超参数调优是机器学习模型开发的核心步骤,直接影响模型性能。scikit-learn 提供多种工具帮助高效优化参数。 GridSearchCV Scikit-Learn 的 GridSearchCV 是一种通过穷举参数组合并交叉验证评估性能的超参数…

类别不平衡是分类任务中常见的问题,即某些类别的样本数量显著少于其他类别。除了前面介绍的imbalanced-learn库以外,还能使用class_weight参数进行处理。 class_weight与imbalanced-learn的对比 核心定义与…

CMMD简介 CMMD(Cross-Metric Multidimensional Diagnosis)是一种面向 复杂系统多源异构数据 的根因定位框架,其核心思想是通过 跨指标关联性分析 和 多维时空模式挖掘,在 无监督或半监督 场景下快速定位故障根…
imbalanced-learn(通常简称为 imblearn)是一个专门用于处理类别不平衡数据的 Python 库。它与 Scikit-learn 兼容,提供了多种方法来解决分类任务中类别样本数量差异过大的问题。 为什么需要 imbalanced-lear…

什么是大数据杀熟? 大数据杀熟(Big Data Price Discrimination)是指企业利用用户的历史行为数据、消费习惯、设备信息、地理位置等个人隐私数据,通过算法分析对不同用户实施差异化定价的行为。其核心在于利用数…

RiskLoc简介 RiskLoc 是一种通过 量化多维风险权重 和 动态概率融合 实现故障根因定位的方法,其核心思想是将系统异常视为多个潜在因素(如硬件、软件、网络等)的加权风险组合,通过概率模型计算各因素成为根因的…
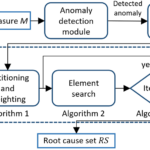
AutoRoot 简介 AutoRoot 是一种基于 自动化机器学习(AutoML) 和 因果推理 的多维故障根因定位方案,旨在通过智能化分析高维监控数据(如指标、日志、链路追踪等),快速、精准地识别复杂系统中的故障根源。其核…
Scikit-Learn 提供了多种特征选择方法,主要分为以下几类,结合具体场景和算法特性进行选择: 过滤法 (Filter Methods) 基于统计指标评估特征重要性,独立于模型。 方差阈值 (Variance Threshold) 方差阈值…

JSON在开发场景的应用 JSON(JavaScript Object Notation)在开发中因其轻量级、易读、灵活的特性,已成为处理结构化或半结构化数据的首选格式。 前后端数据交互 场景:客户端(Web/App)与服务器之间的…
Squeeze简介 Squeeze是一种面向多维监控数据的通用根因定位算法,旨在从海量维度组合中快速、鲁棒地识别导致KPI(关键性能指标)异常的根本原因。其核心思想是通过分析多维指标的异常分布差异,逐步缩小可能触发异…






