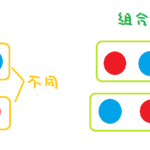
高中和大学都学过排列组合相关的内容,或许都有印象,但是相关的内容都可能不太记得了。今天发现小学四年级就开始学排列组合了。关于排列组合的相关内容较为简单,这里仅作一些梳理。 什么排列组合? 排列组合是数…
在上一篇文章大语言模型本地化部署工具Ollama,介绍了Ollama的使用,周末在家在此基础上实现了一个简答的单词卡片生成的尝试。内容比较基础。仅供学习。 项目目标 使用Python + Ollama本地生成单词卡片供学习新单词…

什么是Ollama? Ollama是一个致力于简化和优化机器学习模型使用的开源平台。它的目标是让开发者和数据科学家能够更轻松地使用和部署大型语言模型(LLM),并提供了一系列工具和框架,以支持模型的加载、管理和运行…

Postman Postman,全球闻名的API接口调试工具,有客户端版本和web网页版。Postman支持多种协议和格式,包括HTTP、HTTPS、GraphQL、REST等。Postman的优点在于它易于使用,支持多种请求类型和参数设置,可以方便地创…
enum模块是Python标准库中的一个模块,用于定义枚举类。枚举(Enumeration)是一种数据类型,它由一组具有名称的常量组成。这些常量是固定的,并且通常是与整数值相关联的。enum模块为定义和使用这些常量提供了一个…

bisect模块是Python标准库中的一个模块,用于在已排序的序列中进行高效的二分查找和插入操作。二分查找是一种用于在有序列表中快速查找元素的算法,bisect模块通过维护元素的排序状态来支持这种操作。 bisect模…

heapq模块是Python标准库中的一个模块,提供了用于操作堆(即优先队列)的函数。堆是一种特殊的树状数据结构,其中每个父节点的值都小于或等于其子节点的值(最小堆),或者每个父节点的值都大于或等于其子节点的值…

array模块是Python标准库中的一个模块,用于创建和操作高效的数组。与列表相比,array提供了一种更节省内存的方式来存储数据,尤其适用于存储大量数据或进行数值计算。array模块中的数组存储了相同类型的元素,并提…
collections模块是Python标准库中的一个模块,提供了高效的容器数据类型,这些类型扩展了Python内置的标准数据类型,如列表、字典和元组。collections模块中的数据结构不仅提高了代码的可读性,还在特定的应用场景…

numbers:数字抽象基类 numbers模块是Python标准库中的一个模块,用于定义和操作数字类型的抽象基类。它提供了对各种数值类型(如整数、浮点数、复数等)的抽象定义,使得你可以编写与数字类型相关的代码而无需考虑…
