在计算广告场景中,需要平衡和优化三个参与方:用户、广告主和平台的关键指标,而预估点击率 CTR(Click-through Rate)和转化率 CVR(Conversion Rate)是其中非常重要的一环,准确地预估 CTR 和 CVR 对于提高流量…
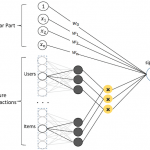
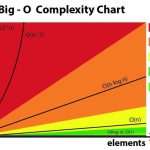
对于数据科学家程序员而言,为工作选择正确的数据结构至关重要。特别是,如果算法需要大量计算,例如训练机器学习模型的算法或处理大量数据的算法,那么确保选择合适的数据结构时要特别小心。选择正确的数据类型通…
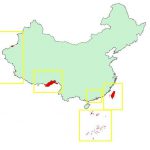
2017年国家测绘地理信息局发布的《“问题地图”清查工作指南》中列出了绘图中应避免的若干错误。下面列出了绘制中国全图时的常见注意事项: 阿克赛钦地区正确表示 藏南地区正确表示 钓鱼岛、赤尾屿位置正确 南海…
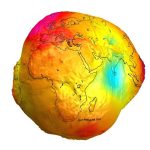
不规则的地球 地球其实不是圆的,当然也不是平的,地球虽是个球体,但是由于受到自转时的惯性及离心力的作用,他并非完美的圆形。所以地球最高点并不是珠穆朗玛峰,虽然其海拔有8848米,由于地球不是完美的球型,所…
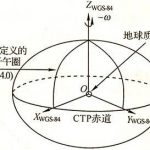
WGS-84坐标系 通常,我们所说的地球地理经纬度是 WGS-84 坐标系(World Geodetic System-1984 Coordinate System)的经纬度。WGS-84 坐标系是在 1984 年制定的全球坐标系,这个坐标系上的每一点经纬度能够精确映射…
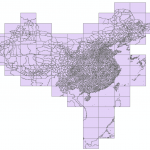
反地理查询系统中我们讲到GADM提供的数据时不符合我国的领土主张的。今天要介绍的这份数据是《1:100万全国基础地理数据库》 数据介绍 全国1:100万基础地理数据覆盖全国陆地范围和包括台湾岛、海南岛、钓鱼岛、南海…
OpenStreetMap数据简介 OpenStreetMap,简称OSM,是一个开源的世界地图,可依据开放许可协议自由使用,并且可以由人们自由的进行编辑,随着开源意识的普及,以及电子地图应用的普及,osm数据的质量和体量不断增加,…
Basemap简介 Basemap是Python可视化库Matplotlib下的一个工具包,主要功能是绘制二维地图,对于空间数据的可视化非常重要。Basemap本身不会进行任何绘图,但提供了将坐标转换为25个不同地图投影之一的功能。Matplot…
Mapbox简介 Mapbox由Eric Gunderson于2010年创立,其发展迅速,已经成为制图复兴浪潮的领导者。Mapbox专注于为地图和应用程序开发人员提供自定义底图图块,他们将自己定位为Web地图和移动应用程序的领先软件公司。…
GeoPandas简介 GeoPandas是一个开源项目,旨在让使用Python进行地理空间数据分析变得更容易。它是在Pandas数据分析库的基础上构建的,用于处理地理空间数据。GeoPandas扩展了Pandas,使得可以直接使用空间数据(地…






