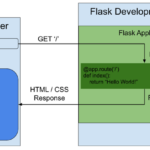
Jinja2简介 Jinja2是由 Armin Ronacher 开发的,这位开发者也是 Flask 和 Werkzeug 等著名 Python 项目的作者。Jinja2的设计受到了 Django 模板系统的影响,但在灵活性和性能方面进行了优化。它首次发布于 2008 年…

PEP 324,全称为"subprocess - New process module",是 Python 编程语言中的一项重要提案。这个提案由 Peter Astrand 在 2003 年提出,最终被包含在 Python 2.4 版本中。PEP 324 引入了 subprocess 模块,这个模块…

PEP 3107,全称为"Function Annotations",是 Python 编程语言中的一项重要提案,它在 Python 3.0 版本中被引入。这个提案由 Talin 在 2006 年提出,主要目的是为 Python 函数添加注解(annotations)功能。以下是…

PEP 484是Python编程语言中的一项重要提案,它引入了类型提示(Type Hints)的概念。这个提案由Guido van Rossum、Jukka Lehtosalo和Łukasz Langa在2014年提出,并被包含在Python 3.5版本中。以下是关于PEP 484的详…

PEP 492,全称为"Coroutines with async and await syntax",是Python编程语言中的一个重要提案。这个提案由Yury Selivanov在2015年提交,并最终成为了Python 3.5版本的一部分。PEP 492引入了async和await两个关键…

在先前的文章中,我们介绍了Linux中的管道工具,也学习了Scikit-Learn中的Pipeline。今天再来说一下如何在Python中使用管道操作,使得带来逻辑更加简单易懂。 案例展示 任务:给定一个整数数组,编写一个程序将3…
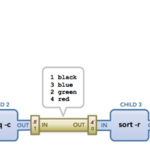
在Linux的shell命名使用中,会经常遇到管道操作符,管道操作是一个非常优秀的设计。今天我们就一起深入的学习下。 管道简介 管道,英文为pipe。这是一个我们在学习Linux命令行的时候就会引入的一个很重要的概念。它…
在软件需求、开发、测试过程中,有时候需要使用一些测试数据,针对这种情况,我们一般要么使用已有的系统数据,要么需要手动制造一些数据。在手动制造数据的过程中,可能需要花费大量精力和工作量,而使用Faker生成…

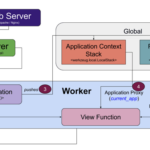
在flask中,视图函数需要知道它执行情况的请求信息(请求的url,参数,方法等)以及应用信息(应用中初始化的数据库等),才能够正确运行。最直观地做法是把这些信息封装成一个对象,作为参数传递给视图函数。但是…
在Flask中,路由是将URL请求分配到相应的处理程序的方法。每个路由可以映射到一个特定的视图(视图函数或方法)。一个WEB应用不同的路径会有不同的处理函数,路由就是根据请求的URL找到对应处理函数的过程。在执行…