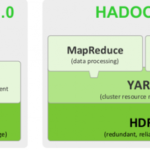
这篇一开始文章整理于2014年,在此的7~8年时间里,Hadoop已经发生了很多变化,但最为核心的内容并没有变化那么多,当时的文章还是有一定的参考意义。再次重新做下整理。 Hadoop的概要介绍 Hadoop,是一个分布式系统…
Google,作为全球最大的搜索引擎公司,其伟大之处不仅在于建立了一个强大的搜索引擎,还在于它创造了3项革命性的技术,即:GFS、MapReduce和BigTable。作为Google早期三驾马车,这三项革命性的技术不仅在大数据领域…

Bigtable是2005年谷歌的论文:《Bigtable: A Distributed Storage System for Structured Data》中介绍的一种分布式存储系统,后来被Hadoop社区实现为HBase。读懂这篇论文,那么理解HBase也就非常容易了。 摘要(…
GFS系统简介 Google文件系统(Google File System,缩写为GFS或Google FS),一种由Google公司开发专有分布式文件系统。 它与传统文件系统的的区别在于: 分布式 - 提供很高的横向扩展性 使用大量廉价的普通…
“越狱”在评估有 Appstore 时就已经存在,当时很多人越狱的目的是为了安装收费的应用或游戏。随着 Appstore 应用的丰富及免费 APP 的增多,已经很少有用户为了牺牲手机的安全性来的进行越狱了。另外一方面,越狱的设…

图数据库最大的优点是通过节点和关联的数据模型去快速解决复杂的关系问题。它非常善于处理大量的、复杂的、关联的、多变的网状数据,而且具备奇高的效率。由于图数据库拥有独一无二的特性,因此它非常适合在社交网…
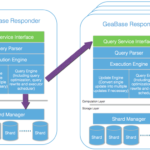
图计算简介 图计算中的图英文是 Graph,用英文完整的表达就是 Graph Computing。图计算是研究客观世界当中的任何事物和事物之间的关系,对其进行完整的刻划、计算和分析的一门技术。简单概括一下,就是,图计算是人…
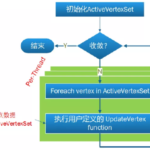
金刚经的开头部分(法会因由)有这样一句话:“尔时世尊食时,着衣持钵,入舍卫大城乞食。于其城中,次第乞已,还至本处。”,其中印象比较深的是“次第乞已,还至本处。”这八字。 次第乞已 佛经中的次第乞已 …

类似淘口令的还有支付宝的“吱口令”。口令码分享除了淘宝系之外的应用并不广泛,一是其本身就需要一套完整的口令产生与识别系统,同时还涉及加密等,本身是较为复杂的,开发难度大;二是其限制了受众必须进入相同的A…
什么是TGI 对于TGI指数,百科是这样解释的——TGI指数,全称Target Group Index,可以反映目标群体在特定研究范围内强势或者弱势。 TGI指数计算公式=目标群体中具有某一特征的群体所占比例/总体中具有相同特征的群…






