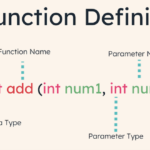
函数的基本概念 在C语言中,函数是用于完成特定任务的独立代码块。函数可以带有参数(即输入),并且可以返回一个值(即输出)。C语言为我们提供了很多内建的函数,如printf(),scanf()等,同时也允许我们自定义函…
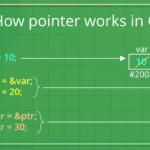
指针的基本概念 在C语言中,指针是一个非常重要的概念。指针本质上是一个变量,其存储的是值的地址,而不是值本身。这意味着,通过指针,我们可以直接访问或者操作内存中的数据。 理解指针的关键在于理解"指针是…
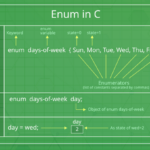
在C语言中,枚举(enum)是一种用户自定义的数据类型,可以让代码更具可读性。枚举创建了一个新的类型,其值由你设定的一组命名的整数常量(称为枚举器)组成。 枚举类型的主要用途是使代码更具可读性和维护性。…
什么是位段(位域)? 位段(bit-field)是C语言中的一种数据结构,它可以让你指定一些连续的位来存储数据。位段通常用于设计一些需要大量标记位的数据结构,例如硬件寄存器或协议数据包。 位段在结构体中定义,位…

当我们需要在C语言中定义一个可以存储不同数据类型的变量时,可以使用共用体(Union)。共用体是一种特殊的数据类型,它允许不同的数据类型共享同一块内存空间。在内存中,共用体的大小等于它所包含的最大成员的大小…

在C语言中,结构体(Structures)是一种用户定义的数据类型,它允许你组合不同类型的数据(如整型、浮点型、数组、其他结构等)。 结构体的主要用途是把有逻辑关联的一组数据存储在一起。例如,你可能会使用结构…

在C语言中,字符串是以空字符'\0'结尾的字符数组。在C语言学习之数组中有提到过。在C语言编程中,我们经常需要对字符串进行操作,如定义、赋值、输入输出、连接、比较等。 定义与初始化 定义一个字符串,我们需要…
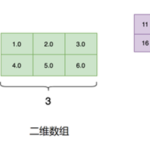
在C语言中,数组是由相同类型的数据元素构成的数据结构。这些元素在内存中连续存放,每个元素都可以通过索引(数组下标)进行访问。 下面是在学习和使用数组时需要注意的一些重要知识点: 数组的声明:C语言中的…
在学习编程语言的时候经常有一些教程指导如何编写一个博客程序或CMS系统,但整体内容偏简单,核心点集中在如何增删改查的实现,并没有达到一个“可用”状态。 不再流行的博客 依稀记2005年左右,博客非常的流行,从…

在下载安装Linux或Linux软件时,有时需要选择不同的架构的版本,由于对CPU架构缺乏一定的了解,可能会导致一些混乱,今天就抽空整理下。 什么是CPU架构? CPU架构,也称为微处理器架构,CPU架构(Central Pro…