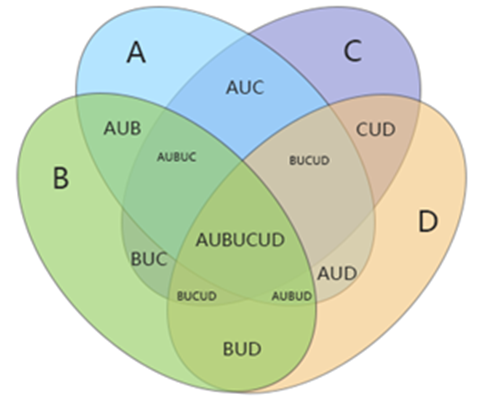
不适合韦恩图的场景
- 超过五个集合的场景,不适合适用韦恩图。
使用Python绘制韦恩图的方法
在Python中,有多个用于绘制韦恩图的工具包。以下是其中几个:
- matplotlib_venn:matplotlib_venn是一个基于matplotlib的Python包,用于绘制双向和三向韦恩图。它支持任意数量的集合,并且可以自定义颜色、标签和字体等属性。
- matplotlib_venn_wordcloud:这是一个基于matplotlib和wordcloud的Python包,用于绘制带有标签的韦恩图(也称为文本韦恩图)。它生成的图形显示每个集合的标签,并根据集合之间的重叠程度调整标签大小。
- upsetplot:upsetplot是一个用于绘制交集和韦恩图的Python库。它支持任意数量的集合和交集,并提供了很多可视化选项。
matplotlib_venn
Python中Matplotlib并没有现成的函数可直接绘制venn图,matplotlib_venn需要单独的安装。matplotlib_venn支持2-3组数据,matplotlib_venn包含’venn2′,’venn2_circles’,’venn3′,’venn3_circles’四个关键函数。
2组数据venn图
matplotlib_venn.venn2(subsets, set_labels=('A', 'B'), set_colors=('r', 'g'), alpha=0.4, normalize_to=1.0, ax=None, subset_label_formatter=None)
subsets参数接收绘图数据集,以下5种方式均可以:
import matplotlib.pyplot as plt
from matplotlib_venn import venn2, venn2_circles
subset = [[{1, 2, 3}, {1, 2, 4}], #列表list(集合1,集合2)
({1, 2, 3}, {1, 2, 4}), #元组tuple(集合1,集合2)
{'10': 1, '01': 1, '11': 2}, #字典dict(A独有,B独有,AB共有)
(3, 3, 2), ####元组tuple(A有,B有,AB共有),注意和其它几种方式的异同点
[3, 3, 2] #列表list(A有,B有,AB共有)
]
for i in subset:
plt.figure()
g = venn2(subsets=i)
plt.title('subsets=%s' % str(i))
plt.show()
简单的说,有三种方式设置subsets:
- 明细方式:提供2个集合
- 合并统计方式:接受一个3元素(Ab,aB,AB)构成的tuple/list作为各个子集所包含元素的个数(不是具体的元素),或使用类似二进制的方式设置每个场景的数值。10代表A有B没有,01代表A没有B有,11代表A有B有。
- Ab:包含A,但不包含B,即A中非B的部分,A∩¬B
- aB:包含B,但不包含A,即B中非A,B∩¬A
- AB:既包含A,又包含B,即A与B的交集,A∩B
venn2()和venn2_circles()都是用于绘制二元韦恩图的函数,但它们的作用不同。
- venn2():这个函数会生成一个包含两个圆圈和重叠区域的韦恩图。该函数需要传入两个集合并根据它们的重叠部分来绘制韦恩图。例如,以下代码展示了如何使用venn2()方法绘制一个简单的二元韦恩图:
- venn2_circles():这个函数会生成包含两个圆形的韦恩图。它可以用于自定义韦恩图的圆形和文本标签等属性。venn2_circles()函数返回一个包含两个圆形边缘的列表,可以使用这些对象来自定义圆形和设置其属性。例如,以下代码演示了如何在二元韦恩图中更改圆形颜色和透明度:
因此,venn2()函数可以方便地绘制出默认的二元韦恩图,而venn2_circles()函数提供了更多的自定义选项,对绘制更加复杂的韦恩图很有用。
复杂图形的设置示例:
plt.figure()
g = venn2(subsets=[{1, 2, 3}, {1, 2, 4}], # 绘图数据集
set_labels=('Label1', 'Label2'), # 设置组名
set_colors=("#098154", "#c72e29"), # 设置圈的颜色,中间颜色不能修改
alpha=0.6, # 透明度
normalize_to=1.0, # venn图占据figure的比例,1.0为占满
)
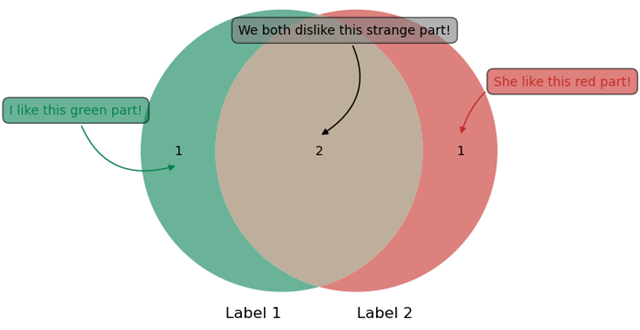
plt.annotate('I like this green part!',
color='#098154',
xy=g.get_label_by_id('10').get_position() - np.array([0, 0.05]),
xytext=(-80, 40),
ha='center', textcoords='offsetpoints',
bbox=dict(boxstyle='round, pad=0.5', fc='#098154', alpha=0.6), # 注释文字底纹
arrowprops=dict(arrowstyle='-|>', connectionstyle='arc3, rad=0.5', color='#098154') # 箭头属性设置
)
plt.annotate('She likes this red part!',
color='#c72e29',
xy=g.get_label_by_id('01').get_position() + np.array([0, 0.05]),
xytext=(80, 40),
ha='center', textcoords='offsetpoints',
bbox=dict(boxstyle='round, pad=0.5', fc='#c72e29', alpha=0.6),
arrowprops=dict(arrowstyle='-|>', connectionstyle='arc3, rad=0.5', color='#c72e29')
)
plt.annotate('We both dislike this strange part!',
color='black',
xy=g.get_label_by_id('11').get_position() + np.array([0, 0.05]),
xytext=(20, 80),
ha='center', textcoords='offsetpoints',
bbox=dict(boxstyle='round, pad=0.5', fc='grey', alpha=0.6),
arrowprops=dict(arrowstyle='-|>', connectionstyle='arc3, rad=-0.5', color='black')
)
plt.show()
3组数据venn图
类似地,venn3与venn3_circles接受一个7个元素构成的元组作为各个子集的大小(Abc, aBc, ABc, abC, AbC, aBC, ABC)。
pyvenn
pyvenn是一个用于绘制韦恩图和欧拉图的Python库。它可以绘制2至6种数据集之间的多个韦恩图和欧拉图,支持自定义颜色,标签,字体等属性。pyvenn目前已经不再维护,因此可能无法使用pip安装。可以尝试从GitHub安装。
upsetplot
Upsetplot是一个Python可视化工具,用于绘制集合的交集和并集以及其中的元素数量。这个工具可以帮助我们更好地理解不同组之间的共同和独特元素。此外,Upsetplot还提供了一些功能来探索数据的子集,如交互式筛选器和聚类等。
Upsetplot最常用的场景是分析多个数据集之间的共同元素:例如,在生物学中,我们可能需要比较几种不同基因的表达谱,以确定它们之间的重叠和唯一的部分。Upsetplot可以可视化这些基因集之间的相对大小和交集,同时仍然保留每个集合的独特元素。
除了交互式功能,Upsetplot还为自定义绘图提供了很多选项,包括修改样式、标记和颜色等。Upsetplot还可以与其他Python数据科学库(如Pandas和Matplotlib)无缝配合使用,使其易于集成到现有代码中。
我们都知道在展示几个集合的交集情况时,应该使用维恩图,非常直观。但是当集合数大于3的时候,维恩图就很难绘制了,或者说即使绘制出来,可读性也非常差,让人看得云里雾里。
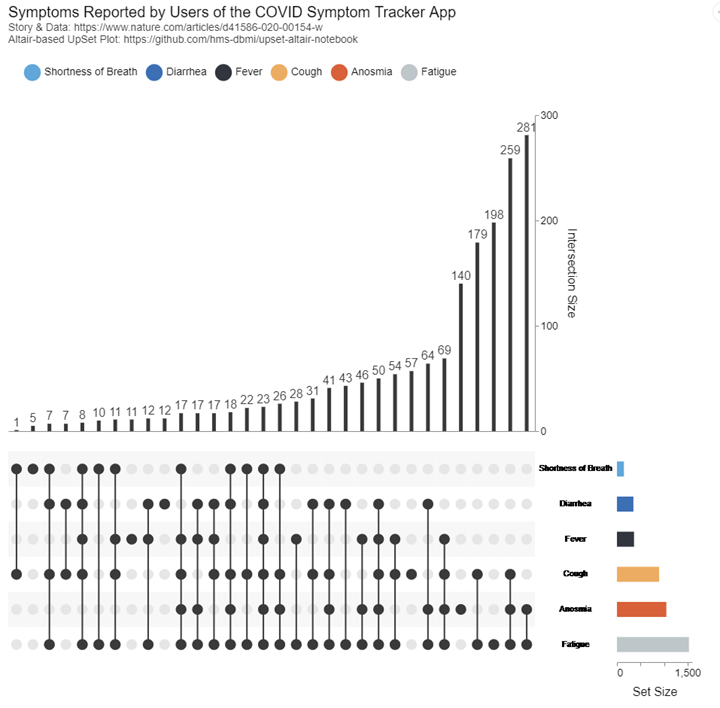
上面这张图就叫这种图就叫UpSet。UpSet是一种用于可视化多个集合的交叉情况的图形,可以看做是增强的维恩图,专门用来应付这种情况,非常适合集合数多于3个时交集情况的展示,由哈佛医学院视觉计算组于2014年的论文《UpSet: Visualization of Intersecting Sets》中提出,算是比较新的了。
UpSet由三部分组成,分别解释如下:
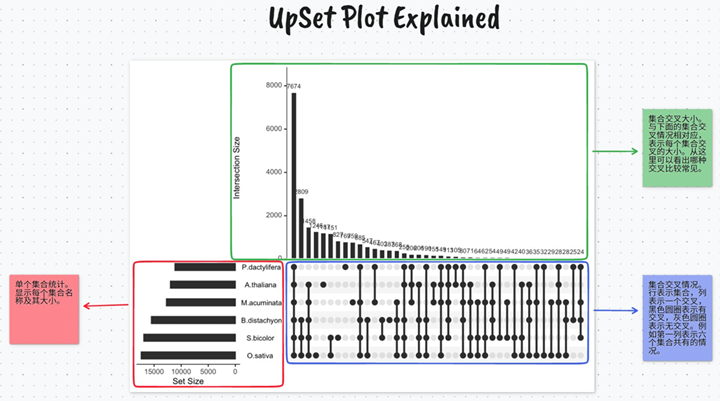
upsetplot 的主要API是 upsetplot.plot(data, fig=None, **kwargs) 方法。主要参数如下:
- data: Series 或者 pd.DataFrame ,一般来说是MultiIndex的,用来表示object的归属情况(归属于哪个集合),其值为0/1或者True/False。这个参数一般是由内置函数生成的,不用自己创建,包括 from_contents、 from_indicators、 from_memberships,可以根据你的源数据的格式选择合适的函数。具体用法下面介绍。
- fig: figure() 对象,可以指定绘制在哪个figure上。保存图时有用,如果你不传此参数,直接使用 plt.savefig() 保存,会得到一个空图。
你也可以传入其他参数,这些参数同时也是UpSet() 的参数,主要有:
- sort_by:subset(即绿色部分)的排序依据,可选的有cardinality、degree(默认值)和 None。cardinality 表示根据subset的大小排序。degree 表示subset中包含的set的数量(即蓝色部分每列黑色圆圈的数量,自由度),会根据这个数量进行排序。set,或者叫category,就是图中的红色部分。None 表示根据数据原本的出现顺序排序。
- subset_size:如何计算subset大小(即绿色部分的柱高),可选的有auto(默认值)、count 和 sum。auto 表示当 data 是DataFrame时,使用 count,除非另一个默认为 None 的参数 sum_over 被指定为非 None。count 表示用group(subset)的行数作为subset大小。sum 就表示对 data 进行求和,或者在 sum_over 指定的列上进行求和。
- min_subset_size:最小subset大小。有时候subset过多,需要用此参数来限制subset数量。
- max_subset_size:最大subset大小。有时候subset过多,需要用此参数来限制subset数量。
- min_degree:最小degree。有时候不想显示degree为0(即某列中全是灰色圆圈,没有黑色圆圈)或1的情况,可以用此参数来限制。
- max_degree:最大degree。类上。
绘图的核心就是 data 参数,因此如何准备你的数据是至关重要的。前面我们提到过生成 data 的函数主要有三个:from_contents、from_indicators 和 from_memberships,下面我们分别来看下传给这三种函数的数据是什么样子的。
from_contents
from_contents 期望的数据格式是一个 dict,key 为 categoryname(或者叫集合名称),value 为集合中包含的对象列表,这些对象必须是 int 或者 str 格式,即 value 必须是 list of int 或者 list of str。
例如下面这样:
contents = {
"set1": ["a", "b", "c"], # set1 包含 a、b、c 三个对象
"set2": ["b", "d"], # set2 包含 b、d 两个对象
"set3": ["e"] # set3 包含 e 一个对象
}
传给 from_contents 后生成的数据如下:
>>> from_contents(contents) # DataFrame
id
set1 set2 set3
True False False a
True False b
False False c
False True False d
False True e
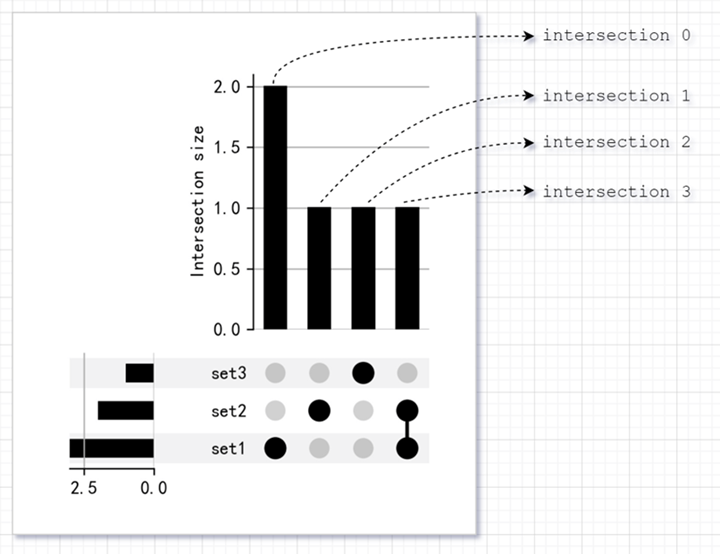
这返回的数据就是一个 MultiIndex DataFrame,将之传给 plot() 即可绘图,如下图左边:
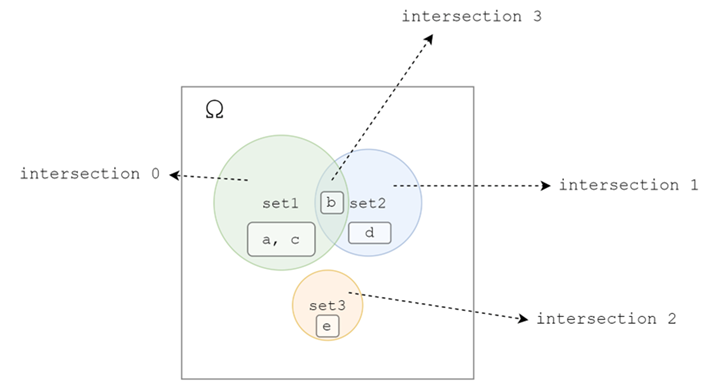
其等效的维恩图如下:
from_indicators
indicator 是“指示符”的意思,类似指示函数 indicator function 返回的是 0 和 1,from_indicators 也期望输入是一个只包含 bool 类型的数据。可以是一个 dict、一个 DataFrame,但总归是一个表格类型数据。列名是集合名称,value 是 True/False,表示某个对象属不属于该集合,所以 value list 的长度或者 DataFrame 的长度就是对象数量。
例如:
# dict 类型的输入
indicators_dict = {
"set1": [True, True, True, False, False],
"set2": [False, True, False, True, False],
"set3": [False, False, False, False, True]
}
# DataFrame 类型的输入
indicators_df = pd.DataFrame(indicators)
# set1 set2 set3
# 0 True False True
# 1 False True True
# 2 True False False
# 3 False False False
plot(from_indicators(indicators), subset_size='count')
# or plot(from_indicators(indicators_df), subset_size='count'),效果相同
结果图同上。
from_memberships
from_memberships 就比较直接了,是一个嵌套 list,每个 item 也是一个 list,表示一个对象的归属情况,里面的每个 item 是 str 类型的集合名称,即每个对象的”会员关系“ memberships,它们都是哪家的会员。
我们还是沿用上面的例子:
memberships = [
['set1'], # a 归属于 set1
['set1', 'set2'], # b 归属于 set1 和 set2
['set1'], # c 归属于 set1
['set2'], # d 归属于 set2
['set3'] # e 归属于 set3
]
传给 from_memberships 后生成的数据如下:
>>> from_memberships(memberships) # Series
set1 set2 set3
True False False 1
True False 1
False False 1
False True False 1
False True 1
Name: ones, dtype: int64
>>> plot(from_memberships(memberships), subset_size='count') # 绘图
最后的结果图和上面一致。
韦恩图在线绘制工具推荐:


