图计算简介
图计算中的图英文是 Graph,用英文完整的表达就是 Graph Computing。图计算是研究客观世界当中的任何事物和事物之间的关系,对其进行完整的刻划、计算和分析的一门技术。简单概括一下,就是,图计算是人工智能的一个使能技术。我们可以大致将人工智能的基本能力分成三个部分,第一部分就是理解的能力,第二部分是推理的能力,第三部分就是学习的能力,简称 URL(Understanding,Reasoning,Learning)。而图计算是与 URL 息息相关的。举例来说,要对整个现实世界有一个客观、完整、全面的认识,那就需要一个理解的能力。图计算技术能够把任何事物之间的所有关系全部刻画出来,完整地描述出来。另外,在一些事物和事物之间,其关系并不是那么显性,需要通过一些推理才能够推导出来,图计算就能够通过推理的方式在事物中找到隐藏的一些关系,这个对于我们也非常有帮助。第三个就是图计算为人工智能提供的学习的能力,它能够将第一步中提到的理解刻画能力和第二步中的推理能力相结合,实现对任何一个事物的一个模式上的总结、演绎和描述。也就是说,图计算能够对事物进行抽象,这个抽象的过程就是人脑综合能力的一个重要体现。
图计算 vs 图数据库
图领域按照「应用场景」主要分为 2 部分:
- 图数据库:主要用于联机事务图的持久化技术,通常直接实时地被应用程序访问,和常见的联机事务处理(online transactional processing, OLTP)数据库是一样的。
- 图计算引擎:主要用于离线图分析技术,通常按照一些列步骤执行,它们可以和其他大数据分析技术看作一类,比如数据挖掘和联机事务分析(online analytical processing,OLAP)。
图数据库
图数据库,是图数据库管理系统的简称,它是一种在线的图数据库管理系统,支持对图数据模型的增、删、改、查(CRUD)方法。图数据库一般应用于事务(OLTP)系统中,所以在研究图数据库技术时需要多加考虑 2 个特性:
- 底层存储:底层存储分为原生和非原生。某些系统是(Neo4j、OrientDB)为了存储和管理图而专门设计;而也有一些图数据库(比如 Titan、InfiniteGraph)是将图序列化,然后存储到其他数据库中。
- 处理引擎:一些定义要求图数据库使用「免索引邻接」,这意味着,关联节点在数据库里是物理意义上的“指向”彼此。
相比于传统的关系型数据库和其他 NoSQL 数据库,免索引邻接带了了非常巨大的性能优势,而且我们得到的模型更简单,更具表现力。
图数据库的代表:Neo4j
Neo4j 是一款独立的图数据库产品,偏向于存储和查询。图存储是说它能装那些关联关系比较复杂,实体之间的连接很丰富,就像一张网或一张图的数据。比如社交网络,知识图谱,金融风控等领域的数据。图查询是说它擅长从某个点或某些点出发,根据特定条件在复杂的关联关系中找到目标点或边。比如说在社交网络中找到我三步以内能认识的人,这些人可以认为是我的潜在朋友。这种数据量限定在一定范围内,能短时完成的查询就是所谓的 OLTP 操作。
图计算引擎
图计算引擎技术,偏重于全局查询,通常都对于对与批处理大规模数据做过优化。只有一部分图计算引擎有自己的存储层,其他的都只关注与如果处理外部传入的数据,然后返回结果到其他地方保存。大多数的图计算引擎都是基于 Google 发布的Pregel 白皮书,白皮书中主要介绍了 Google 如何使用图计算引擎计算网页排名。
图计算的代表:Hadoop/Giraph,Spark/GraphX
GraphX 是一个 Spark 的一个子模块,它是一个图计算系统,也可以说是图分析系统,它不去承担数据存储的职责。图分析和图查询的区别在于:图分析往往是整张图的操作,而且可能是多次迭代;而图查询只涉及图的一部分,且只需一次。对用户而言最直观的感受是:图分析很慢,图查询很快。这种涉及到整图或大量节点/边,较长时间才能完成的查询就是所谓的 OATP 操作。
Giraph 是一个迭代的图计算系统。基于 Hadoop 而建,将 MapReduce 中 Mapper 进行封装,未使用 reducer。在 Mapper 中进行多次迭代,每次迭代等价于 BSP 模型中的 SuperStep。一个 Hadoop Job 等价于一次 BSP 作业。
Facebook 针对图数据处理对 Apache Giraph 和 Spark GraphX 的比较。他们发现在通常情况下 Giraph 能够更好地处理生产级负载,而 Spark GraphX 提供的几个特性,能使图数据处理解决方案的开发更简单。该性能测试有如下关键发现:
- Giraph 即使在较小规模的图数据集上执行得也更好些。Giraph 的内存使用也更加高效。
- GraphX 支持以 SQL 样式的查询从 Hive 中读取图,支持任意列转换。使用 shell 环境中的 Scala 是一种测试 GraphX 简单应用的简便方式。
最后,该团队总结说,GraphX 不足以支持他们图处理负载的扩展性和性能需要。
图计算系统和图数据库系统有很多相似之处,但是一般来说,二者有如下区别:
| 图计算系统 | 图数据库 | |
| 实时性 | offline | online |
| 负载类型 | graph algorithms | query,一般要提供查询语言 |
| 输入数据格式 | 抽象图 | 业务图 |
| 优化的重点 | 迭代式图遍历 | 高并发写入和查询 |
| 事务和一致性 | 不要求 | 高要求 |
| 容错性 | 考虑较少 | 需要考虑,特别是分布式模式下 |
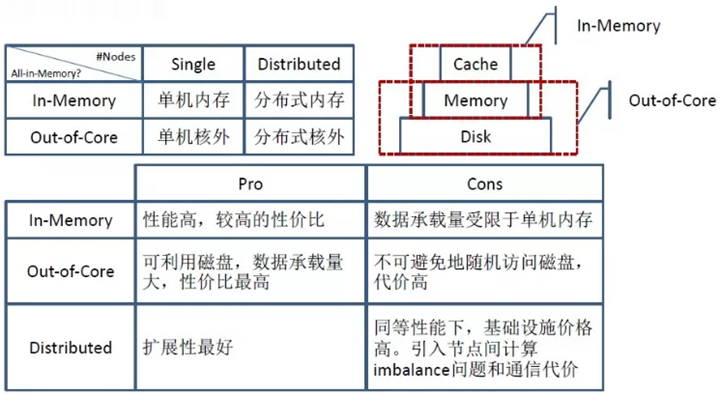
图计算的分类
单机内存图处理系统
此类图计算系统单机运行,可直接将图完全加载到内存中进行计算。但是单机的计算能力和内存空间总是有限,故只能解决较小规模的图计算问题,比较有代表性的系统有 2013 年发布的 Ligra 和 Galois, 以及 2015 年发布的 GraphMat 和 Polymer。
其中 Ligra 提出了根据图形稠密情况自适应的切换计算模式,并提供了一种基于边映射,顶点映射以及顶点集映射的并行编程算法。Galois 使用 DSLs(domain-specific languages)写出更复杂的算法完成图分析工作,并发现当输入图是道路网络或者具有较大直径的图时能获得一个数量级的性能提升,在现有的三种图 DSLs 基础上提供了轻量级的 API,简化了图算法的实现。GraphMat 是第一个对多核 CPU 进行优化的以顶点为编程中心的轻量级图计算框架,为用户和开发者提供了个友好的接口。Polymer 则是针对在 NUMA 特性的计算机结构上运行图算法的优化,作者发现无论是随机或者交错地分配图数据都会重大的束缚数据的本地性和并行性,无论是 intra-node 还是 inter-node,顺序访存都比随机访存的带宽高的多。
单机核外图处理系统此类图计算系统单机运行,但是将存储层次由 RAM 拓展到外部存储器如 SSD,Flash,SAS,HDD 等,使其所能处理的图规模增大。但受限于单机计算能力和核外存储系统的数据交换的带宽限制也无法在可接受的情形下处理超大规模的图数据。典型的图计算系统有 GraphChi, TurboGraph, X-Stream, PathGraph, GridGraph 和 FlashGraph。
这些系统在最大化磁盘顺序读写,选择调度和同异步计算模式等方面做出了重要探索。TurboGraph 和 FlashGraph 主要采用分页方式分割图来提高内外存的数据交换性能。其中 GraphChi 采用了传统的以顶点为中心的编程模型,计算模式为隐式 GAS。它使用了名为 shard 的核外数据结构来存储边,而将顶点划分为多个连续的区间。提出了一种基于并行滑动窗口(PSW)模型达到对存储在磁盘上的图数据最大的顺序读写性能。但是构建 shard 是需要对边按源顶点排序,这样耗费了大量的预处理时间,PWS 对计算密集型的算法更有利。另外在构建子图时出现大量的随机访存现象,通过顺序地更新子图内有共享边顶点来避免数据争用问题。
X-Stream 则介绍了一种以边为中心的编程模型。在 scatter 阶段以流的形式处理每条边和产生传播顶点状态更新集,在 gather 阶段它以流的形式处理每一个更新并应用到对应的顶点上。自然图中顶点集远远大于边集,所以 X-Stream 把顶点存储在高速存储设备(Cache 对于 RAM,RAM 对于 SSD/Disk)中表现为随机读写,把边集和更新集存于低速存储设备中表现为最大程度的顺序读写。X-Stream 流式访问图数据,其流划分相比于 GraphChi 无需对 shard 内的边进行排序大大缩短了预处理时间,并使用 work-stealing 避免 Scatter-Gather 导致的线程间负载不均衡的问题。但是 X-Stream 在计算过程中,每轮迭代产生的更新集非常庞大,接近于边的数量级;而且需要对更新集中的边进行 shuffle 操作;缺乏选择调度机制,产生了大量的无用计算。
GridGraph 将顶点划分为 P 个顶点数量相等的 chunk,将边放置在以 P*P 的网格中的每一个 block 中,边源顶点所在的 chunk 决定其在网格中的行,边目的顶点所在的 chunk 决定其在网格中的列。它对 Cache/RAM/Disk 进行了两层级的网格划分,采用了 Stream vertices and edges 的图编程模型。计算过程中的双滑动窗口(Dual Sliding Windows)大大减少了 I/O 开销,特别是写开销。以 block 为单位进行选择调度,使用原子操作对保证线程安全的方式更新顶点,消除了 X-Stream 的更新集和 shuffle 阶段。其折线式的边 block 遍历策略不能达到最大化的 Cache/Memory 命中率。
分布式内存图处理系统
此类图计算系统将图数据全部加载到集群中的内存中计算,理论上随着集群规模的增大其计算性能和内存容量都线性增大,能处理的图数据也按线性扩大。图分割的挑战在分布式系统愈加明显,再加上集群网络总带宽的限制,所以整体性能和所能处理的图规模也存在一定的缺陷。这类图计算系统主要包括同步计算模型的 Pregel 及其开源实现 Piccolo, 同时支持同步和异步的系统 PowerGraph, GraphLab 和 GraphX。PowerSwitch 和 PowerLyra 则对 PowerGraph 做了改进, Gemini 则借鉴了单机内存系统的特性提出了以计算为核心的图计算系统。
Pregel 是首个采用 Vailiat 的 BSP 计算模型的分布式内存图计算系统,计算由一系列的“超步”组成,在一个超步内并行地执行用户自定义函数。Pregel 在编程模型上遵循以图顶点为中心的模式,在超级步 S 中会汇总从超级步 S-1 中传递过来的消息,改变顶点自身的状态,并向其它顶点发送消息,这些消息经过同步后会在超级步 S+1 中被其它顶点接受并处理。允许通过增加/删除点和边改变图的拓扑结构,在对同步消息进行了聚合优化。但是有些算法在 BSP 同步模型下收敛性很差,采用随机 hash 切边法带来了巨大的网络通信开销。
GraphLab 主要是针对 MLDM 应用开发的图计算系统,故先详细分析了 MLDM 算法的特性,并对图计算中数据一致性模型做了详细阐述。PowerGraph 针对 power-low 特性的自然图详细分析工作负载,图分割,通信,存储和计算等各方面带来的挑战。提供了完善的图分割数学理论支撑,证明切点法比切边法能提高一个数量级的图计算性能。故 PowerGraph 使用 p-way 切点法,采用了以顶点为中心的 GAS 编程模型,增加了细粒度并发性同时支持同步和异步模型。但它不支持图的动态修改,容错机制未能充分利用顶点副本。
PowerLyra 和 PowerSwitch 分别从图分割和同异步模型两方面对 PowerGraph 进行了改进。PowerLyra 提出了一种混合图分割方法 hybrid-cut,即出入度高的顶点采用切点法反之出入度低的顶点采用切边法,经过试验对比性能提高了至少 1.24 倍。PowerSwitch 首先分析了同步和异步计算模型在网络通信和算法收敛速度的特征后提出了一种混合图计算模型 Hsync,通过一系列的运行时分析和定量计算可动态的切换计算模式,相比于 PowerSwitch 有一定的性能提升。
Gemini 在单机内存图计算系统的高效性和分布式内存图计算系统良好的伸缩性之间找到差异性,而提出的以计算为中心的图计算系统。它针对图结构的稀疏或稠密情况使用于与 Ligra 相同的自适应 push/pull 方式的计算,并在现代 NUMA-aware 特性的内存中采用基于 chunk 的图划分进行更细粒度的负载均衡调节。实验表明 Gemini 的性能得到重大提升了,其性能至少能达到现有已知分布式图处理系统的 8.91 倍。可见在单机上从内存结构和 CPU 架构等更细层面提高图计算的能力对整体集群的图数据处理性能的改善也很显著。
分布式核外图处理系统
此类图计算系统将 Single-machine out-of-core systems 拓展为集群,能够处理边数量级为 trillion 的图,目前仅有 2015 年发布的 Chaos。Chaos 是对 X-Stream 系统的拓展,分别设计了计算子系统和存储子系统。它的主要贡献表现在:是第一个拓展到多机核外存储结构的图计算系统;采用简单的图分割方案,即不强调数据的本地性和负载均衡,而是通过存储子系统达到核外存储的高效顺序读写;使用 work-stealing[26] 机制实现动态负载均衡。但是 Chaos 存在设计缺陷,随着集群规模的伸缩网络将会成为系统瓶颈;简单的拓展未优化的 X-Stream,其更新集依然很庞大与边量级相当;计算与存储独立设计增加了系统的复杂性和不可避免的通信开销;存储子系统为了使存储设备时刻忙碌而占用了较多的计算资源。
图计算系统的困难性
本质上是高性能并行计算的问题。
高性能来自于如下 4 各方面的匹配:
- 要解决的问题
- 算法设计
- 用来运行算法的框架
- 用来运行框架的硬件
图计算带来的挑战:
- 计算量 encoded 再图结构中(纯静态 graph partition 效果差)
- 图结构无规律(很难拿 partition graph,造成 load imbalance)
- 局部性差(难以利用 cache,频繁访存)
- 数据访问/计算 ratio 高(频繁访存)
常见图计算系统
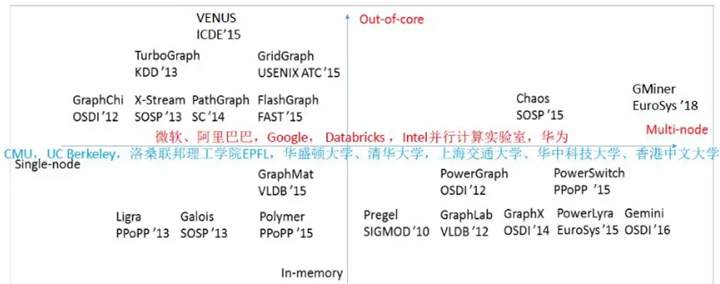
常见的图计算系统及其主要贡献:
| 图计算系统 | 主要贡献 |
| Pregel | 1、Bulk-Asynchronous-Processing 模式的典型实现
2、提出 Vertex-Centric 计算模型 3、使用 Combiner & Aggregator 减少通信 |
| Ligra | 1、提出在 dense 和 sparse 模式下分别使用 pull 和 push
2、Coordinated Scheduling |
| Polymer | 1、 提出使用 NUMA 来提升性能 |
| GraphChi | 1、提出 Parallel-Sliding-Window 来提高缓存命中率
2、 Incremental-computation with dynamic graphs |
| GraphX | 1、Build on RDD,表达能力强
2、Easy ETL intergration |
| XStream | 1、Edge-centric
2、streaming completely unordered edge lists rather than performing random access |
| PowerGraph | 1、图的 power-law 特性
2、GAS 3、Vertex-partitioning,3 种边分区方法:Random、Coordinate Greedy、Oblivious Greedy 4、3 execution mode:syn、async、async+serializable 5、Delta-cache,caching partial sum |
| Polymer | 1、differentially allocates and places topology data, application-defined data and mutable runtime states of a graph system according to their access patterns to minimize remote accesses
2、for some remaining random accesses, Polymer carefully converts random remote accesses into sequential remote accesses, by using lightweight replication of vertices across NUMA nodes |
| Galois
|
1、supports very fine-grain tasks
2、a topology-aware work-stealing scheduler 3、autonomous, speculative execution 4、allows application-specific control of task scheduling policies. |
| Gemini | 1、Extend pull/push mode in SMP to distributed environment
2、Locality-preserving Chunk-based partition 3、Dual compression vertex indices 4、fine-grained work-stealing |
| GMiner | 1、computation-intensive and memory-intensive graph mining workload
2、streamline tasks so that CPU computation, network communication and disk I/O can process their workloads without waiting for each other |
JoyGraph 简介
JoyGraph 是京东自研的单机共享内存式(Shared-Memory-Processing)图计算系统,主要特点为:
- 单机 Shared-Memory-Processing
- 增量数据 aware
- Vertex-Centric 编程模型
- Mult-Level Vertex & Edge Partitioning
- Work-Stealing & Selective-Scheduling
- Push/Pull 双模式自适应
- NUMA-aware
- 内置多种算法包
- 算法开发者友好的 API
- 可定制性(Parse/Initialization/Algorithms 等过程)
- 与”图灵”平台集成
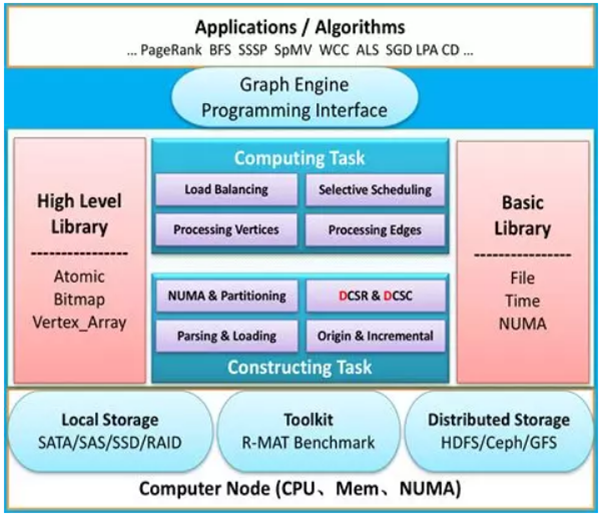
JoyGraph 实现
架构以及核心数据结构
- 以顶点为中心构造,邻接表出/入边数组和出/入边索引数组
- 顶点区间分割
- 辅助 Bitmap 和 Vertex_Array
- Multi-Level Partition (详见”负载均衡”)
NUMA-Aware
有研究表明,NUMA (Non-Uniform-Memory-Access) 架构下,local (访问本地 NUMA-node 的本地内存) 数据访问带宽是 remote (访问远程 NUMA-node 的内存) 的 2 倍,延迟是 remote 的 1/2。支持 NUMA 对提高图计算系统性能至关重要,NUMA 影响了对图的构造和运行时的动态负载均衡。
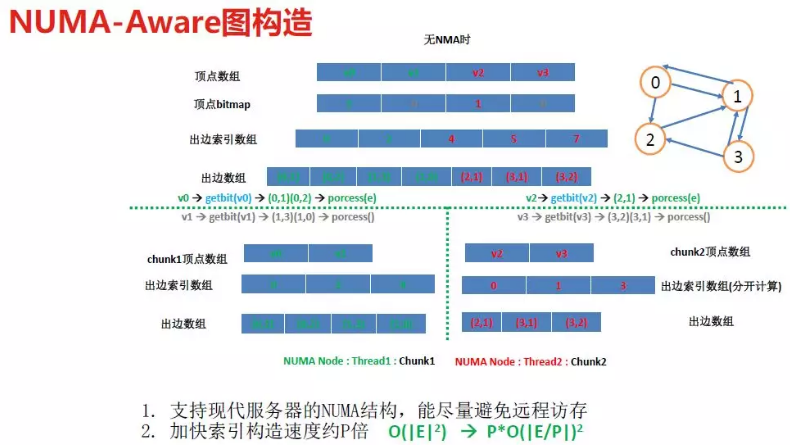
以上是图的构造过程,JoyGraph 框架是如何执行用户自定义的 Vertex-Centric 算法?各数据结构在算法迭代过程中是如何起作用的呢?
图计算执行过程
典型的 Vertex-Centric 执行模式,用户自定义的顶点更新函数,更新顶点和其邻居的状态,并 vote 活跃状态。JoyGraph 框架内部进行了并发处理。
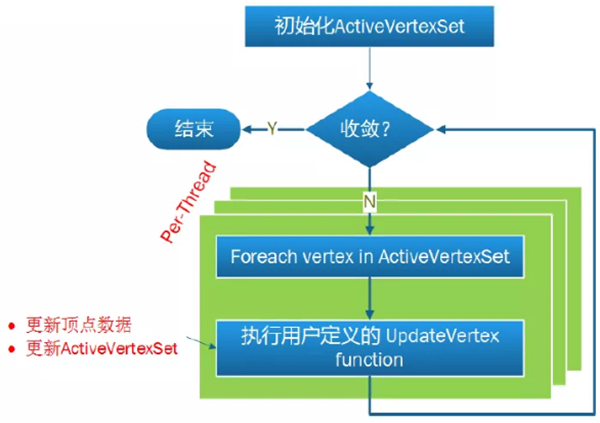
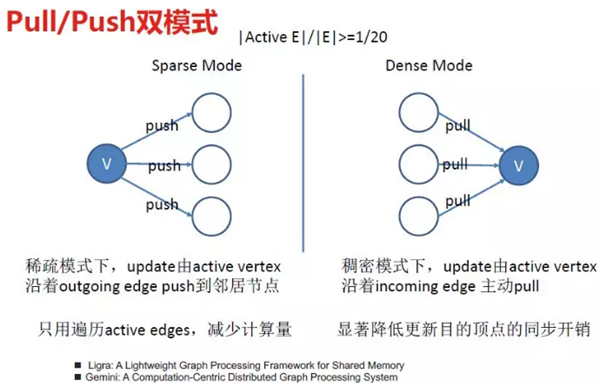
在执行用户自定义的 UpdateVertex 函数时,由于不同的顶点的出入度不同,沿着出边还是入边更新,代价是不同的,push/pull 模式用来自适应地选择最高效的执行方式。
push/pull 双模式
负载均衡
图遍历的过程要充分利用 NUMA 架构,发挥多 cpu 和多核的计算能力。JoyGraph 采用静态和动态负载均衡来实现。
静态负载均衡:两阶段顶点集划分
- 一次划分:首先依据每个 Socket (NUMA-Node) 分摊到相等数量的边集的标准,将顶点集静态分配到每个 Socket(顶点 chunk)。由于每个顶点的出入度不同,每个 Socket 级别分到的顶点 chunk 大小不一。
- 二次划分:再按照每个 Socket 内部每个 Core (=Thread 个数) 分摊到相等数据量的边集的标准,再次将顶点集二次划分给每个 Socket 内部的每个 Core,同理,每个 Core 分到的顶点 chunk 一般也大小不一。
以上静态划分,并不能完全保证运行时每个 Core 的负载相同,需要同时采用运行时动态负载均衡措施以充分利用 cpu:
- Work-Stealing: JoyGraph 每个 Thread (每个 Core) 有 2 种状态:Working 和 Idle,Idle 时可以 steal 其他 Core 的负载,steal 负载的粒度可根据图活跃边集的稠密程度来动态调节。
- NUMA 架构下,由于 NUMA-node 间带宽和延迟的代价不同,优先 steal 同 Socket (NUMA-node) 下其他 Core 的任务,然后再按照顺时针 (逆时针) steal 其他 Socket 的任务。
小结和展望
JoyGraph 目前已实现:lpa、louvain、cc、scc、wcc、mssp、apsp 等算法 (持续扩充中),并提供自定义算法开发接口,包括 load&parse&filter、graph initialization、dense_vertex_update、sparse_vertex_update、IO 等过程均可自定义。未来 Joygraph 将在如下方向上持续发力:
- 自研图数据库引擎,将图计算内置到图数据库中,实现 OLAP
- 图计算集成图数据可视化和调度服务,实现“流程即服务”
- 丰富算法包并持续优化系统性能
- 提供在线 Notebook 式的交互式图算法开发和分析工具,提供从图数据探索、图算法开发、图算法部署上线的一站式平台,并集成到“图灵”平台中。


