图数据库最大的优点是通过节点和关联的数据模型去快速解决复杂的关系问题。它非常善于处理大量的、复杂的、关联的、多变的网状数据,而且具备奇高的效率。由于图数据库拥有独一无二的特性,因此它非常适合在社交网络、实时推荐、银行交易环路、金融征信系统等领域应用。蚂蚁金服在2015年成立了专门研发图数据库的技术团队,在仅仅3年多时间里,成功研发出具有高性能、高可用性、扩展能力强和极佳移植性的GeaBase(Graph Exploration and Analytics Database)。目前,GeaBase不仅广泛应用于蚂蚁金服的生态体系内,而且已经技术开放(目前还未开源),正与多家银行等企业开展合作。
GeaBase简介
GeaBase是蚂蚁金服自主研发的一款简单易用的高性能分布式实时图数据库。通过特有的数据组织方式和分布式并行计算算法,GeaBase能够快速高效地查询数据的关系信息,从而满足超大规模复杂关系网络在金融领域中的各类应用场景。在GeaBase中,您可以进行在线数据建模,通过多种方式灵活导入数据(通过ODPS在线导入数据和以上传文件的方式离线导入数据),并进行可视化查询测试。GeaBase是一个新式的分布式图数据库,能实时的存储和分析大规模图结构数据。它包含一个新奇的更新架构,叫做”更新中心UC”,一个新的适合图分析和遍历的图查询语言。它的查询性能是开源Titan的182倍,吞吐也高达22倍。
产品优势
GeaBase是一款针对巨型复杂关系网络和超大规模实时更新数据的简单易用、高性能的图数据库产品。相比市场上的同类产品,GeaBase具有以下优势:
- 高易用性。GeaBase系统部署非常简便,数据库维护人员能快速完成整个图数据库服务的部署。另外,GeaBase提供一套简单易用的查询语言。目前,大多数图计算框架需要通过SDK写代码的方式来使用,一旦业务逻辑发生变化,您就需要改写代码,重新部署,不仅过程繁琐,光调试代码就会耗费大量精力。GeaBase所采用的查询语言正是蚂蚁金服金融科技借鉴了各种查询语言,自主研发的一套适合蚂蚁业务场景的语言,让图数据的操作更加简便。
- 高性能。支持超大图(万亿条边)的存储和实时查询响应。采用”计算寻找数据”的思路异步执行计算和数据读取,对典型查询的平均响应时间在毫秒级别。
- 高稳定性和可用性。GeaBase采用双系统备份,多机房容灾,并应用基于Apache ZooKeeper的高可用性机制,保证了高稳定性和可用性。
- 高扩展性。GeaBase定位于分布式图数据库,很容易进行功能扩展、水平扩展,支持实时、增量、批量更新数据。
- 实时更新。目前,很多图数据库系统虽然支持实时更新,但是要么更新的QPS过低,要么更新到一定程度以后需要定时做索引重构,一旦数据量过大,就会严重消耗机器资源,甚至失败。GeaBase很好地解决了更新过程中的各种问题,可以高效稳定地进行实时更新。
核心功能
- 在线数据建模。根据客观世界中事物与事物之间的关系,提供在线数据建模。将事物抽象成点,事物间的关系抽象成边,针对错综复杂的关系进行点和边的构图,满足复杂业务场景的需求。
- 数据灵活加载。支持批量生成、增量加载和实时更新数据加载方式,可以灵活加载不同数据源的数据。支持在线导入ODPS数据,支持客户端实时更新数据,支持上传文件离线导入数据。
- 可视化查询测试。为提高用户编写查询语句的效率,提供查询语句在线可视化编辑功能。对于复杂的查询需求,通过拖拽控件和调整控件参数,能够直观地生成查询语句,并在线进行测试。
应用场景
GeaBase现在支撑着蚂蚁金服旗下支付的风险控制、反洗钱、反欺诈、反刷单、反套现、金融案件审理、知识图谱、会员拉新、好友推荐、理财资讯推荐等众多的业务和应用。
风控
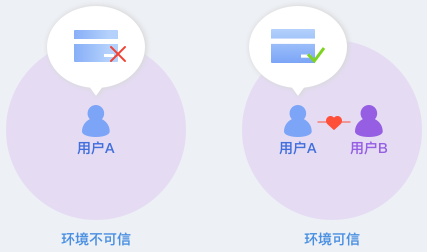
在风控识别系统中应用GeaBase,利用资金转账关系、可信设备关系、社交关系等数据进行建模。针对风险进行评估,可极大提高风控效能。比如用户A发起一笔交易,通过识别交易环境(手机IMEI、网络IP、MAC地址等)发现交易环境不是可信环境,但是通过关系数据进一步发现是其配偶用户B的可信环境,那么此交易仍可被判断为可信交易。这样用户A就不会被打扰(如要求输入密码),交易也能够流畅地完成。
社交
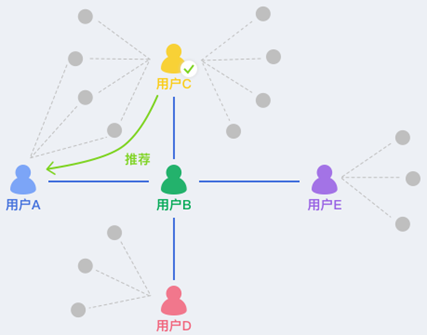
在社交关系上应用GeaBase,针对海量用户的社交数据进行建模,可以在错综复杂的关系中,分析有用的潜在价值。以支付宝钱包的好友推荐为例,如图所示:用户A和B是好友关系,B的好友C与A有多位共同好友,则C就会被推荐给A。这个推荐计算的关键是找出B与A的共同好友数。利用GeaBase可快速按照交集的大小进行排序,并返回结果。
推荐
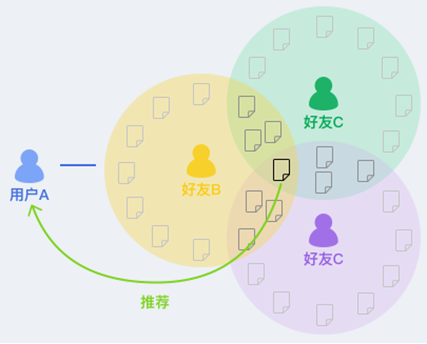
基于GeaBase构建推荐系统,对多种复杂关系进行数据建模,并将多种推荐逻辑(流计算或者离线计算)的结果汇聚存储,供在线实时查询。例如常见的向用户推荐好友阅读量最大的文章。如图:查询逻辑是计算用户A的所有好友阅读过的文章分别被阅读的次数,最终取被阅读次数最多的文章推荐。
GeaBase原理与架构
引入图数据库以有效地存储和查询图。存储在图数据库中的图通常是属性图模型(顶点,边和属性)。图数据库的一个关键特性是边(或连接)被视为模型的核心组件以及顶点。因此,可以有效地检索复杂的拓扑结构。相反,对于传统的关系型数据库,数据之间的连接存储在单独的表中,搜索连接的查询需要连接操作,这种代价通常极高。但是,为行业规模的应用设计高性能图形数据库具有挑战性:
- 图的不规则数据结构通常会导致对存储系统的随机访问,从而导致数据局部性差
- 为了存储大规模的图形,数据通常被分区,这导致高通信成本和不平衡的工负载
- 快速变化的分布式图数据库中的数据一致性也非常具有挑战性
GeaBase (Graph Exploration and Analytics Database),为行业规模的应用程序提供实时图遍历和分析功能。GeaBase整体架构主要分为三个部分:查询服务(Query)、数据加载(Data Load)和高可用性(HA),如下图所示:
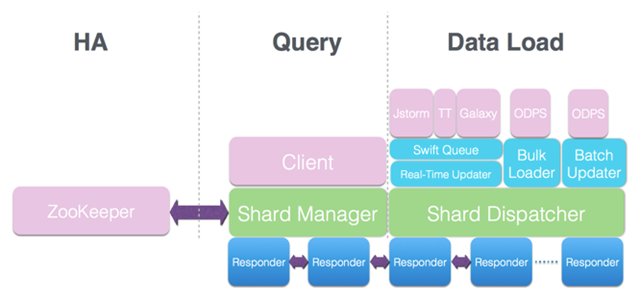
GeaBase将图按节点分割为多个分区(shards),每一个分区都在不同的主机(host)上进行备份。主机管理器(Host Manager)维护一张各个分区到可用主机的映射表(shard-host map)。
在GeaBase架构中,各个部分的职责如下:
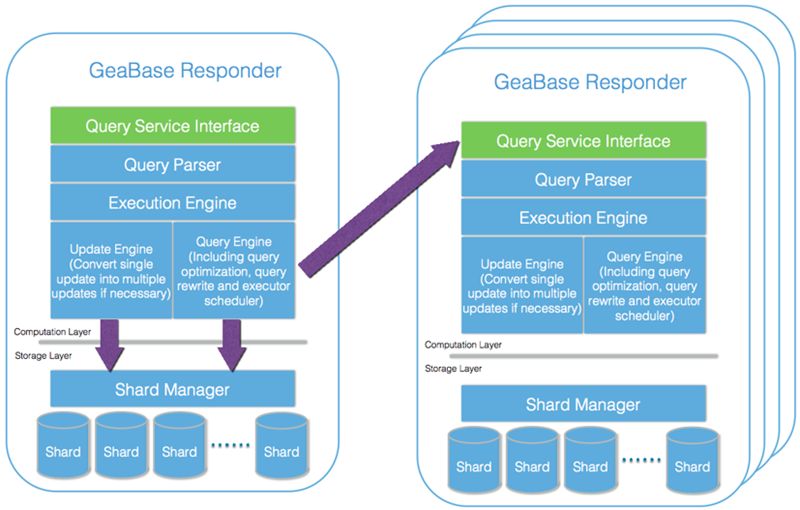
- 查询服务部分提供服务对用户的查询(query)做出响应。在这一部分中,客户端发出查询后,分区管理器(Shard Manager)从主机管理器取得最新的分区主机映射表,然后将该查询发送到合适(数据所在地)的主机做计算。这些做计算的主机叫作响应器(Responder)。一个响应器不一定有足够的数据对查询做出响应,这时,基于”计算寻找数据”的思想,该响应器会生成新的查询并发送到有数据的主机去做计算。响应器还有一个职责是与ZooKeeper群交流保证一致性、高可用性和容错。响应器的详细组成模块见下图:
- 数据加载部分完成数据的加载和更新。GeaBase 支持从 Jstorm、TT、Galaxy 等实时流获取数据,实时更新数据库,也支持从 ODPS 等数据仓库批量和增量导入数据。
- 高可用性部分保证系统的高可用性。
查询服务
查询服务的实现过程如下:
- 当一个客户端准备发出一个查询时,它首先在其映射表中查询所需数据所在的响应器,然后将查询发到该响应器进行处理。实际上,每一个响应器都有一个分区管理器用于与高可用集群同步并获得最新的映射表,客户端定期从任一响应器的分区管理器取得最新的映射表。
- 客户端发出查询后,由响应器进行响应。每一个响应器都是由计算层和存储层构成。计算层负责接收和解析查询并做相应计算,存储层负责寻找和读取数据。
- 响应器接受到查询后,交给查询解析器(query parser)做解析,然后执行引擎(execution engine)根据不同的操作调用不同的查询引擎(query engine)或者更新引擎(update engine)来做具体计算或者更改数据。查询引擎在执行查询计算时,如果发现本地数据不足以完成计算,将会生成新的查询并将这些查询发送到数据所在的响应器。更新引擎的相关功能,请参考数据加载。
引擎结构 Engine Structure
Query engine design principles is to perform computation at where data is.(准则:数据在哪计算就在哪)。查询处理流程:检查查询语句的语法;生成一个遍历或计算的计划;当查询需要非本地数据时,查询引擎会生成一个子查询,该子查询检索远程数据,并通过内部请求将子查询发送到目标节点所在的服务器。如果不需要内部请求,则遍历计划结束,结果数据将发送回客户端。
查询语言 Query Language
支持三类操作,还包括内置(build-in)和用户自定义(user-defined)方法以体现系统灵活性。
- 图的增删改查操作 graph CRUD operations: GetNodeProp (get nodes properties), GetEdgeProp (get edges properties), Nav(igation) (graph navigation), GetDistance, Limit, Add/Delete Node/Edge
- 图遍历和计算 traversal, computation: Sort, Union, Subtract, Combine (set operations), Agg (group by), For (iterations), variables
- 图分析 analysis: FindLoop, ShortestDistance, KCore, et al.
The GeaBase query language has a LISP like grammar that looks like: ( operator [ :ATTR=value ] ) * where [:ATTR=value] can be a sub-query.
Nav
类似于 SQL 的 SELECT 子句:
(Nav:DATA=(Nav:START=123 :EDGE_TYPE="friend" :RETURN=@name,@age :FILTER=@age>40) :EDGE_TYPE="family" :RETURN=$0,$1,@location,@city )
数据加载
GeaBase 支持灵活的数据加载方式。目前支持批量生成、增量加载和实时更新三种方式。
- 批量和增量数据加载方式数据来源主要是 ODPS,GeaBase 提供工具将 ODPS 数据批量转换成 GeaBase 存储数据类型或将数据加入已有的数据库中。
- GeaBase 同时支持来自 Jstorm、TT、Galaxy 等流数据源的实时数据更新。GeaBase 用 Swift 队列对这些实时数据先做缓存。不管实时数据来自哪种数据源,GeaBase 会先调用分区调度程序(ShardDispatcher)来得到数据应该存储的响应器,然后由此响应器中的更新引擎来插入或者更新这些数据。
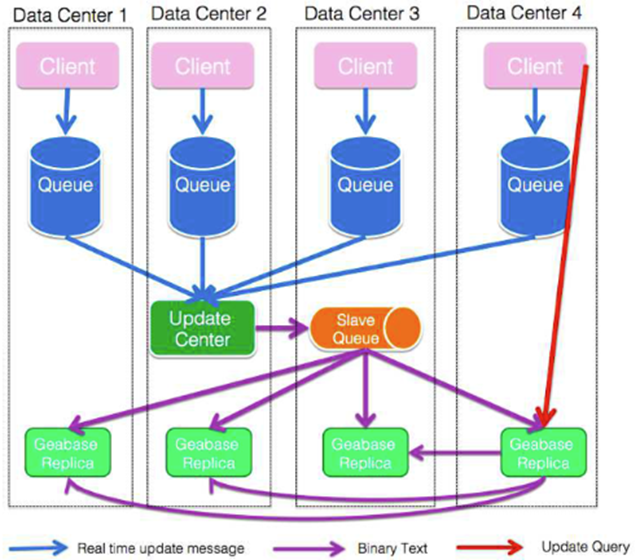
Real-time Update
实时数据在业务决策,财务风险管理和其它行业分析领域变得越来越重要。例如,在电子商务中,实时用户操作数据(例如点击,收集,购买)对于构建用户配置文件和优化推荐效果至关重要。在金融领域,实时用户购买和交易数据是风险管理的基本资源。实时更新模式可同时支持 synchronous 同步模式和 asynchronous 异步模式。
在同步模式下,upstream 系统将更新事件转换为查询字符串,并将其直接发送到一个 GeaBase 服务器,并等待服务器以其更新状态发回响应。如果更新事件成功,则后续读取查询将获取最新数据。当此模式与用户粘性策略一起使用时,用户将始终获得一致的数据。有时用户更关心更新吞吐而不是更新响应时间。upstream 系统可以选择将更新事件转换为消息,然后将其放入分布式队列以供所有 GeaBase 副本异步使用。实际上,当不同区域中的多个分布式消息队列服务可用时,所选择的消息队列是与上游系统最接近的消息队列。每个 GeaBase 副本的剩余作业都是不断消耗客户端排队的更新消息,这些消息来自所有区域中的所有消息队列。某些应用程序不需要严格的更新顺序,并且它们需要高更新吞吐量。对于这些情况,GeaBase 提供了一种实时更新的异步模式。上游系统将更新事件转换为消息,然后将其放入分布式队列,然后由所有 GeaBase 副本异步使用。
具体地,消息队列中的数据被分区,对应于 GeaBase 分片策略,并且每个 GeaBase 服务器订阅 subscribes 消费与其保持的分片对应的队列的分区。这种架构保证了弱消息序列。在每个分区中,消息序列由接收消息的顺序确定。但是,跨分区不保证序列。共享相同密钥 ID 的节点或边缘消息将被发送到同一队列分区,因此,根据其发送顺序处理同一节点或边缘上的添加/更新/删除操作。三个缺点:
- 不能保证副本一致性
- 消息被重复编码,浪费 CPU 资源
- 有很多的消费队列,会使 MQ 集群压力大
解决方案:更新中心架构被提出 (update center architecture is proposed). 选择一个 MQ 副本作为 update center 即 master queue. 用来消费队列和存储用户生成的消息;将编码后的消息存储下来并发送给其它的 slave queue;所有其它的副本消费 slave queue 并相应的更新存储。
好处:通过这种方式,所有副本始终使用相同的数据,从而确保数据的一致性。此外,编码过程仅在更新中心执行。还值得一提的是,更新中心可以切换到任何其他副本,因为它们之间的唯一区别是它们使用不同的消息队列。
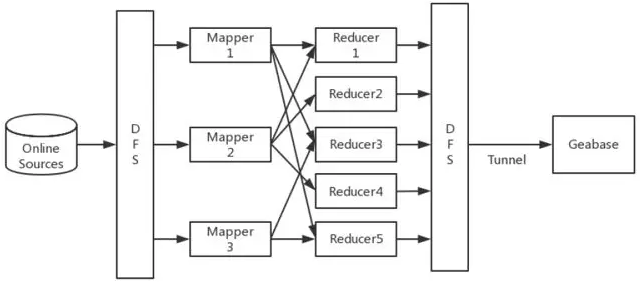
批更新 Batch Update
批更新如下图所示,常用于从数据仓库导入批量计算结果图。数据仓库中的数据通常格式化为表格。我们要求所有表都包含以下元素:键 key ID,值 value 和标记 tag。标记表示特定的更新方法,例如添加,删除,更新。GeaBase 对表进行分片,每个服务器读取一个表的子集并相应地更新数据库。
高可用性
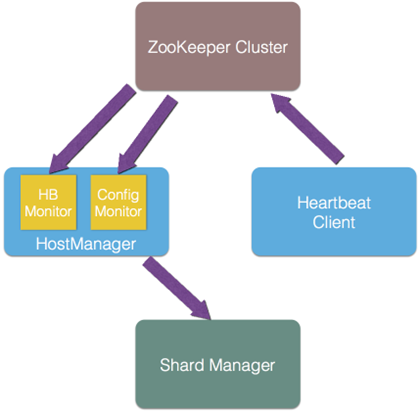
高可用性由主机管理器、分区管理器、心跳客户端(HeartBeatClient)、心跳监控器(HeartBeatMonitor)、配置管理器(ConfigMonitor)和 ZooKeeper 集群这些模块配合实现。
高可用性的实现过程如下:
- 每一个响应器的查询服务启动时,GeaBase 将同时启动心跳客户端和主机管理器。
- 心跳客户端会定时向 ZooKeeper 汇报自己的状态(是否可用)。如前面的响应器图所示,主机管理器内部维护一个心跳监控器和一个配置管理器,分别定时从 ZooKeeper 读取每个响应器的状态变化和配置文件的变化。
如果有变化,心跳监控器和配置管理器会通知主机管理器,然后主机管理器根据情况改变分区管理器中维护的映射表。这样,每个响应器的映射表都是最新且一致的,在任何响应器不可用时,查询都会被及时地调度到可用的响应器。
图存储 GraphStorage
在GeaBase中,顶点和边都被存储为键值对(key-value pairs)。属性被序列化并根据用户定义的模式(schema)存储在key-value pair的值部分中。根据基于散列的分片策略将记录存储在不同的分片中。通常,GeaBase实例包含由分片管理器(shard manager)维护的数十或数百个分片。
数据模型 DataModel
图数据库基本的数据模型被描素为OLP(对象-关系-属性,object-link-property)。GeaBase被设计为支持大规模,多维度的图,包括顶点类型(typed-nodes),有向边(directed-typed-edges)以及它们的属性。
GeaBase的数据模型被描素为GraphSchema,包括一个顶点类型list和一个边类型list。GraphSchema中一个典型的顶点包含一个声明其类型的字段,以及一个表示该顶点的属性fileds的列表键值对。源顶点类型,目的顶点类型,边类型,属性列表和方向(有向或无向)都是Schema中有效顶点所需的。除了上面提到的基本要求之外,用户还可以向顶点和边添加可选字段(例如,生存时间字段)。总之,当给定特定的边或顶点类型时,可以从该GraphSchema中获知有关的拓扑结构和序列化格式。
存储模型 StorageModel
下图给出了GeaBase存储中键值的结构。特别的,一个顶点被存储为一个单一的key-value对,由顶点ID,顶点类型,和顶点属性组成。一个有向边被存储为两个key-value对,分别叫做OutEdge和InEdge,都由源顶点ID,边类型,目的顶点ID和边属性组成。可以将OutEdge视为前向索引(forward index),用于在给定源节点时搜索到目标的跟踪(称为出边导航)。InEdge可以被视为反向索引(reverse index),用于在给定目的顶点时搜索到源顶点的跟踪(称为入边导航)。所有的边类型,顶点类型和给定顶点或边的属性格式都在GraphSchema中指定。为了节省存储空间,边属性可以存储在一个方向上,基本可以节约一半的空间。
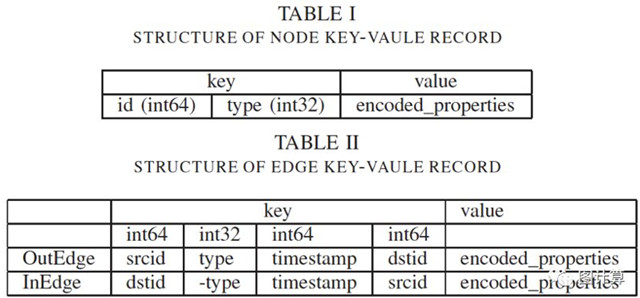
分片策略 ShardingStrategy
有记录(records)都按key的前8个字节(int64)进行分片。顶点记录将由顶点ID分散,OutEdge记录将由源ID分散,而InEdge则按目的地ID分散。这种分片策略的动机是避免通过网络传输海量数据。在这种策略下,源顶点和源自它的所有OutEdges都位于相同分片中。这同样适用于目的节点和InEdges。因此,在前向forward遍历的情况下,可以在相同的分片中获取边和目的顶点的属性。
参考链接:


