ClickHouse简介
ClickHouse是一个开源的列式数据库管理系统(Column-Oriented DBMS),专为实时大数据分析而设计。它支持实时查询,能够处理PB级别的数据,并且在大多数情况下提供了非常高的查询性能。ClickHouse由俄罗斯最大的搜索引擎Yandex开发,并于2016年对外开源。

得益于列式存储的特性,以及ClickHouse做的诸多优化,使得它在批量查询分析上面非常的具有优势。对一张拥有133个字段的数据表分别在1000万、1亿和10亿三种数据体量下执行基准测试,基准测试的范围涵盖43项SQL查询。在1亿数据级体量的情况下,ClickHouse的平均响应速度是Vertica的2.63倍、InfiniDB的17倍、MonetDB的27倍、Hive的126倍、MySQL的429倍以及Greenplum的10倍。
具体的Benchmark可以看这里:https://benchmark.clickhouse.com/,这里随便放一下对比差异:

优点
- 高性能:ClickHouse的列式存储结构和向量化查询执行引擎使其在处理大规模数据查询时具有极高的性能,尤其在聚合和分析操作上。
- 多租户支持:ClickHouse可以在同一实例中支持多个独立的数据库,每个数据库都可以有自己的表结构和数据,适合多租户环境下的应用。
- 实时分析:支持实时数据写入和查询,适合需要快速响应的分析场景,如在线广告投放、实时监控等。
- 水平可扩展性:支持分布式部署,能够通过增加节点来扩展系统的存储和计算能力,适合大规模数据处理。
- 高效的数据压缩:提供多种压缩算法,可以显著减少存储空间需求,同时提高I/O效率。
- 标准SQL支持:ClickHouse支持大多数标准SQL功能,降低了用户的学习成本,并且便于集成到现有的技术栈中。
- 丰富的数据类型:支持多种数据类型,包括数组、嵌套结构等,适合复杂数据模型的处理。
- 开源和活跃的社区:作为一个开源项目,ClickHouse拥有活跃的开发和用户社区,提供丰富的资源和支持。
缺点
- 事务支持有限:ClickHouse并不支持完整的ACID事务,这意味着在某些需要强一致性和事务支持的场景中可能不太适用。
- 写入性能瓶颈:尽管读取性能极高,但在高并发写入场景下,ClickHouse的性能可能会受到一定限制,需要精心设计数据导入策略。
- 复杂的分布式管理:在分布式部署中,管理和维护ClickHouse可能会比较复杂,特别是在节点故障和数据恢复方面。
- 缺乏更新和删除功能:ClickHouse的设计主要针对批量数据加载和分析,直接更新和删除操作并不高效,这可能需要通过分区策略和数据重写来间接实现。
- 工具和生态系统不如某些成熟数据库:虽然ClickHouse社区在不断增长,但其生态系统和第三方工具支持仍不如一些更成熟的数据库系统丰富。
应用场景
ClickHouse作为一个高性能的列式数据库,适用于多种需要快速数据处理和分析的场景。以下是一些典型的应用场景:
- 实时数据分析:ClickHouse的高吞吐量和低延迟特性使其非常适合实时数据分析。这包括在线广告投放效果分析、用户行为分析、实时监控和告警系统等。
- 数据仓库:由于其强大的查询能力和高效的数据压缩,ClickHouse可以用作数据仓库,处理大规模的数据存储和分析任务。
- 商业智能(BI)和报表:ClickHouse可以作为数据仓库的一部分,支持复杂的OLAP查询,为BI工具和报表系统提供快速的数据分析服务。
- 日志和事件数据处理:由于能够高效处理大量的日志和事件数据,ClickHouse常用于日志分析平台,如监控系统日志、Web服务器访问日志、应用程序事件日志等。
总体而言,ClickHouse非常适合大规模数据分析和实时查询的场景,但在选择使用时需要权衡其在事务支持、写入性能和管理复杂性等方面的不足。根据具体的应用需求和场景,合理设计和优化ClickHouse的使用策略,可以最大化其优点,最小化其缺点。
ClickHouse表引擎
ClickHouse是一个列式数据库管理系统,它提供了多种表引擎以满足不同的使用场景和性能需求。ClickHouse 的表引擎是 ClickHouse 服务的核心,它们决定了 ClickHouse 的以下行为:
- 数据的存储方式和位置。
- 支持哪些查询操作以及如何支持。
- 数据的并发访问。
- 数据索引的使用。
- 是否可以支持多线程请求。
- 是否可以支持数据复制。
MergeTree系列引擎
MergeTree系列引擎是ClickHouse中最常用的表引擎,专为高性能的数据写入和查询而设计,适用于处理大规模数据集。以下是对MergeTree系列引擎的详细介绍:
MergeTree引擎
特点
- 分区(Partitioning):通过对数据进行分区,可以将数据按照某个字段(如日期)划分成多个段,提高查询性能和管理效率。
- 排序键(ORDER BY):定义排序键以优化查询。排序键的选择对查询性能有重要影响。
- 主键索引(Primary Key Index):支持主键索引,以便快速查找数据。
- TTL(Time to Live):支持自动清理过期数据。
- 异步合并:数据在后台异步合并,提升写入性能。
使用示例
CREATE TABLE example( date Date, id UInt32, value String ) ENGINE = MergeTree() PARTITION BY toYYYYMM(date) ORDER BY (id, date)
ReplicatedMergeTree引擎
特点
- 数据复制:用于在集群环境中实现数据的高可用性,通过在多个节点上自动复制数据。
- ZooKeeper协调:需要配置ZooKeeper来协调数据的复制和节点状态。
- 故障恢复:在节点故障时自动恢复数据。
使用示例
CREATE TABLE example(
date Date,
id UInt32,
value String
) ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/example', '{replica}')
PARTITION BY toYYYYMM(date)
ORDER BY (id, date)
ReplacingMergeTree引擎
特点
- 数据去重:用于自动合并重复的数据行,保留最新版本。
- 版本列:可以指定一个版本列,以便在合并时选择保留最新版本的数据。
使用示例
CREATE TABLE example( id UInt32, value String, version UInt32 ) ENGINE = ReplacingMergeTree(version) ORDER BY id
SummingMergeTree引擎
特点
- 自动求和:对具有相同主键的行自动求和,适合用于累积指标或统计数据。
- 局限性:仅对数值列进行求和,其他列保持不变。
使用示例
CREATE TABLE example( id UInt32, value UInt32 ) ENGINE = SummingMergeTree() ORDER BY id
AggregatingMergeTree引擎
特点
- 聚合存储:用于存储预先聚合的数据,以提高查询性能。
- 支持多种聚合函数:如 sum, avg, min, max 等。
使用示例
CREATE TABLE example( id UInt32, sum_value AggregateFunction(sum, UInt32) ) ENGINE = AggregatingMergeTree() ORDER BY id
CollapsingMergeTree引擎
特点
- 数据崩溃:用于合并具有相同主键的行,并通过特殊标志列(Sign)进行增量和减少。
- 应用场景:适合处理数据流中插入和删除的场景。
使用示例
CREATE TABLE example( id UInt32, value Int32, Sign Int8 ) ENGINE = CollapsingMergeTree(Sign) ORDER BY id
VersionedCollapsingMergeTree引擎
特点
- 版本化崩溃:类似于 CollapsingMergeTree,但支持版本化。
- 版本列:通过版本列来控制数据的增减。
使用示例
CREATE TABLE example( id UInt32, value Int32, Sign Int8, version UInt32 ) ENGINE = VersionedCollapsingMergeTree(Sign, version) ORDER BY id
GraphiteMergeTree引擎
特点
- 时间序列数据:专为存储 Graphite 时间序列数据而设计。
- 自动汇总:支持自动汇总旧数据,以减少存储空间。
使用示例
CREATE TABLE example(
Path String,
Time UInt32,
Value Float32,
Version UInt32
) ENGINE = GraphiteMergeTree('config_element')
ORDER BY (Path, Time)
Distributed引擎
Distributed引擎是ClickHouse中用于创建分布式表的引擎,主要用于在集群环境中实现数据的分布式存储和查询。它允许在多个ClickHouse节点上分片存储数据,并将查询请求分发到多个节点以实现并行处理,从而提高查询性能和系统的可扩展性。
Distributed引擎的主要特点
- 数据分片:
- 数据可以在多个节点上分片存储。
- 通过指定分片键(sharding key),可以控制数据如何在集群中分布。
- 查询分发:
- 查询请求被自动分发到所有相关的节点,并行执行以提高查询速度。
- 支持对分布式数据的聚合和排序。
- 高可用性:
- 可以结合 ReplicatedMergeTree 引擎使用,实现数据的复制和高可用性。
- 负载均衡:
- 自动在多个节点间进行负载均衡,避免单点瓶颈。
- 透明性:
- 对用户而言,分布式表的使用与本地表无异,查询语法相同。
Distributed引擎的配置参数
- cluster_name:集群名称,定义在配置文件 xml 中。
- database_name:分布式表指向的数据库名称。
- table_name:分布式表指向的本地表名称。
- sharding_key(可选):用于数据分片的键。
配置集群
在ClickHouse的配置文件(通常是config.xml或clusters.xml)中定义集群信息:
<remote_servers> <my_cluster> <shard> <replica> <host>node1</host> <port>9000</port> </replica> <replica> <host>node2</host> <port>9000</port> </replica> </shard> <shard> <replica> <host>node3</host> <port>9000</port> </replica> <replica> <host>node4</host> <port>9000</port> </replica> </shard> </my_cluster> </remote_servers>
创建本地表
在每个节点上创建本地表:
CREATE TABLE local_example( date Date, id UInt32, value String ) ENGINE = MergeTree() PARTITION BY toYYYYMM(date) ORDER BY id;
创建分布式表
在一个节点上创建分布式表:
CREATE TABLE distributed_example AS local_example ENGINE = Distributed(my_cluster, default, local_example, id);
- my_cluster:集群名称。
- default:数据库名称。
- local_example:本地表名称。
- id:分片键(可选),用于决定数据如何在不同的节点间分布。
使用场景
- 大规模数据分析:在大数据量的情况下,利用集群的计算能力进行快速查询。
- 负载均衡和扩展:通过分布式架构,实现负载均衡和水平扩展。
高可用性需求:通过结合 ReplicatedMergeTree,实现数据的高可用性和故障恢复。
注意事项
- 数据一致性:由于数据分布在多个节点上,需要注意数据的一致性和复制策略。
- 网络延迟:分布式查询可能受网络延迟影响,因此集群节点间的网络性能至关重要。
- 配置复杂性:分布式系统的配置和管理相对复杂,需要仔细规划和测试。
Distributed 引擎在 ClickHouse 中提供了强大的分布式数据处理能力,使其能够处理大规模、高并发的数据查询任务。通过合理的集群配置和分片策略,可以显著提升系统的性能和可用性。
Log 系列引擎
Log 系列引擎在 ClickHouse 中用于处理简单的数据存储和检索需求,主要用于测试、开发和嵌入式环境。这些引擎提供了轻量级的数据存储选项,适合需要快速写入和读取的小型数据集。
Log 引擎
特点
- 简单存储:Log 引擎提供简单的行式存储,适合开发和调试。
- 无索引:不支持任何索引或分区功能,因此不适合大规模数据查询。
- 快速写入:由于不维护索引,数据写入速度较快。
- 适用场景:适合测试环境、小型数据集和需要快速写入的场景。
使用示例
CREATE TABLE log_example ( id UInt32, value String ) ENGINE = Log;
TinyLog 引擎
特点
- 极简存储:类似于 Log 引擎,但更简单,适合嵌入式和低资源环境。
- 无多线程支持:数据存储在单个文件中,不支持多线程写入。
- 低内存占用:适合对内存占用敏感的应用场景。
- 适用场景:适用于资源受限的设备或需要极简数据存储的应用。
使用示例
CREATE TABLE tinylog_example ( id UInt32, value String ) ENGINE = TinyLog;
StripeLog 引擎
特点
- 优化的列式存储:数据以条带(stripe)形式存储,每个条带包含一组行的数据。
- 支持更高效的列读取:相比 Log 和 TinyLog,引入了一定的列存储优化,适合读取较多的场景。
- 适用场景:适合需要读取特定列的小规模数据集。
使用示例
CREATE TABLE stripelog_example ( id UInt32, value String ) ENGINE = StripeLog;
Log 系列引擎的比较
- Log vs TinyLog:
- Log 引擎支持简单的行式存储,适合快速写入和读取。
- TinyLog 更为简单,适合嵌入式环境和低资源消耗场景。
- Log vs StripeLog:
- Log 是最基本的行式存储,不支持列优化。
- StripeLog 引入了列式存储优化,适合需要高效列读取的小规模数据。
使用场景
- 开发和测试:由于 Log 系列引擎的简单性和快速写入特性,适合用于开发和测试环境。
- 嵌入式应用:TinyLog 引擎特别适合资源受限的嵌入式应用。
- 快速原型:在不需要复杂查询和索引的情况下,可以使用 Log 系列引擎快速实现数据存储原型。
注意事项
- 性能限制:由于缺乏索引和分区,Log 系列引擎不适合大规模数据集和复杂查询。
- 数据持久性:在需要持久化和恢复能力的生产环境中,应该选择更为成熟的引擎如 MergeTree 系列。
Log 系列引擎提供了一个简单和轻量级的选项,适合于某些特定场景,如开发测试和资源受限的环境。在选择引擎时,需要根据具体的需求和数据规模来决定使用哪种引擎。
其他引擎
除了 MergeTree 系列、Distributed 引擎和 Log 系列引擎,ClickHouse 还提供了一些其他表引擎,以满足不同的使用场景和需求。
Memory 引擎
特点
- 内存存储:数据存储在内存中,适合需要快速访问的小型数据集。
- 数据易失:重启后数据会丢失,因此不适合持久化存储。
- 高性能:由于数据驻留在内存中,查询性能极高。
使用示例
CREATE TABLE memory_example ( id UInt32, value String ) ENGINE = Memory;
使用场景
- 临时数据处理。
- 需要快速访问的数据缓存。
Null 引擎
特点
- 数据丢弃:所有写入的数据都会被忽略,适用于测试和开发。
- 无存储开销:由于不存储数据,完全没有存储开销。
使用示例
CREATE TABLE null_example ( id UInt32, value String ) ENGINE = Null;
使用场景
- 测试数据写入性能。
- 验证数据生成逻辑。
Kafka 引擎
特点
- 流数据处理:从 Kafka 消息队列中读取数据,适合实时流式数据处理。
- 自动消费:支持自动消费 Kafka 主题中的消息。
- 与其他表引擎结合:通常与 MergeTree 等引擎结合使用,以便持久化存储消费的数据。
使用示例
CREATE TABLE kafka_example ( id UInt32, value String ) ENGINE = Kafka SETTINGS kafka_broker_list = 'localhost:9092', kafka_topic_list = 'example_topic', kafka_group_name = 'example_group';
使用场景
- 实时数据分析。
- 流式数据处理。
HDFS 引擎
特点
- 分布式文件系统支持:直接在 Hadoop 分布式文件系统(HDFS)中存储和读取数据。
- 大数据生态系统集成:适合与 Hadoop 大数据生态系统集成。
使用示例
CREATE TABLE hdfs_example (
id UInt32,
value String
) ENGINE = HDFS('hdfs://namenode:8020/path/to/file.csv', 'CSV');
使用场景
- 大数据分析。
- 与Hadoop集成的场景。
File引擎
特点
- 文件存储:数据存储在本地文件系统中,支持多种文件格式(如CSV、TSV、JSON)。
- 简单导入导出:适合数据的导入和导出操作。
使用示例
CREATE TABLE file_example(
id UInt32,
value String
) ENGINE = File('CSV', '/path/to/file.csv');
使用场景
- 数据导入导出。
- 与外部系统的数据交换。
URL引擎
特点
- 远程数据读取:支持从HTTP或HTTPS URL读取数据。
- 灵活性:适合从外部系统动态获取数据。
使用示例
CREATE TABLE url_example(
id UInt32,
value String
) ENGINE = URL('http://example.com/data.csv', 'CSV');
使用场景
- 从外部API获取数据。
- 远程数据集成。
ODBC引擎
特点
- 跨数据库查询:通过ODBC驱动程序访问外部数据库。
- 异构数据源集成:适合与其他数据库系统集成。
使用示例
CREATE TABLE odbc_example(
id UInt32,
value String
) ENGINE = ODBC('DSN=DataSourceName', 'database', 'table');
使用场景
- 跨数据库查询。
- 数据迁移。
ClickHouse存储剖析
ClickHouse的数据存储
ClickHouse的数据全都在 /var/lib/clickhouse/data 这个目录下面,按照官网教程 https://clickhouse.com/docs/en/getting-started/example-datasets/ontime#creating-a-table 创建一个这样的表:
CREATE TABLE hits_UserID_URL ( `UserID` UInt32, `URL` String, `EventTime` DateTime ) ENGINE = MergeTree PRIMARY KEY (UserID, URL) ORDER BY (UserID, URL, EventTime) SETTINGS index_granularity = 8192, index_granularity_bytes = 0;
在这个表里面我们指定了一个复合主键(UserID, URL),排序键(UserID, URL, EventTime)。如果只指定排序键,那么主键会被隐式设置为排序键。如果同时指定了主键和排序键,则主键必须是排序键的前缀。
执行成功后会在文件系统 /var/lib/clickhouse/data/default/hits_UserID_URL 中创建如下的目录结构:
. ├── all_1_1_0 ... │ ├── primary.cidx │ ├── URL.bin │ ├── URL.cmrk │ ├── UserID.bin │ └── UserID.cmrk ├── all_1_7_1 ... │ ├── primary.cidx │ ├── serialization.json │ ├── URL.bin │ ├── URL.cmrk │ ├── UserID.bin │ └── UserID.cmrk ├── detached └── format_version.txt
/var/lib/clickhouse/data 目录里面的一层default表示database名称,没有指定默认就是default,然后再往里面就是hits_UserID_URL表示表名,all_1_1_0表示分区目录。
然后就是列字段相关的文件了,每列都会有两个字段:
- {column}.bin:列数据的存储文件,以列名+bin为文件名,默认设置采用lz4压缩格式;
- {column}.cmrk:列数据的标记信息,记录了数据块在bin文件中的偏移量;
primary.cidx:这个是主键索引相关的文件的,用于存放稀疏索引的数据。通过查询条件与稀疏索引能够快速的过滤无用的数据,减少需要加载的数据量。
因为设定了主键和排序键,所以数据在写入的时候会按照UserID、URL、EventTime 顺序写入到bin文件里面:

因为主键的顺序和文件的写入是相关的,所以一张表也只能有一个主键。
最小数据集granule
出于数据处理的目的,表的列值在逻辑上被划分为granule。granule是为进行数据处理而流式传输到ClickHouse中的最小的不可分数据集。这意味着ClickHouse不是读取单个行,而是始终读取(以流式传输方式并行读取)整个组(granule)行数据。
比如我们上面在创建表的时候指定了index_granularity为8192,即数据将会以8192行为一个组,表里面我们插入了886w条数据,那么就分为了1083个组:

每个granule分组的第一条数据会被写入到primary.cidx当作索引处理。
主键索引primary.cidx
ClickHouse是通过稀疏索引的方式来构建主键索引的,所以它只记录granule的开始位置,一条索引记录就能标记大量的数据。所以像我们上面的例子中,886w条数据,只有1083个granule,那么索引数量也只有1083条,索引少占用的空间就小,所以对ClickHouse而言,primary.cidx中的数据是可以常驻内存。

再加上数据存储的时候就是顺序存储,所以ClickHouse在利用索引过滤查找数据的时候可以用二分查找快速的定位到索引数据位置。
但是由于granule是个逻辑数据块,我们并不直接知道它在数据文件(.bin)中的存储位置。因此,我们还需要一个文件用来定位granule,这就是标记(.mrk)文件。
标记文件.mrk
这里需要说明一下,根据ClickHouse版本、数据情况、压缩格式,标记文件会有不同的结尾,如:cmrk、cmrk2、mrk2、mrk3等等,由于它们的作用都是用来做文件映射,找到数据的物理地址用的。对于mrk标记文件每一行包含了两部分的信息,block offset以及granule offset,在bin文件中,为了减少数据文件大小,数据需要进行压缩存储。如果直接将整个文件压缩,则查询时必须读取整个文件进行解压,显然如果需要查询的数据集比较小,这样做的开销就会显得特别大。因此,数据是以块(Block)为单位进行压缩,一个压缩数据块可以包含若干个granule的数据,如下:
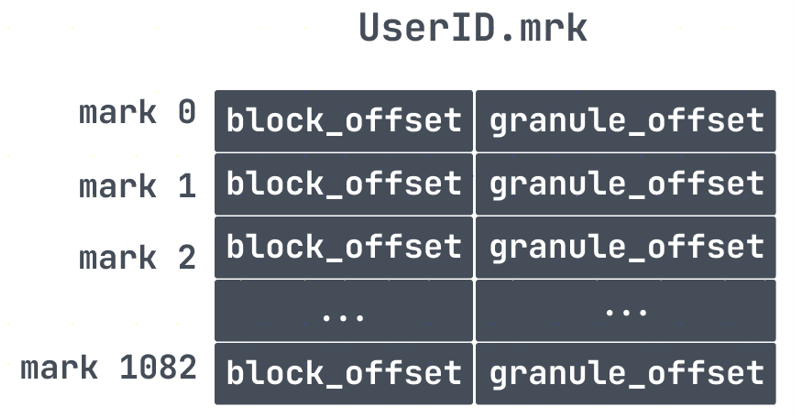
比如上面我们通过primary.cidx找到了对应数据所在mark 176,然后就可以对应的去mrk里面找对应的block offset和granule offset。然后通过block offset找到该数据文件包含的压缩数据。一旦所定位的文件块被解压缩到主内存中,就可以使用标记文件的granule offset在未压缩的数据中定位对应的数据。

联合主键查询
像我们上面的例子中,key设定的是UserID, URL两个字段,这种key被称为联合主键。基于ClickHouse主键索引构造的方式可以很容易想到,如果where条件里面包含了联合主键的第一个键列,那么ClickHouse可以使用二分查找法进行快速的索引。
但是,当查询过滤的列是联合主键的一部分,但不是第一个键列时会发生什么?比如where条件里面只写了 URL=’xxx’,那么ClickHouse会执行全表扫描,因为数据是首先按UserID排列,当UserID相同时,才会按照URL排列,那么URL可能分布在各个地方。
delete&update操作
ClickHouse主键或排序键都是按照顺序存储,然后按block进行压缩存储,那么如果删除又是怎样做的呢?
Clickhouse是个分析型数据库。这种场景下,数据一般是不变的,因此Clickhouse对update、delete的支持是比较弱的。标准SQL的更新、删除操作是同步的,即客户端要等服务端反回执行结果,而Clickhouse的update、delete是通过异步方式实现的。
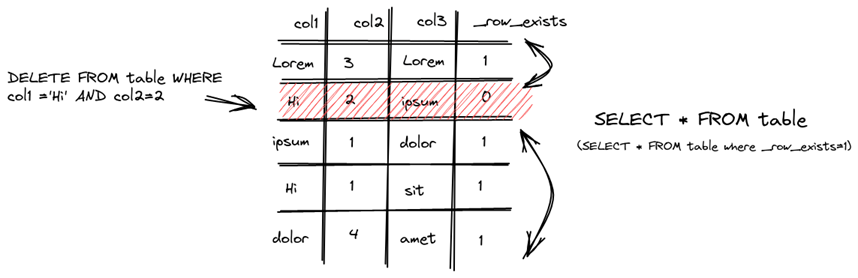
对于删除操作来说有两种方式 DELETE FROM和ALTER…DELETEDELETE FROM
对于 DELETE FROM 操作操作来说,只是对已经删除的数据做了个标记,表示已经删了,并将自动从所有后续查询中过滤出来。但是,在下一次数据合并整理期间会清理数据。因此,在可能存在一定的时间段内,数据可能不会从存储中实际删除,而只是标记为已删除。这种删除属于轻量级删除,这种方式的缺点是数据并没有立即从磁盘种被清理。
执行删除时,ClickHouse为每一行保存一个掩码,指示它是否在 _row_exists 列中被删除。后续查询反过来会排除那些已删除的行。
ALTER…DELETE
对于立即需要从磁盘中清理需求,可以通过使用ALTER…DELETE操作:
alter table hits_UserID_URL delete where UserID = 240923
ALTER…DELETE操作默认情况是异步执行的,我们可以通过 system.mutations 表执行监控:
SELECT command, is_done FROM system.mutations WHERE `table` = 'hits_UserID_URL' Query id: 78c3169a-abbc-415a-bcb2-0377d29fa547 ┌─command──────────────────────┬─is_done─┐ │ DELETE WHERE UserID = 240923 │ 1 │ └──────────────────────────────┴─────────┘
如果 is_done 的值为 0 ,表示它仍在执行中, is_done 的值为 1表示执行完毕。
对于update来说,主键的列或者排序键的值就不能被更改了,这是因为更改键列的值可能会需要重写大量的数据和索引,这对于一个以高性能读操作为设计目标的列式数据库来说,是非常低效的。所以只能修改非主键的列或者排序键的值。更新ClickHouse表中数据的最简单方法是使用ALTER…UPDATE语句。
ALTER TABLE hits_UserID_URL UPDATE col1 = 'Hi' WHERE UserID = 240923
ALTER…UPDATE操作和ALTER…DELETE一样都同属于mutation操作,都是异步的。那么对于异步的方式来更新删除数据,就会涉及到一致性的问题。
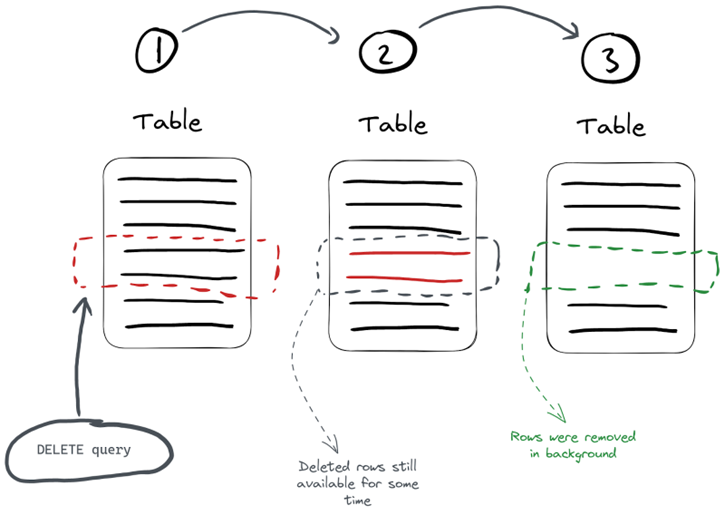
像上图所示,mutation操作具体过程实际上分为这么几步:
- 使用where条件找到需要修改的分区;
- 重建每个分区;
- 用新的分区替换旧的;
数据的重建替换不是全部同时执行的,而是分批执行的。
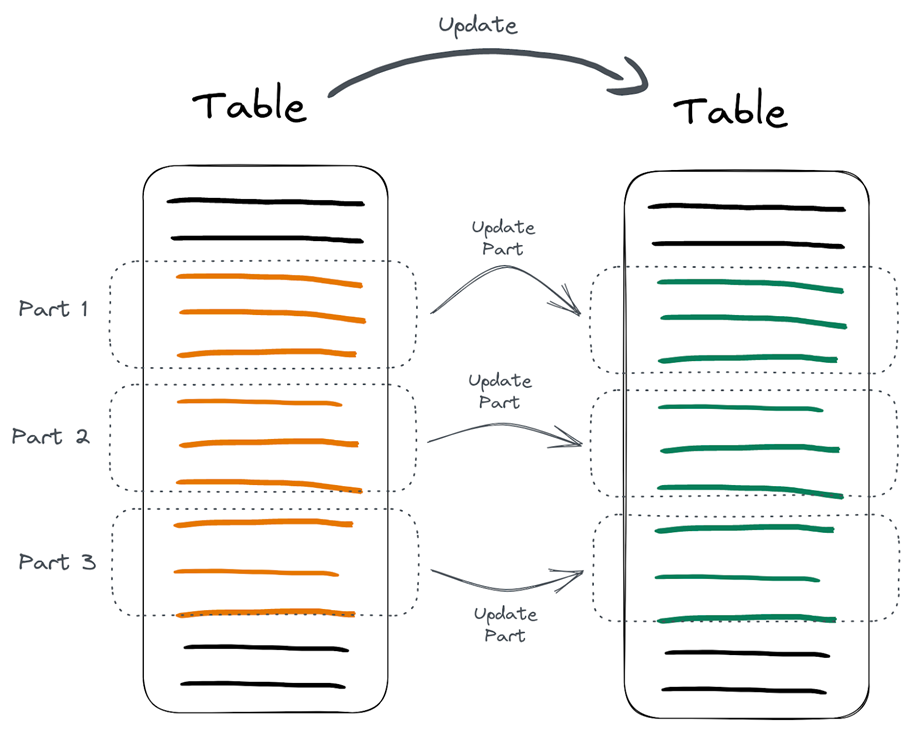
如果在重建替换的过程中,用户去查询数据,如果查询跨越了部分已经被更新的数据段和部分尚未被更新的数据段,用户可能会同时看到旧数据和新数据,也就是说ClickHouse是不做原子性保证的。
按照官方的说明,update/delete的使用场景是一次更新大量数据,也就是where条件筛选的结果应该是一大片数据。
总结
通过上面ClickHouse的分析我们大概知道了列式数据库有啥优缺点,优点是可以忽略不需要的字段查询非常快,数据可以压缩,索引使用稀疏索引的方式不需要占用很多空间,可以支持超大量的数据分析;缺点是没有事务,对于单行数据的查询效率并不高,删除修改效率很低。所以在选型上面可以根据自己的业务需求,如果是有大量数据分析的需求,不妨试一下ClickHouse。
ClickHouse的安装
单机安装
使用包管理器安装
在单机上安装ClickHouse可以通过多种方式完成,以下是使用包管理器在Linux系统上安装ClickHouse的详细步骤。这种方法适用于Ubuntu和CentOS等常见Linux发行版。
在Ubuntu上安装ClickHouse
# 更新系统并安装必要的依赖: sudo apt-get update sudo apt-get install -y apt-transport-https ca-certificates dirmngr # 添加ClickHouse APT存储库: sudo apt-key adv --keyserver keyserver.ubuntu.com --recv E0C56BD4 echo "deb https://repo.clickhouse.com/deb/stable/main/" | sudo tee /etc/apt/sources.list.d/clickhouse.list # 安装ClickHouse: sudo apt-get update sudo apt-get install -y clickhouse-server clickhouse-client # 启动ClickHouse服务 sudo service clickhouse-server start # 验证安装:使用ClickHouse客户端连接到服务器: clickhouse-client
在CentOS上安装ClickHouse
# 安装必要的依赖: sudo yum install -y yum-utils # 添加ClickHouse YUM存储库: sudo rpm --import https://repo.clickhouse.com/CLICKHOUSE-KEY.GPG sudo yum-config-manager --add-repo https://repo.clickhouse.com/rpm/stable/x86_64 # 安装ClickHouse: sudo yum install -y clickhouse-server clickhouse-client # 启动ClickHouse服务: sudo systemctl start clickhouse-server # 验证安装:使用ClickHouse客户端连接到服务器: clickhouse-client
使用Docker安装
使用Docker安装ClickHouse是一种简单而高效的方法,适用于各种操作系统。以下是使用Docker安装和运行ClickHouse的步骤:
安装Docker
如果你的系统还没有安装Docker,可以通过以下步骤安装:
# Ubuntu: sudo apt-get update sudo apt-get install -y docker.io # CentOS: sudo yum install -y docker # 启动Docker服务: sudo systemctl start docker sudo systemctl enable docker
拉取ClickHouse Docker镜像
docker pull clickhouse/clickhouse-server
运行ClickHouse容器
docker run -d --name clickhouse-server --ulimit nofile=262144:262144 -p 8123:8123 -p 9000:9000 -p 9009:9009 clickhouse/clickhouse-server
- –name clickhouse-server:为容器指定一个名称。
- –ulimit nofile=262144:262144:设置文件描述符限制,以确保ClickHouse能够处理大量文件。
- -p 8123:8123:映射HTTP接口端口。
- -p 9000:9000:映射TCP接口端口。
- -p 9009:9009:映射用于内部通信的端口。
连接到ClickHouse
使用ClickHouse客户端连接到服务器:
docker exec -it clickhouse-server clickhouse-client
这将启动一个交互式的ClickHouse客户端会话,允许你执行SQL查询。
持久化数据
为了确保ClickHouse数据在容器重启或删除后仍然存在,可以将数据目录挂载到主机文件系统:
docker run -d --name clickhouse-server --ulimit nofile=262144:262144 \ -p 8123:8123 -p 9000:9000 -p 9009:9009 \ -v /path/to/your/data:/var/lib/clickhouse \ clickhouse/clickhouse-server
- /path/to/your/data:替换为你希望在主机上存储数据的实际路径。
管理Docker容器
# 查看运行中的容器: docker ps # 停止容器: docker stop clickhouse-server # 启动已停止的容器: docker start clickhouse-server # 删除容器: docker rm clickhouse-server
通过以上步骤,你可以在Docker环境中轻松地安装和管理ClickHouse。使用Docker的好处在于可以快速部署、方便管理,并且易于在不同环境中保持一致性。
配置ClickHouse
配置文件通常位于 /etc/clickhouse-server/ 目录下,主要的配置文件是 config.xml 和 users.xml。在这里,你可以配置网络设置、用户权限、日志记录等。
根据需要修改配置文件后,重启ClickHouse服务以应用更改:
sudo service clickhouse-server restart
集群安装
安装和配置ClickHouse集群涉及多个步骤,包括准备服务器环境、安装ClickHouse、配置集群参数以及测试集群功能。以下是一个基本的步骤指南:
准备服务器环境
- 服务器数量:至少需要两台或更多服务器来组成一个集群。
- 操作系统:确保所有服务器运行相同的操作系统版本(如Ubuntu或CentOS)。
- 网络配置:确保所有服务器可以相互通信,配置好网络和防火墙。
安装ClickHouse
在每台服务器上安装ClickHouse,可以使用包管理器或Docker进行安装。以下是使用包管理器安装的步骤:
Ubuntu
sudo apt-get update sudo apt-get install -y apt-transport-https ca-certificates dirmngr sudo apt-key adv --keyserver keyserver.ubuntu.com --recv E0C56BD4 echo "deb https://repo.clickhouse.com/deb/stable/main/" | sudo tee /etc/apt/sources.list.d/clickhouse.list sudo apt-get update sudo apt-get install -y clickhouse-server clickhouse-client
CentOS
sudo yum install -y yum-utils sudo rpm --import https://repo.clickhouse.com/CLICKHOUSE-KEY.GPG sudo yum-config-manager --add-repo https://repo.clickhouse.com/rpm/stable/x86_64 sudo yum install -y clickhouse-server clickhouse-client
配置ClickHouse集群
在每台服务器上编辑ClickHouse配置文件,通常位于/etc/clickhouse-server/config.xml。
集群配置
定义集群节点:在config.xml中添加集群节点配置。
<remote_servers> <your_cluster_name> <shard> <replica> <host>node1_host</host> <port>9000</port> </replica> <replica> <host>node2_host</host> <port>9000</port> </replica> </shard> </your_cluster_name> </remote_servers>
配置ZooKeeper(如果使用):ClickHouse支持通过ZooKeeper进行分布式协调。
<zookeeper> <node> <host>zookeeper1_host</host> <port>2181</port> </node> <node> <host>zookeeper2_host</host> <port>2181</port> </node> </zookeeper>
复制配置(可选)
如果需要数据复制功能,可以在表定义中使用ReplicatedMergeTree引擎。
启动ClickHouse服务
在每台服务器上启动ClickHouse服务:
sudo service clickhouse-server start
验证集群配置
使用ClickHouse客户端连接到服务器,执行查询以确保集群配置正确:
clickhouse-client --host node1_host --query "SELECT * FROM system.clusters"
测试集群功能
创建分布式表并测试查询:
在每个节点上创建本地表:
CREATE TABLE local_table ON CLUSTER your_cluster_name ( id UInt32, value String ) ENGINE = MergeTree() ORDER BY id;
创建分布式表:
CREATE TABLE distributed_table ON CLUSTER your_cluster_name AS local_table ENGINE = Distributed(your_cluster_name, default, local_table, rand());
插入和查询数据:
INSERT INTO distributed_table VALUES (1, 'value1'), (2, 'value2'); SELECT * FROM distributed_table;
注意事项
- 同步配置:确保所有节点上的配置文件保持同步。
- 监控和日志:配置监控和日志,以便及时发现和处理集群问题。
- 备份和恢复:设计和实施备份策略以防止数据丢失。
ClickHouse的使用
ClickHouse建库建表
在ClickHouse中,创建数据库和表的过程相对简单,主要通过SQL语句来完成。
创建数据库
要在ClickHouse中创建一个新的数据库,可以使用CREATE DATABASE语句。数据库用于组织和管理表。
语法
CREATE DATABASE [IF NOT EXISTS] database_name;
- IF NOT EXISTS:可选参数,如果数据库已经存在,则不会报错。
- database_name:要创建的数据库的名称。
创建表
在创建数据库之后,可以在数据库中创建表。ClickHouse支持多种表引擎,可以根据具体需求选择合适的引擎。
基本语法
CREATE TABLE [IF NOT EXISTS] [database_name.]table_name ( column1_name column1_type, column2_name column2_type, ... ) ENGINE = engine_name [ORDER BY expression] [PARTITION BY expression] [PRIMARY KEY expression] [SETTINGS name = value, ...];
- IF NOT EXISTS:可选参数,如果表已经存在,则不会报错。
- database_name:数据库名称,如果省略,则在当前数据库中创建表。
- table_name:要创建的表的名称。
- column_name 和 column_type:定义表的列和数据类型。
- ENGINE:指定表的存储引擎,如MergeTree、Log 等。
- ORDER BY:定义数据的排序键,通常用于MergeTree 系列引擎。
- PARTITION BY:定义数据的分区策略。
- PRIMARY KEY:定义主键。
- SETTINGS:引擎的其他配置选项。
示例
创建一个使用MergeTree引擎的表:
CREATE TABLE IF NOT EXISTS example_db.example_table ( date Date, id UInt32, value String ) ENGINE = MergeTree() PARTITION BY toYYYYMM(date) ORDER BY (id, date);
- 该表包含三列:date、id 和 value。
- 使用MergeTree 引擎。
- 数据按toYYYYMM(date) 分区。
- 按(id, date) 排序。
注意事项
- 引擎选择:根据数据特性和查询需求选择合适的表引擎。
- 列类型:选择合适的数据类型以优化存储和查询效率。
- 安全性:确保在创建数据库和表时遵循安全性和权限管理的最佳实践。
分区和排序:合理的分区和排序可以显著提高查询性能。
数据如何同步到ClickHouse?
将业务数据库中的数据同步到ClickHouse可以通过多种方式实现,具体方法取决于数据的规模、实时性要求以及使用的技术栈。以下是几种常见的方法:
使用ETL工具
Apache Kafka + Kafka Connect
步骤:
- 配置Kafka:将业务数据库的变更数据捕获(CDC)流式传输到Kafka。
- 使用Kafka Connect:利用Kafka Connect的ClickHouse Sink Connector,将数据从Kafka导入到ClickHouse。
优势:适合实时数据同步,尤其是在需要高吞吐量和低延迟的场景。
Apache Nifi
步骤:
- 创建Nifi流:从源数据库提取数据。
- 转换数据格式:根据需要进行数据清洗和转换。
- 写入ClickHouse:使用Nifi的PutDatabaseRecord处理器将数据导入到ClickHouse。
优势:提供灵活的数据流设计和管理能力。
使用数据迁移工具
Apache Sqoop
步骤:
- 使用Sqoop从关系型数据库导出数据。
- 将导出的数据格式化为ClickHouse支持的格式(如CSV或TSV)。
- 使用ClickHouse的命令行工具或HTTP接口将数据导入。
优势:适合批量数据迁移。
自定义脚本
步骤:
- 编写脚本(如Python、Java等),使用JDBC或ODBC从源数据库读取数据。
- 进行必要的数据转换。
- 使用ClickHouse的HTTP接口或客户端API将数据写入。
优势:灵活性高,可以根据具体需求定制。
使用ClickHouse自带工具
- ClickHouse Local:可以用来在本地处理数据文件并将其导入到ClickHouse中。
使用第三方同步工具
- Altinity ClickHouse Sink Connector:专为将Kafka数据流同步到ClickHouse而设计。
- Debezium:用于捕获数据库变更并通过Kafka传输到ClickHouse。
注意事项
- 数据格式:确保数据格式与ClickHouse的表结构兼容,必要时进行数据清洗和转换。
- 数据一致性:对于需要保证数据一致性的场景,考虑使用事务日志或CDC技术。
- 性能优化:在大规模数据导入时,注意分区、索引和批量导入策略以优化性能。
- 安全性:确保数据传输过程中的安全性,特别是在使用网络传输时。
- 监控和错误处理:设置监控和日志,以便及时发现和处理数据同步过程中的错误。
根据具体的业务需求和技术环境,选择合适的同步方案可以有效地将数据从业务数据库同步到ClickHouse。
更新或删除ClickHouse数据
ClickHouse作为一个面向列存储的数据库,主要设计用于高效的读操作,因此在更新和删除数据方面与传统的行存储数据库(如MySQL、PostgreSQL)有所不同。ClickHouse目前不支持传统的UPDATE和DELETE操作,但可以通过其他方法来实现数据更新和删除。
更新数据
由于ClickHouse不支持直接的UPDATE操作,更新数据通常需要以下方法:
重新插入数据:
- 从表中选择需要更新的数据。
- 对数据进行必要的修改。
- 删除旧数据(见下文)。
- 将修改后的数据重新插入到表中。
使用 ALTER TABLE:
ALTER TABLE 支持修改列的属性或增加列,但不用于更新数据行。
删除数据
ClickHouse提供了一些方法来删除数据,但不支持直接的DELETE操作:
使用 ALTER TABLE…DELETE:
- 从ClickHouse 20.4版本开始,支持通过 ALTER TABLE…DELETE 语句删除符合条件的数据。
- 这种操作会标记数据为删除,并在后台异步清理。
ALTER TABLE table_name DELETE WHERE condition;
例如,要删除id为100的数据:
ALTER TABLE example_table DELETE WHERE id = 100;
使用 ALTER TABLE…DROP PARTITION:
- 可以删除整个分区的数据。
- 此操作通常用于基于分区的批量删除。
ALTER TABLE table_name DROP PARTITION partition_expr;
例如,删除某个日期分区的数据:
ALTER TABLE example_table DROP PARTITION '202201';
TTL删除策略:
使用 TTL(Time to Live)设置数据的过期时间,自动清理过期数据。
CREATE TABLE example_table (
date Date,
id UInt32,
value String
) ENGINE = MergeTree()
PARTITION BY toYYYYMM(date)
ORDER BY id
TTL date + INTERVAL 1 MONTH;
在此示例中,数据将在date列的值加一个月后自动删除。
注意事项
- 性能影响:ALTER TABLE…DELETE 和 ALTER TABLE…DROP PARTITION 操作会对性能产生影响,因为它们涉及到后台的合并和清理过程。
- 数据一致性:在删除或更新数据时,需要考虑数据的一致性和完整性。
- 备份和恢复:在进行大规模数据删除或更新之前,建议备份数据,以防止意外数据丢失。
尽管ClickHouse不支持传统的UPDATE和DELETE操作,但通过上述方法,可以实现数据的更新和删除操作。根据实际需求选择合适的方法,以便有效管理ClickHouse中的数据。
参考文档:


