《软件随想录》简介 《软件随想录》(Joel on Software)是乔尔·斯波尔斯基(Joel Spolsky)的经典文集,汇集了他对软件开发、团队管理、技术选型等领域的深刻思考。这本书的价值不仅在于其内容本身,更在于它启发…

选择域名是创业中至关重要的一步,它不仅是你在线业务的"门牌号",更是品牌形象的基础。优质的域名能提升信任感、易传播性。 以下是交了很多学费后整理的经验: 核心原则 品牌优先: 紧密关联:…

项目简介:针对一标识的文本信息,抽取文本中的关键词,最后以词云的方式暂时关键词。数据集更有2列:text、flag。其中text是文本内容, flag样本标识(0或1)。 步骤一:对文本内容进行分词处理 这里采用的是结…

《乌合之众》(The Crowd: A Study of the Popular Mind)是法国社会心理学家古斯塔夫·勒庞(Gustave Le Bon)于1895年出版的经典著作,主要探讨群体心理的特征及其对社会和历史的影响。 主要内容概述 群体的…

无意间找到一份先前梳理的一份机票前端系统可用性测试的文档,抽时间结合Deepseek在此基础上进行了项目扩展与补充。可能还有改进空间,欢迎提出改进建议。 机票预订可用性测试 测试目标 验证用户能否高…

“Lies, damned lies, and statistics” 是一句广为人知的谚语,常被用来批判对统计数据的滥用或误导性使用。 出处与背景 起源争议:这句话的确切出处尚无定论,但普遍认为它源于19世纪的英国政坛。常被…

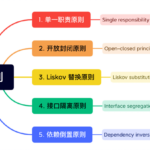
SOLID原则是一组面向对象编程中的设计原则,旨在提高软件设计的可维护性、灵活性和扩展性。这些原则由罗伯特·C·马丁(Robert C. Martin)提出,是软件开发中广泛认可的最佳实践。SOLID是五个原则的首字母缩写,每个…
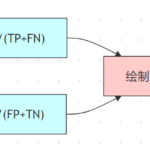
先前按照Scikit-Learn的文档整理了一份评估指标,回头看下梳理的非常的技术化,整理完有种自己都不太想看的感觉。今天抽时间再做一次重新的梳理。 分类任务评估指标 混淆矩阵(Confusion Matrix) 分类任务的基…
自2022年11月推出以来,ChatGPT 一直备受关注。其根据输入内容和上下文提供类似于人类的回应能力,给一些重视原创内容的领域带来了困扰,包括教育、内容营销、出版、新闻和法律等领域。他们最大的问题是“我们如何区…

ColumnTransformer 是 scikit-learn 中用于对数据的不同列应用不同预处理步骤的工具,特别适用于处理包含混合类型特征(如数值型、分类型、文本型)的数据集。 ColumnTransformer核心功能与使用场景 核心功能…





