什么是位段(位域)?
位段(bit-field)是C语言中的一种数据结构,它可以让你指定一些连续的位来存储数据。位段通常用于设计一些需要大量标记位的数据结构,例如硬件寄存器或协议数据包。

位段在结构体中定义,位段的声明和变量类似,但是后面要跟一个冒号和一个数字,这个数字表示使用的位数。
例如,下面的代码定义了一个结构体,其中包含了几个位段:
struct {
unsigned int is_keyword:1; //使用1位存储
unsigned int is_extern:1; //使用1位存储
unsigned int is_static:1; //使用1位存储
} flags;
在上面的例子中,flags结构体中的每个字段都只占用了1位空间。因此,整个flags结构体实际上只占用了一个字节的空间。
位段主要有以下优点:
- 节约存储空间。如果你只需要几个位来存储某些信息,使用位段可以节省大量的存储空间。
- 提高效率。对位段的操作通常比对整个变量的操作要快。
但是位段也有一些限制和不确定的行为,例如:
- 位段的类型必须是int,unsigned int或signed int。
- 位段的大小不能大于类型的大小。例如,不能为int类型的位段指定32位以上的大小。
- 不同编译器可能会有不同的位段布局方式,这可能会导致跨平台兼容性问题。
- 位段不能取地址。
位段(位域)的使用
在C语言中,位段通常在结构体中声明。声明位段的语法为:类型 变量名:位数;。其中,”类型”是int、signed int或unsigned int,”变量名”是你要命名的位段名称,”位数”是你要为该变量分配的位数。
以下是一个位段声明的例子:
struct BitField
{
unsigned int is_keyword:1; //1位
unsigned int is_extern:1; //1位
unsigned int is_static:1; //1位
};
在这个例子中,定义了一个名为BitField的结构体,其中包含3个位段:is_keyword,is_extern和is_static,每个位段都分配了1位。
你可以像操作普通的结构体成员一样操作位段。例如,可以如下赋值:
struct BitField flags; flags.is_keyword = 1; flags.is_extern = 0; flags.is_static = 1;
注意,位段的位数通常不能大于其类型的大小。也就是说,对于unsigned int类型的位段,位数通常不能超过32(这取决于你的系统中int的大小)。
然后我们可以检查这些位段的值:
printf("is_keyword: %d\n", flags.is_keyword);
printf("is_extern: %d\n", flags.is_extern);
printf("is_static: %d\n", flags.is_static);
这将会打印出:
is_keyword: 1 is_extern: 0 is_static: 1
注意,尽管位段在许多情况下都非常有用,但它们也有一些限制。例如,你不能获取位段的地址,因为它们并不一定占用完整的内存地址。此外,位段的布局(也就是它们在内存中的位置)可能会因编译器和平台的不同而不同。
位段(位域)的存储
在C语言中,位段的存储是非常紧凑的。也就是说,几个位段变量(不论它们的类型)可以连续地存储在一个字节中,或者跨越几个字节。这取决于被声明的位段变量的数量,以及每个位段变量被分配的位数。
下面是一个例子来说明位段的存储方式:
struct BitField {
unsigned int a:1; //分配1位
unsigned int b:3; //分配3位
unsigned int c:4; //分配4位
};
在这个例子中,a、b和c都被定义为位段的成员,并被分配了1位、3位和4位。因为他们的总位数(1+3+4)等于8位(也就是一个字节),他们会被连续存储在同一个字节中。
如果一个结构体中的位段总位数超过一个字节(即8位),那么它们就会被存储在连续的字节中,需要注意的是,这个存储方式是与特定的硬件和编译器相关的,可能会有所不同。有些编译器可能会在位段之间或者位段和其他结构体成员之间插入填充位。因此,在跨平台的程序中使用位段时需要特别小心。
位段(位域)内存对齐
内存对齐是计算机硬件对内存访问的一种优化。它的基本原理是:对于特定的硬件平台,访问地址对齐的数据(比如,地址是某个值的倍数)通常比访问非对齐的数据更快。因此,编译器会尽量按照某种规则来对内存进行对齐。
位段的内存对齐规则取决于特定的编译器和硬件平台。通常,位段在一个int或unsigned int的边界上开始,当位段的总大小超过int的大小时,将会开始一个新的int。也就是说,如果一个位段不能完全适配当前的int,那么它将会从下一个int开始。这可能会导致一些空间浪费。
下面是一个例子:
struct BitField {
unsigned int a:4;
unsigned int b:12;
unsigned int c:18; //这个位段将从一个新的int开始
};
在这个例子中,a和b的总位数是16,这正好是一个int的大小(假设int的大小是16位)。然后,c的位数是18,这超过了当前int的剩余空间,因此它将会从下一个int开始。这导致了当前int的剩余空间被浪费。
需要注意的是,这只是一种常见的规则,并不是所有的编译器和硬件平台都会这样做。具体的规则取决于编译器的实现,可能会有所不同。
匿名位段
在C语言中,你可以创建一个没有名称的位段,这被称为匿名位段。匿名位段主要用于两个目的:位填充和类型控制。
以下是一个匿名位段的例子:
struct BitField {
unsigned int a:4; //分配4位
unsigned int :0; //匿名位段,位宽为0
unsigned int b:4; //分配4位
};
在这个例子中,a和b之间有一个匿名位段,其位宽为0。这个匿名位段告诉编译器在a和b之间进行边界对齐。也就是说,b将在下一个unsigned int的边界上开始。
另一方面,匿名位段也可以用于类型控制。你可以在同一结构体中使用不同类型的位段,例如:
struct BitField {
unsigned int a:4; //unsigned int类型,分配4位
int :0; //匿名位段,位宽为0
signed int b:4; //signed int类型,分配4位
};
在这个例子中,a和b是unsigned int和signed int类型的位段。匿名位段在这两个位段之间提供了一个分隔,这样就可以在同一结构体中使用不同类型的位段。
需要注意的是,匿名位段不能被访问,它们只是用于控制其他位段的布局。
位段的存储规则
位段在内存中的存储遵循以下规则:
- 若相邻的位段成员的类型相同,且其占用二进制位数未超过该类型可容纳的范围,则后面的成员紧接着前一个成员进行存储;
- 若相邻的位段成员的类型相同,但其占用二进制位数超过该类型可容纳的范围,则后面的成员从该类型占用空间之后的内存单元开始存储;
- 若相邻的位段成员的类型不同,则取决于编译器的实现。对于GCC编译器会尽量利用空闲的位对数据进行存储;
- 若位段之间定义有匿名位段成员,则匿名位段成员指定的空闲位不用于后续成员的数据存储;
考虑如下结构体,该结构体内的定义几乎使用到了上面提到的所有规则:
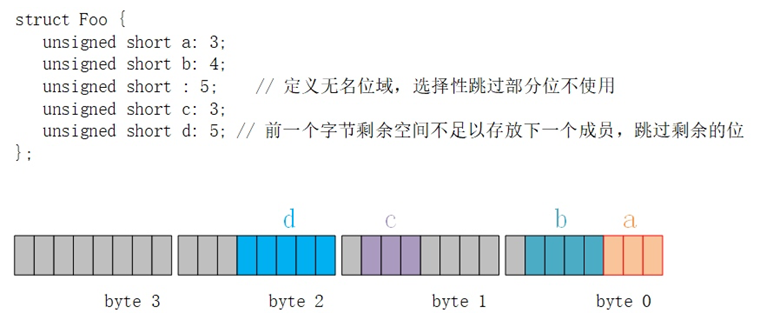
- 对于成员a、b、c再加上匿名成员占用的总内存空间并未超过unsigned short类型空间的大小,因此在unsigned short类型可容纳的范围内,这些成员可以紧挨着存放;
- 当后续存放成员d时,前一个unsigned short类型数据剩余的空间已不足以容纳d,因此选择下一个内存单元进行存放。
特别地,如果定义上述结构体中匿名成员占用的位数为0,那么对于第一个unsigned short类型数据在除被a、b占用区域的其它剩余空间都将不会被使用,则成员c需要从byte2开始进行存储。
现在考虑相邻位段成员类型不同的情况,定义如下结构体并画出其在内存中的布局如下(这个结果基于gcc编译器):
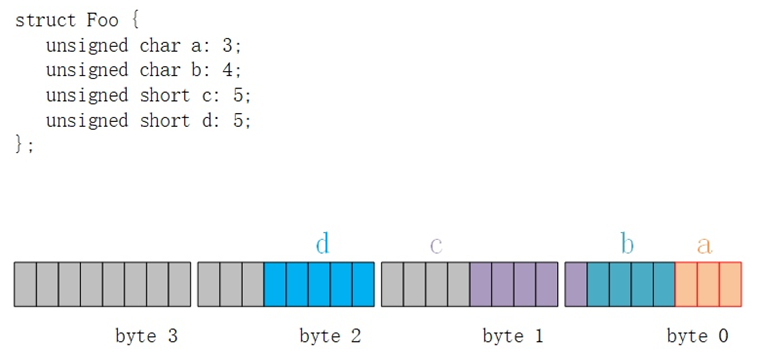
GCC编译器会尽可能地利用空闲的内存位进行位段成员的存放,这里有一点需要注意的是,尽管对于第一个unsigned char类型可容纳的单字节范围在存放完成员a和b后,剩余的一位已不足以存放成员c,但是GCC编译器仍然将这一位分配给了c。
位段与大小端
系统的大小端差异会同时牵涉到字节序和比特序问题,对于结构体位段这种会涉及比特位层面数据的操作,几乎需要时刻考虑平台大小端的差异。结构体内位段成员在大小端系统上的内存分配规则如下:
- 无论是大端或小端模式,位段的存储都是由内存低地址向高地址分配,即从低地址字节的低位bit开始向高地址字节的高位bit分配空间;
- 位段成员在已分配的内存区域内,按照机器定义的比特序对数据的各个bit位进行排列。即在小端模式中,位段成员的最低有效位存放在内存低bit位,最高有效位存放在内存高bit位;大端模式则相反。
为了说明上述的规则,参考如下代码:
struct Foo2{
unsigned short a:1;
unsigned short b:3;
unsigned short c:4;
unsigned short d:4;
unsigned short e:4;
};
void test_foo2(void)
{
union{
struct Foo2 foo;
unsigned short s_data;
}val;
val.foo.a=1;
val.foo.b=3;
val.foo.c=5;
val.foo.d=7;
val.foo.e=15;
printf("val is 0x%x.\n",val.s_data);
return;
}
运行上述程序:
- 在小端设备上的输出的结果为:0xf757;
- 换成大端设备,程序的运行结果为:0xb57f。
我们画出程序所定义结构体位段成员在内存中的存储布局如下所示(因为平时多数都是在使用小端机器,在此有意将字节的顺序和字节内的位顺序进行颠倒,方便对比):
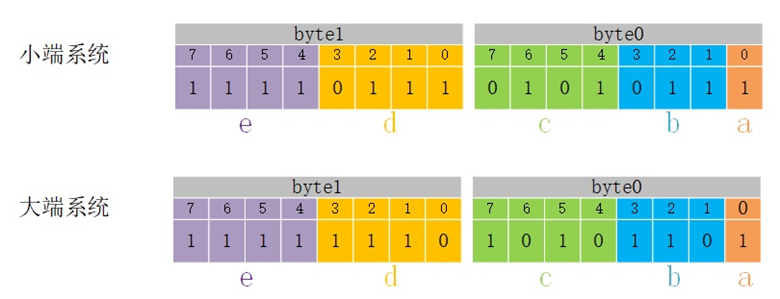
为了更便于理解位段在内存中的排列规则,建议将位段成员内存空间的分配和解析分开来看:
- 第一步先考虑内存空间的分配,从上图中可以看到,不论大小端都是从内存地址的低位开始;
- 当位段成员占用空间确定之后,考虑于位段成员数据位的排布,可以看到小端系统从低bit位开始存放数据,这是符合我们预期的,而大端设备则恰恰相反,大端系统从高bit位开始存放数据,因此在大端设备中,我们需要转换下思维从内存的高位开始解析数据位。
位段的使用场景
位段在几种特定的编程场景中非常有用:
- 硬件编程:硬件设备通常通过特定的寄存器来控制,这些寄存器的每一位都有特定的含义。使用位段,我们可以直接访问和控制这些位。
- 内存优化:当内存空间有限时,使用位段可以帮助我们更有效地利用内存。例如,如果你只需要存储0到15的数字,那么可以使用一个4位宽的位段,而不是一个完整的int或short。
- 协议实现:许多通信协议都定义了特定的位级别的结构。例如,网络数据包的头部通常包含一些特定的位,表示诸如优先级、标识、偏移等信息。使用位段可以直接映射这些结构,使得协议的实现更加直观。
- 数据打包:当需要将多种数据打包在一起时,可以将它们的各个部分作为一个位段打包,这样可以更有效地使用存储空间,并且可以直接操作数据的各个部分。
需要注意的是,尽管位段在这些场景中非常有用,但它们也有一些限制和缺点。例如,你不能获取位段的地址,因为它们并不一定占用完整的内存地址。此外,位段的布局(也就是它们在内存中的位置)可能会因编译器和平台的不同而不同。因此,在使用位段时,你需要仔细考虑这些因素。
位段使用实例
位段在许多情况下都非常有用,例如在需要精确控制内存使用的情况下,或者在硬件编程中,当需要访问和控制硬件的特定位时。
以下是一个位段使用的实例,它描述了一个RGB颜色模型的结构:
struct RGB{
unsigned char r:8;//红色成分
unsigned char g:8;//绿色成分
unsigned char b:8;//蓝色成分
};
struct RGB myColor;
//设置颜色
myColor.r=255;
myColor.g=128;
myColor.b=64;
//打印颜色
printf("Red=%d,Green=%d,Blue=%d\n",myColor.r,myColor.g,myColor.b);
在这个例子中,我们创建了一个名为RGB的位段,包含r(红色)、g(绿色)和b(蓝色)三个成分。每个成分都被分配了8位,对应于一个unsigned char。这样,我们就可以用3个字节(而不是3个unsigned char,总计3字节)来表示一个RGB颜色。
然后,我们创建了一个RGB类型的变量myColor,并设置了它的r、g和b成分。最后,我们打印了myColor的颜色。
使用位段,我们可以更精确地控制内存使用,并且可以直接操作特定的位。


