GeoPandas简介
GeoPandas是一个开源项目,旨在让使用Python进行地理空间数据分析变得更容易。它是在Pandas数据分析库的基础上构建的,用于处理地理空间数据。GeoPandas扩展了Pandas,使得可以直接使用空间数据(地理数据)。具体来说,GeoPandas允许对地理数据类型进行高效的操作,并提供了许多用于处理这些数据类型的方法和功能。
主要特性
- 简便的数据结构:GeoPandas提供了两个主要的数据结构——GeoSeries和GeoDataFrame。这些数据结构继承自Pandas中的Series和DataFrame,但增加了空间操作的功能。
- GeoSeries:可以视为一个向量,其中每个元素都是一个几何对象(如点、线、多边形)。
- GeoDataFrame:则是一个表格,其中每一行表示一个地理空间数据对象,一列或多列存储几何对象,其他列则存储与之相关的属性数据。
- 空间操作:GeoPandas依赖于Shapely库来进行几何操作,如计算面积、长度、距离、合并图形等。
- 几何操作:包括计算交集、并集、差集和对称差等。
- 空间关系:如测试对象之间的相交、触碰、包含关系等。
- 空间索引:为加速空间查询,GeoPandas支持空间索引,类似于Pandas的索引功能。
- 投影与坐标变换:GeoPandas可以读取和变换坐标系,支持对GeoDataFrame中的几何数据应用不同的投影。
- 文件读写:GeoPandas可以使用Fiona库读写多种格式的空间数据文件,如GeoJSON、ESRI Shapefile、KML等。
- 坐标参考系统(CRS):管理和转换地理坐标系统,基于PROJ库。
- 可视化:GeoPandas也提供了数据可视化的功能,基于matplotlib库,可以快速地生成地图和其它的图表。
GeoSeries与GeoDataFrame
GeoSeries
GeoSeries是包含集合图形的序列,每个元素可以是单个形状或多个形状。Geopandas有三种基本的几何对象:
- 点:Points/Multi-Points
- 线:Lines/Multi-Lines
- 面:Polygons/Multi-Polygons
GeoSeries中的所有条目不必具有相同的几何类型,如果是不同类型,部分操作可能会失败。
Geoseries类实现了Shapely对象的几乎所有属性和方法。在使用GeoSeries时,它将应用于序列中所有几何图形的每一个元素。二元操作可以在两个GeoSeries对象之间进行,这种情况下二元操作将应用于每一个元素。这两个序列将按匹配的索引进行对于操作。二元操作也可以应用于单个几何,此时二元操作将对该几何序列的每个元素进行。在以上两种情况下,操作将会返回Series或者GeoSeries对象。
Attributes属性:
- area:返回一个Series,它包含GeoSeries中每个几何的面积。
- bounds:返回一个DataFrame,它包含每个几何的边界,用列值minx,miny,maxx,maxy来表示。
- total_bounds:返回一个元组,包含整个series边界的minx,miny,maxx,maxy值。包含在序列中的几何体的边界。
- geom_type:返回一个字符串的Series,字符串指定每个对象的几何类型。
- is_valid:返回一个布尔型的Series,如果几何体是有效的,该值就为True。
Basic Methods基本方法:
- distance():返回一个Series,它包含与其他GeoSeries对象(每个元素)或几何对象的最小距离。
- centroid:返回表示几何重心点的一个GeoSeries。
- representative_point():返回所有点的一个GeoSeries(经简易计算),这些点必须保证在每个几何的内部。这个点不等于重心点。
- to_crs():转换GeoSeries中的几何图形到不同的坐标参考系统。当前GeoSeries的crs属性必须被设置。crs属性需要被指定以用于输出,或是用字典形式或是用EPSG编码方式。
- plot():进行GeoSeries中几何图形的绘制。
Relationship Tests关系测试:
- geom_almost_equals():返回一个布尔型的Series对象,如果在指定的小数位精度下,每个对象所有点与其他对象大致相等,该值就为True。
- contains():返回一个布尔型的Series,如果每个对象的内部包含其他对象的内部和边界,并且它们的边界不相接,该值为True。
- intersects():返回一个布尔型的Series,如果每个对象的边界和内部以其它任何形式与其他对象相交,该值为True。
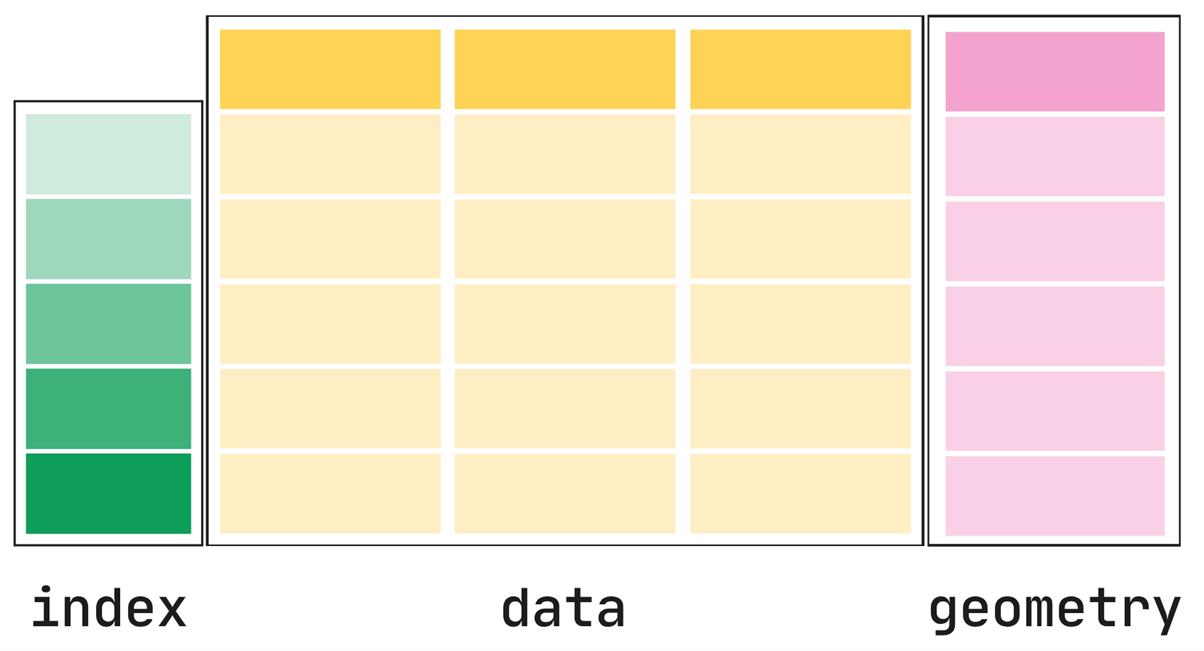
GeoDataFrame
GeoDataFrame是一个列表数据结构,它包含一个叫做包含geometry的列,这个geometry包含一个GeoSeries。
GeoPandas的安装与使用
GeoPandas的安装
GeoPandas是一个开源项目,它扩展了Pandas库以支持地理空间数据处理。安装GeoPandas通常涉及几个步骤,因为GeoPandas依赖于一些其他的库,这些库可能需要额外的系统依赖项。
- Pandas:用于数据操作的基础库。
- Shapely:用于处理几何对象的库。
- rasterio:用于读写地理空间raster数据(如卫星图像)的库。
- pyproj:用于坐标系统转换的库。
- matplotlib和cartopy:用于地理空间数据的可视化。
以下是安装GeoPandas的几种常见方法:
使用pip安装
对于大多数用户来说,最简单的方法是通过pip安装GeoPandas。在命令行中运行以下命令:
pip install geopandas
这通常会安装GeoPandas及其大多数依赖项。然而,某些依赖项(如GDAL)可能需要系统级别的库。如果遇到问题,请尝试以下方法。
使用conda安装
如果你使用Conda管理你的Python环境(例如,通过Miniconda或Anaconda),你可以使用Conda-forge通道来安装GeoPandas和它的所有依赖项。这通常更容易处理复杂的依赖关系。
conda install -c conda-forge geopandas
安装依赖项
如果直接使用pip安装GeoPandas遇到问题,尤其是与GDAL相关的问题,你可能需要先手动安装GDAL。GDAL是一个用于地理空间数据转换的库,GeoPandas依赖于它来处理空间数据。
- 在Ubuntu/Debian上安装GDAL:sudo apt-get install libgdal-dev
- 在macOS上安装GDAL:brew install gdal
- 在Windows上安装GDAL:在Windows上,你可能需要从GDAL官方网站下载并安装预编译的二进制文件,或者通过Conda安装(如上所述)。
验证安装
安装完成后,你可以通过以下方式验证GeoPandas是否已成功安装:
python -c "import geopandas; print(geopandas.__version__)"
GeoPandas的使用
数据的读写
使用 read_file() 可以导入任何的空间矢量数据,主要有 shp 和 GeoJson 两种。
geopandas.read_file(filename, bbox=None, mask=None, rows=None, **kwargs)
- filename 文件路径
- bbox 按照给定的条件筛选几何要素,仅加载与边框相交的数据
- mask 过滤与给定条件相交要素
- rows 要加载的行数
- ignore_geometry=Ture 返回 dataframe
- ignore_fields[],选择不加载这几列
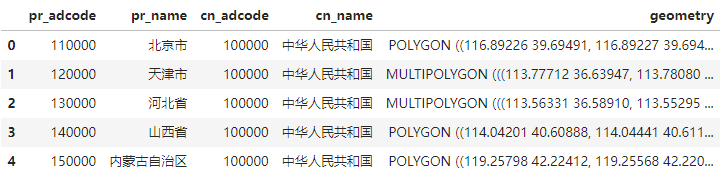
GeoPandas 读取 .shp 文件
import geopandas as gpd
import matplotlib.pyplot as plt
# shp 必须与 shx 同处于一个文件夹内
# 数据来源:https://github.com/GaryBikini/ChinaAdminDivisonSHP
shapefile_path = './Province/province.shp'
gdf = gpd.read_file(shapefile_path)
print(gdf.head())
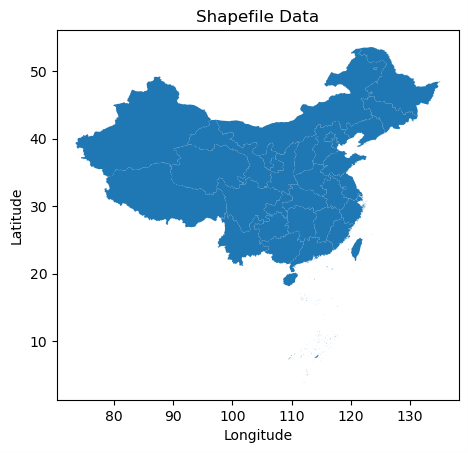
gdf.plot()
plt.title('Shapefile Data')
plt.xlabel('Longitude')
plt.ylabel('Latitude')
plt.show()
输出内容:
GeoPandas 读取 geojson 文件
import geopandas as gpd
import matplotlib.pyplot as plt
# 数据来源:天地图
file_path = './中国_省.geojson'
gdf = gpd.read_file(file_path)
print(gdf.head())
gdf.plot()
plt.title('Shapefile Data')
plt.xlabel('Longitude')
plt.ylabel('Latitude')
plt.show()
输出内容:
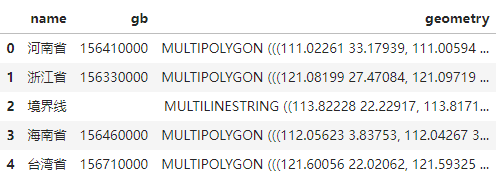
GeoPandas 读取自带数据集
GeoPandas 自带一些示例数据集,方便用户快速上手和测试功能。这些数据集包括地理边界、世界各国的几何信息等。从 GeoPandas 1.0 这些数据已经被移动到单独的geodatasets 包中。
geodatasets 包通过 Bunch 对象组织和管理数据集。这些 Bunch 对象将相关的数据集分组,使得访问和使用这些数据集更加便捷。
- geoda Bunch 包含与 GeoDa 软件(空间数据分析工具)相关的数据集。这些数据集通常用于空间统计和地理分析。
- ny Bunch 包含与纽约市相关的数据集,如纽约市的边界、区划和地理信息。这些数据集适合城市规划、交通分析等应用。
- eea Bunch 包含与欧洲环境署(EEA)相关的数据集,这些数据集通常用于环境、生态和地理分析。
- abs Bunch 包含与澳大利亚统计局(ABS)相关的数据集,这些数据集适用于人口普查、经济和社会数据的地理分析。
- naturalearth Bunch 包含来自 NaturalEarth 的数据集,这是一个免费的地理数据集,提供广泛的地理信息,如国家边界、城市位置、河流等。
import geopandas as gpd
import geodatasets
import matplotlib.pyplot as plt
world_path = geodatasets.get_path('naturalearth.land')
gdf_world = gpd.read_file(world_path)
gdf_world.plot()

GeoPandas 读取 DataFrame 数据
将普通的 DataFrame 转换为 GeoDataFrame 是使用 GeoPandas 进行地理空间分析的一个重要步骤。通常,您会有一列包含地理空间信息(例如,经纬度)的 DataFrame,然后将其转换为 GeoDataFrame。
import pandas as pd
import geopandas as gpd
# 创建普通的 DataFrame
data = {
'city': ['New York', 'Los Angeles', 'Chicago'],
'latitude': [40.7128, 34.0522, 41.8781],
'longitude': [-74.0060, -118.2437, -87.6298]
}
df = pd.DataFrame(data)
# 使用 points_from_xy 生成几何点
geometry = gpd.points_from_xy(df['longitude'], df['latitude'])
# 创建 GeoDataFrame
gdf = gpd.GeoDataFrame(df, geometry=geometry)
# 设置坐标参考系统(CRS)
gdf.set_crs(epsg=4326, inplace=True)
print(gdf)
geopandas.points_from_xy 是一个非常方便的函数,用于从包含经纬度信息的列生成几何点。它简化了将普通的 DataFrame 转换为 GeoDataFrame 的过程。
GeoPandas 导出文件
另外也可以将 GeoDataFrame 导出为 ESRI shapefile、GeoJson、GeoPackage 等地理空间文件类型:
world.to_file("countries.shp")
world.to_file("countries.geojson", driver='GeoJSON')
world.to_file("package.gpkg", layer='countries', driver="GPKG")
数据可视化
GeoPandas 基于 matplotlib 库封装高级接口用于制作地图,可以生成多种类型的地理图,如地图、多边形图、散点图等。GeoSeries 或 GeoDataFrame 对象都提供了 plot 函数以进行对象可视化。与 GeoSeries 对象相比,GeoDataFrame 对象提供的 plot 函数在参数上更为复杂,也更为常用。
GeoDataFrame.plot() 方法有许多参数可以用来定制绘图。以下是一些常用的参数:
- column: str, np.array, 或 Series(默认值为 None)要绘制的数据框列的名称,np.array 或 pd.Series。如果使用 np.array 或 pd.Series,则它们的长度必须与数据框相同。这些值用于为图形着色。如果也设置了 color,则忽略此参数。
- kind: str 要生成的图形类型。默认是创建地图(“geo”)。其他支持的 pandas 图形类型:
- ‘line’:折线图
- ‘bar’:垂直条形图
- ‘barh’:水平条形图
- ‘hist’:直方图
- ‘box’:箱线图
- ‘kde’:核密度估计图
- ‘density’:同‘kde’
- ‘area’:面积图
- ‘pie’:饼图
- ‘scatter’:散点图
- ‘hexbin’:六边形箱图
- cmap: str(默认值为 None)由 Matplotlib 认可的颜色映射名称。
- color: str, np.array, 或 Series(默认值为 None)如果指定,所有对象将被均匀着色。
- ax: matplotlib.pyplot.Artist(默认值为 None)用于绘制图形的轴线。
- cax: matplotlib.pyplot.Artist(默认值为 None)用于绘制颜色映射图例的轴线。
- categorical: bool(默认值为 False)如果为 False,颜色映射将反映所绘制列的数值。对于非数值列,此参数将自动设置为 True。
- legend: bool(默认值为 False)绘制图例。如果未指定列或已指定颜色则会忽略。
- scheme: str(默认值为 None)分级法名称(需要 mapclassify)。在底层将使用 MapClassifier 对象。支持所有 mapclassify 提供的分级法(例如‘BoxPlot’,‘EqualInterval’,‘FisherJenks’,‘FisherJenksSampled’,‘HeadTailBreaks’,‘JenksCaspall’,‘JenksCaspallForced’,‘JenksCaspallSampled’,‘MaxP’,‘MaximumBreaks’,‘NaturalBreaks’,‘Quantiles’,‘Percentiles’,‘StdMean’,‘UserDefined’)。可以通过 classification_kwds 传递参数。
- k: int(默认值为 5)类别的数量(如果 scheme 为 None 则忽略)。
- vmin: None 或 float(默认值为 None)颜色映射的最小值。如果为 None,则使用要绘制列的最小数据值。
- vmax: None 或 float(默认值为 None)颜色映射的最大值。如果为 None,则使用要绘制列的最大数据值。
- markersize: str, float 或序列(默认值为 None)仅适用于数据框中的点几何。如果是 str,将使用数据框中 markersize 指定的列的值来设置标记大小。否则,可以是应用于所有点的值,或者与点数相同长度的序列。
- figsize: 整数元组(默认值为 None)生成的 Matplotlib 图形的尺寸。如果显式给出 axes 参数,则忽略 figsize。
- legend_kwds: dict(默认值为 None)传递给 pyplot.legend() 或 matplotlib.pyplot.colorbar() 的关键字参数。当指定 scheme 时接受的其他关键字:
- fmt: string 用于图例中类别边界的格式规范。例如,不需要小数点时:{“fmt”:”{:.0f}”}。
- labels: 类似列表的对象用于覆盖自动生成标签的图例标签列表。需要有与类别数量(k)相同的元素数量。
- interval: boolean(默认值为 False)控制 mapclassify 图例括号的选项。如果为 True,图例中将显示开闭区间括号。
- categories: 类似列表的对象用于分类图的有序列表对象。
- classification_kwds: dict(默认值为 None)传递给 mapclassify 的关键字参数。
- missing_kwds: dict(默认值为 None)指定颜色选项(作为 style_kwds)的关键字参数,传递给具有缺失值的几何图形,以覆盖其他样式关键字参数。如果为 None,则不绘制具有缺失值的几何图形。
- aspect: ‘auto’,‘equal’,None 或 float(默认值为‘auto’)设置轴的纵横比。如果为‘auto’,地图图的默认纵横比为‘equal’;但如果数据未投影(坐标为经纬度),则默认纵横比为 1/cos(df_y*pi/180),其中 df_y 为 GeoDataFrame 中点的 y 坐标(边界框 y 范围的中值),这样经纬度的正方形在图中间看起来是正方形。这意味着等矩形投影。如果为 None,轴的纵横比不会改变。也可以手动设置(浮点数),作为 y 单位与 x 单位的比例。
- autolim: bool(默认值为 True)更新轴数据限制以包含新几何图形。
- style_kwds: dict 传递给实际绘图函数的样式选项,例如 edgecolor, facecolor, linewidth, markersize, alpha。
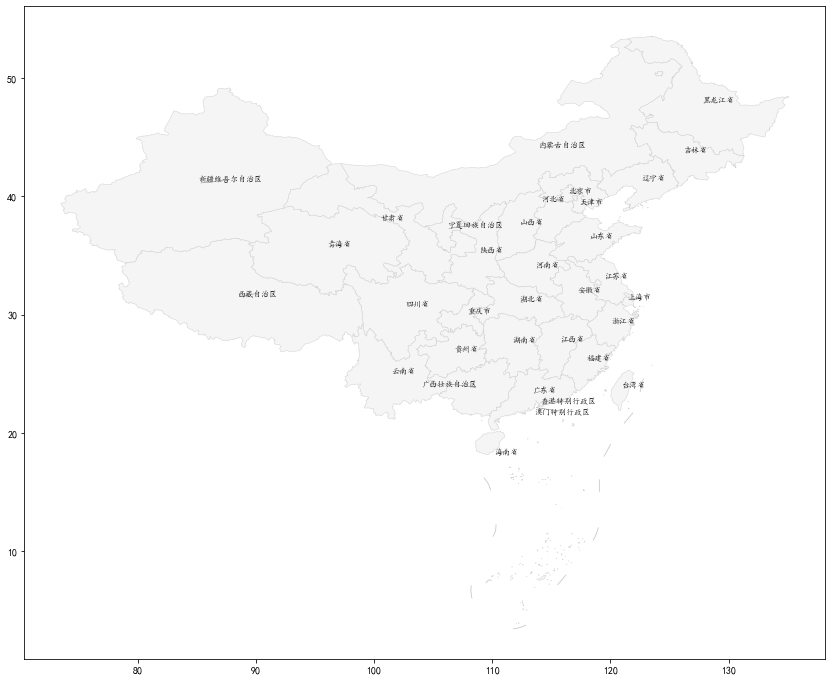
GeoPandas 区域添加文字标签
当使用 GeoPandas 绘制区域数据时,有时期望给每天区域添加文字标签。GeoPandas 本身不提供此功能。主要问题是无法确定文字标签应该添加到哪里。幸运的是 GeoPandas 提供了2 个方法可以帮助我们来的文字标签的位置:
- Centroid:返回每个多边形的中心点
- representativepoint():返回多边形内的一个点,它保证在多边形的边界内,但不一定在中心
示例代码:
import geopandas as gpd
import adjustText as aT #https://github.com/Phlya/adjustText
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['KaiTi'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
china = gpd.read_file('https://geo.datav.aliyun.com/areas_v3/bound/100000_full.json').to_crs('EPSG:4573')
china["center"] = china["geometry"].centroid
#china["rep"] = china["geometry"].representative_point()
china_points = china.copy()
china_points.set_geometry("center", inplace=True)
#china_points.set_geometry("rep", inplace=True)
ax = china.plot(figsize=(15,12), color="whitesmoke", edgecolor="lightgrey", linewidth=0.5)
texts = []
for x, y, label in zip(china_points.geometry.x, china_points.geometry.y, china_points["name"]):
texts.append(plt.text(x, y, label, fontsize=8))
aT.adjust_text(texts, force_points=0.3, force_text=0.8, expand_points=(1,1), expand_text=(1,1), arrowprops=dict(arrowstyle="-", color='grey', lw=0.5))
plt.show()
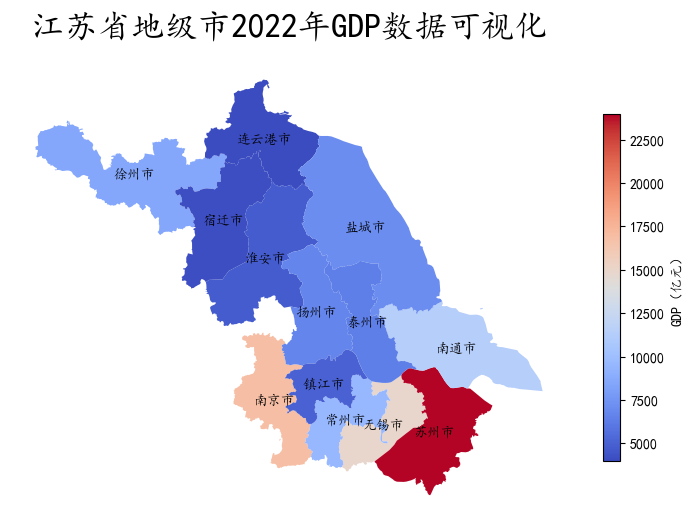
数据可视化实战:江苏2022年地级市GDP
import geopandas as gpd
import matplotlib.pyplot as plt
import pandas as pd
plt.rcParams['font.sans-serif'] = ['KaiTi'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
gdp = pd.read_csv("jiangsu-gdp-2022.csv")
gdp.head()
#读取江苏地图数据,数据来自DataV.GeoAtlas,将其投影到EPSG:4573
data = gpd.read_file('https://geo.datav.aliyun.com/areas_v3/bound/320000_full.json').to_crs('EPSG:4573')
#合并数据
data = data.join(gdp.set_index('地级市')["2022年GDP(亿元)"], on='name')
#修改列名
data.rename(columns={'2022年GDP(亿元)':'GDP'}, inplace=True)
data.head()
fig, ax = plt.subplots(figsize=(9,9))
#legend_kwds设置matplotlib的legend参数
data.plot(ax=ax, column='GDP', cmap='coolwarm', legend=True, legend_kwds={'label':"GDP(亿元)", 'shrink':0.5})
ax.axis('off')
ax.set_title('江苏省地级市2022年GDP数据可视化', fontsize=24)
for index in data.index:
x = data.iloc[index].geometry.centroid.x
y = data.iloc[index].geometry.centroid.y
name = data.iloc[index]["name"]
ax.text(x, y, name, ha="center", va="center")
plt.show()
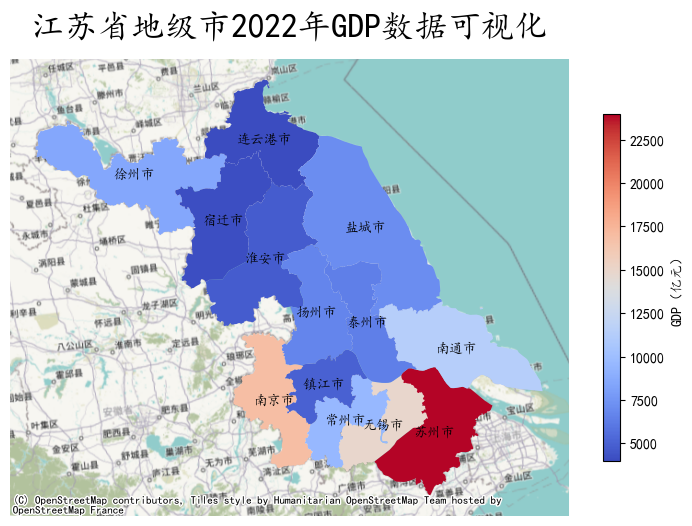
背景地图叠加
contextily是一个Python库,它提供了一种简单的方法将背景地图(通常是Web瓦片地图,如OpenStreetMap、Stamen Maps、Mapbox等)添加到地理空间数据可视化中。使用contextily库可以使地理空间数据可视化更加生动、直观,同时可以提供更多的地理信息。contextily支持使用WGS84 (EPSG:4326)和Spheric Mercator (EPSG:3857)坐标系,在Web地图应用程序中,一般使用EPSG:3857(以米为单位)来显示瓦片地图,并使用EPSG:4326(以经纬度为单位)来标记瓦片地图上的位置。
示例代码:
data = gpd.read_file('https://geo.datav.aliyun.com/areas_v3/bound/320000_full.json').to_crs('EPSG:4573')
#合并数据
data = data.join(gdp.set_index('地级市')["2022年GDP(亿元)"], on='name')
#修改列名
data.rename(columns={'2022年GDP(亿元)':'GDP'}, inplace=True)
data.head()
fig, ax = plt.subplots(figsize=(9,9))
#legend_kwds设置matplotlib的legend参数
data.plot(ax=ax, column='GDP', cmap='coolwarm', legend=True, legend_kwds={'label':"GDP(亿元)", 'shrink':0.5})
ax.axis('off')
ax.set_title('江苏省地级市2022年GDP数据可视化', fontsize=24)
for index in data.index:
x = data.iloc[index].geometry.centroid.x
y = data.iloc[index].geometry.centroid.y
name = data.iloc[index]["name"]
ax.text(x, y, name, ha="center", va="center")
cx.add_basemap(ax, crs='EPSG:4573')
plt.show()
contextily内置了大量的瓦片服务提供商:
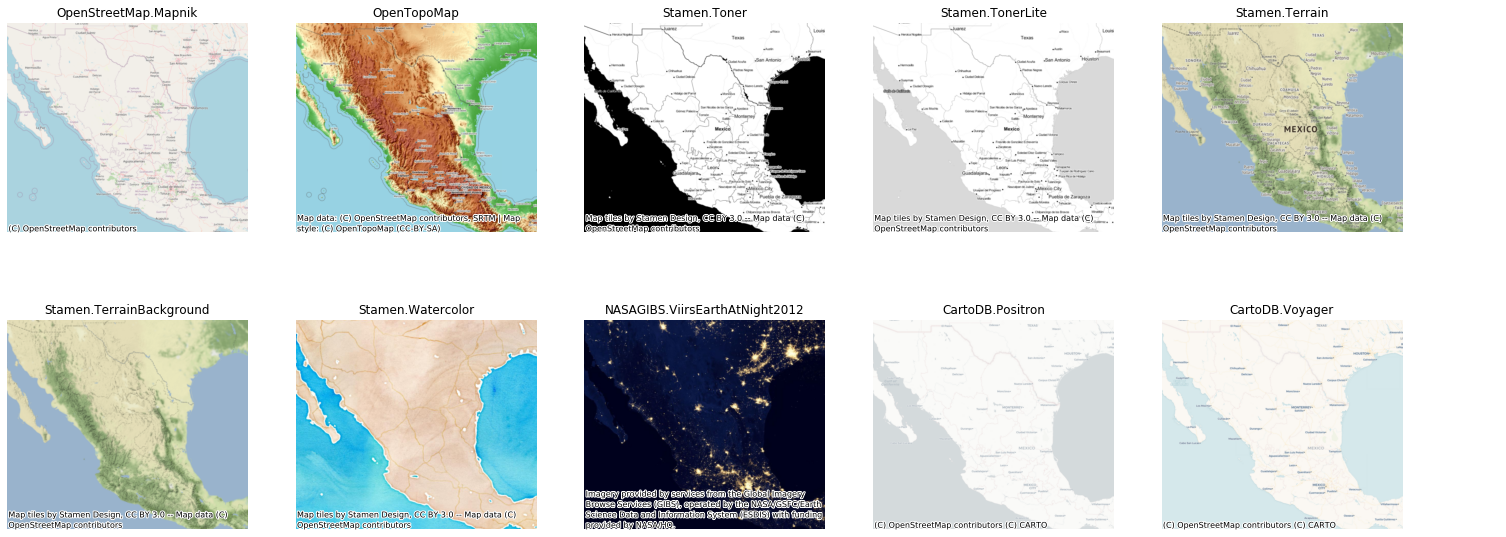
使用示例:
fig, ax = plt.subplots(figsize=(9,9))
#legend_kwds设置matplotlib的legend参数
data.plot(ax=ax, column='GDP', cmap='coolwarm', legend=True, legend_kwds={'label':"GDP(亿元)", 'shrink':0.5})
ax.axis('off')
ax.set_title('江苏省地级市2022年GDP数据可视化', fontsize=24)
for index in data.index:
x = data.iloc[index].geometry.centroid.x
y = data.iloc[index].geometry.centroid.y
name = data.iloc[index]["name"]
ax.text(x, y, name, ha="center", va="center")
cx.add_basemap(ax, crs='EPSG:4573', source=cx.providers.CartoDB.Voyager)
plt.show()
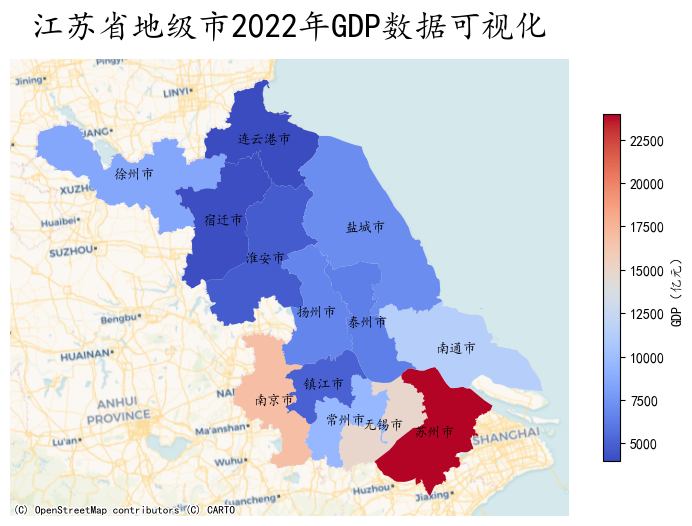
由于网络问题,不分地图服务无法使用,可以调整为国内的瓦片地图服务,示例如下:
fig, ax = plt.subplots(figsize=(9,9))
#legend_kwds设置matplotlib的legend参数
data.plot(ax=ax, column='GDP', cmap='coolwarm', legend=True, legend_kwds={'label':"GDP(亿元)", 'shrink':0.5})
ax.axis('off')
ax.set_title('江苏省地级市2022年GDP数据可视化', fontsize=24)
for index in data.index:
x = data.iloc[index].geometry.centroid.x
y = data.iloc[index].geometry.centroid.y
name = data.iloc[index]["name"]
ax.text(x, y, name, ha="center", va="center")
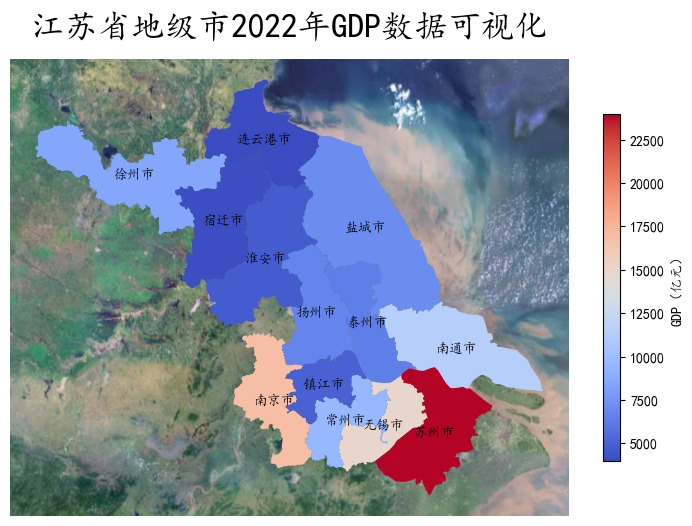
cx.add_basemap(ax, crs='EPSG:4573', source='http://webst01.is.autonavi.com/appmaptile?style=6&x={x}&y={y}&z={z}')
plt.show()
参考链接:


