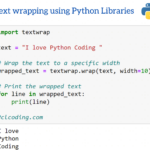
Textwrap简介 textwrap是Python标准库中的一个模块,专门用于处理和格式化文本。它提供了多种方法,可以轻松地将文本格式化为指定宽度的段落、调整缩进、处理长字符串的换行等操作。textwrap模块非常适合用于生成命…
Difflib简介 difflib是Python标准库中的一个模块,用于比较序列,尤其是字符串序列。它提供了一些类和函数,可以用于计算两个序列之间的差异,生成差异报告,以及帮助实现文本合并等功能。 产生背景 文本比较…

Python的string模块提供了一组用于处理字符串的常量和函数,方便用户进行各种字符串操作。虽然Python的字符串类型本身已经非常强大,但string模块提供了一些额外的工具和符号集,简化了特定类型的字符串操作。 常…

Python struct简介 在C语言的学习中,我们接触到了结构体。Python的struct模块用于在Python中处理C语言风格的结构化数据。它允许用户将Python中的数据打包成字节流,或者从字节流中解包数据,这对于文件读写、网络…

Dask简介 Dask是一个用于并行计算的Python库,它旨在扩展Python的生态系统,使其能够处理大规模数据计算。Dask通过提供动态任务调度系统和大数据集合(如并行数组、数据帧等),帮助开发者在多核处理器或集群上有效…

Panel简介 Panel是一个用于创建交互式仪表板和可视化应用程序的Python库。它建立在HoloViz生态系统之上,与其他可视化工具(如Bokeh、Matplotlib和Plotly)无缝集成。Panel提供了一种简单而强大的方式来将各种类型…
Holoviews简介 HoloViews是一个用于数据可视化的Python库,旨在简化复杂数据的可视化过程,并促进数据分析与探索。它提供了一种声明性的方法来描述数据与其表示方式,从而使得用户可以更快速地从数据中获取洞察。 …
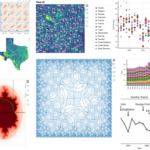
针对经纬度聚类,先前的文章中介绍过使用DBSCAN 进行聚类 的方法,我们来回顾下 DBSCAN 的一些特性: 基于密度的聚类方法,主要参数是 eps(邻域半径)和 min_samples(形成核心点所需的最小点数)。 通过扩…

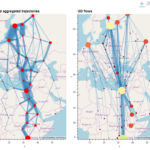
MovingPandas 是一个用于分析轨迹数据的 Python 库。它在处理和分析移动对象的时空数据方面非常强大,适用于地理信息系统(GIS)、时空数据分析和可视化等领域。它是在热门的地理数据处理库 GeoPandas 的基础上构建…
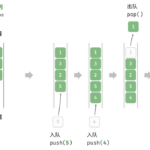
队列简介 Queue(队列)是一种常见的数据结构,遵循先进先出(FIFO,First In First Out)的原则。它类似于生活中的排队现象,即最先进入队列的元素最先被处理。 队列的基本操作 入队(Enqueue):将元…