在C语言中,结构体(Structures)是一种用户定义的数据类型,它允许你组合不同类型的数据(如整型、浮点型、数组、其他结构等)。

结构体的主要用途是把有逻辑关联的一组数据存储在一起。例如,你可能会使用结构体来表示一个学生的信息(如姓名、年龄和成绩)。在C语言中,你可以使用关键字struct来定义一个结构体。
结构体的定义
在C语言中,结构体是由多个不同类型的数据元素组成的数据类型。结构体可以包含任意类型的数据元素,例如:整型、浮点型、字符型、数组,甚至是其他结构体。结构体常常用于表示一些复杂的数据模型,在真实世界的问题中非常有用。
以下是定义结构体的基本语法:
struct struct_name {
data_type1 member1;
data_type2 member2;
data_type3 member3;
// ...
};
其中:
- struct是用于定义结构体的关键字。
- struct_name是结构体的名称,它是你定义的新数据类型的名称。
- data_type1、data_type2、data_type3等是各个成员的数据类型,它们可以是任何有效的C语言数据类型,包括其他结构体类型。
- member1、member2、member3等是结构体的成员,它们是结构体中的变量,可以有任意多个。
以下是一个具体的例子,定义了一个名为Student的结构体,它有一个字符串类型的name成员,一个整型的age成员,和一个浮点型的score成员:
struct Student {
char name[50];
int age;
float score;
};
结构体定义了一个模板,用于描述该类型的数据应有的形状。这包括结构体中所包含的数据项及其类型。需要注意的是,定义结构体本身不会分配内存,只有在定义了结构体变量之后,系统才会为结构体的各个成员分配内存。例如,以下代码定义了一个Student类型的变量stu:
struct Student stu;
在代码执行到这一行时,系统会为stu分配足够的内存,用来存储name、age和score这三个成员的值。
结构体变量
在C语言中,结构体变量是由结构体定义得到的实例。一旦你定义了一个结构体(定义了一个结构体的模板),你就可以创建该类型的变量,这些变量被称为结构体变量。
创建结构体变量的语法如下:
struct struct_name variable_name;
其中,struct_name是你之前定义的结构体的名称,variable_name是你要创建的结构体变量的名称。
例如,如果我们有一个名为Student的结构体:
struct Student {
char name[50];
int age;
float score;
};
我们可以创建一个Student类型的变量stu:
struct Student stu;
我们也可以一次性创建多个结构体变量:
struct Student stu1, stu2, stu3;
或者创建结构体的数组:
struct Student students[30];
创建了结构体变量之后,我们就可以为它的成员赋值。我们使用点运算符(.)来访问结构体的成员,例如:
strcpy(stu.name, "Alice"); stu.age = 20; stu.score = 90.5;
此外,我们还可以在定义结构体的同时创建结构体变量:
struct Student {
char name[50];
int age;
float score;
} stu;
在这个例子中,我们定义了Student结构体,并且同时创建了一个Student类型的变量stu。
需要注意的是,每个结构体变量都有自己的存储空间,修改一个结构体变量的成员不会影响到其他的结构体变量。
访问结构体成员
在C语言中,我们可以使用点运算符(.)来访问结构体的成员。语法如下:
struct_variable.member
其中,struct_variable是结构体变量的名称,member是你要访问的结构体成员的名称。
例如,假设我们有一个Student结构体,并且我们创建了一个Student类型的变量stu:
struct Student {
char name[50];
int age;
float score;
};
struct Student stu;
我们就可以使用点运算符来访问stu的name、age和score成员:
strcpy(stu.name, "Alice"); stu.age = 20; stu.score = 90.5;
在这个例子中,我们给stu的name赋值为”Alice”,age赋值为20,score赋值为90.5。
如果你有一个指向结构体的指针,你可以使用箭头运算符(->)来访问结构体的成员。语法如下:
struct_pointer->member
例如:
struct Student *p = &stu; p->age = 20;
在这个例子中,p是一个指向Student结构体的指针,我们使用箭头运算符给stu的age成员赋值为20。这等价于(*p).age=20。
结构体指针
结构体指针是一个指向结构体的指针。与其他类型的指针(如int指针、float指针、char指针等)一样,结构体指针存储的是结构体变量的地址。
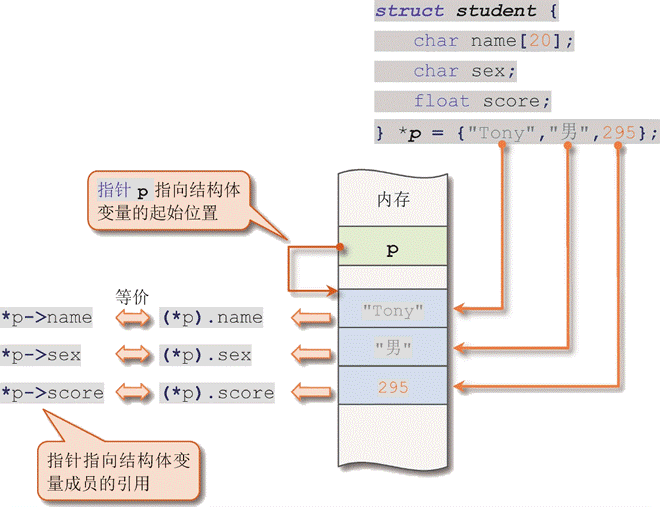
声明结构体指针的语法如下:
struct struct_name *pointer_name;
其中,struct_name是结构体的名称,pointer_name是你要创建的结构体指针的名称。
例如,假设我们有一个名为Student的结构体,并创建了一个Student类型的变量stu:
```html
struct Student {
char name[50];
int age;
float score;
};
struct Student stu;
我们可以创建一个指向stu的指针p:
struct Student *p = &stu;
在这个例子中,p是一个指向Student类型的指针,我们使用&运算符取stu的地址,然后赋值给p。
我们可以使用箭头运算符(->)来通过指针访问结构体的成员:
p->age = 20;
在这个例子中,我们使用箭头运算符来访问stu的age成员,并给它赋值为20。这等价于(*p).age=20。
需要注意的是,当你通过指针修改结构体的成员时,你实际上是在修改这个结构体变量。在上面的例子中,p->age=20;语句实际上修改了stu的age成员。
结构体指针在很多情况下都很有用,尤其是当你需要在函数之间传递大型结构体时,使用结构体指针可以避免复制整个结构,从而提高程序的效率。
结构体数组
在C语言中,结构体数组是由同一种类型的结构体构成的数组。它允许我们存储多个结构体变量,这在处理大量相关数据时非常有用。
定义结构体数组的语法如下:
struct struct_name array_name[array_size];
其中,struct_name是结构体的名称,array_name是你要创建的数组的名称,array_size是数组的大小(即数组中的元素数量)。
例如,假设我们有一个名为Student的结构体:
struct Student {
char name[50];
int age;
float score;
};
我们可以创建一个由Student结构体组成的数组class,假设我们的班级有30个学生:
struct Student class[30];
在这个例子中,class是一个包含30个Student结构体的数组。
我们可以使用数组索引来访问数组中的每一个元素(即每一个结构体变量),并且我们可以使用点运算符来访问结构体的成员。例如,以下代码给第一个学生的名字赋值为”Alice”:
strcpy(class[0].name, "Alice");
在这个例子中,class[0]代表数组中的第一个学生,class[0].name代表第一个学生的名字。
结构体数组在很多情况下都很有用,尤其是当我们需要处理一组相关的复杂数据时,例如一组学生的信息,一组商品的信息等。
嵌套结构体
嵌套结构体是指在一个结构体中包含另一个结构体作为其成员的情况。这在C语言中是完全允许的,它允许我们构造更复杂的数据模型。
以下是定义嵌套结构体的基本语法:
struct struct_name1 {
//...
struct struct_name2 member;
//...
};
其中:
- struct_name1是外部结构体的名称。
- struct_name2是内部结构体的名称。
- member是内部结构体在外部结构体中的成员名称。
例如,我们可以定义一个Date结构体和一个Student结构体,Student结构体中包含一个Date结构体作为birthday成员:
struct Date {
int year;
int month;
int day;
};
struct Student {
char name[50];
struct Date birthday;
float score;
};
在这个例子中,Date结构体包含year、month和day三个成员,Student结构体包含name、birthday和score三个成员,其中birthday成员是Date类型的。
我们可以使用点运算符来访问嵌套结构体的成员,例如给一个学生的生日赋值:
struct Student stu; strcpy(stu.name, "Alice"); stu.birthday.year = 2000; stu.birthday.month = 1; stu.birthday.day = 1; stu.score = 90.5;
在这个例子中,我们首先创建了一个Student类型的变量stu,然后我们给stu的各个成员赋值,包括stu.birthday成员的year、month和day成员。
嵌套结构体在处理复杂的数据模型时非常有用,它允许我们在一个结构体中包含另一个结构体,从而构造出更复杂的数据模型。
typedef和结构体
在C语言中,typedef是一个关键字,它允许我们为现有的类型创建新的名称(别名)。与结构体一起使用时,typedef可以简化结构体变量的定义和声明。
通常,定义和声明结构体变量需要使用struct关键字,如下所示:
struct Student {
char name[50];
int age;
float score;
};
struct Student stu;
但是,如果我们使用typedef为struct Student创建一个新的名称,那么我们就可以在定义和声明结构体变量时省略struct关键字。例如:
typedef struct Student {
char name[50];
int age;
float score;
} Stu;
Stu stu;
在这个例子中,我们使用typedef为struct Student创建了一个新的名称Stu,然后我们就可以使用Stu来定义和声明结构体变量。
这样做的好处是,我们可以简化结构体变量的定义和声明,使代码看起来更简洁。此外,这也使我们的代码更接近于面向对象编程的写法,因为我们可以将结构体看作是一种新的数据类型。
还有另一种常见的用法是在定义结构体的同时创建别名,例如:
typedef struct {
char name[50];
int age;
float score;
} Student;
Student stu;
在这个例子中,我们在定义结构体的同时使用typedef创建了一个新的名称Student。这样,我们就可以直接使用Student来定义和声明结构体变量,而无需再使用struct关键字。
结构体的自引用
在C语言中,结构体可以包含指向其自身类型的指针,这被称为结构体的自引用。这种特性常常被用于创建链表、树等数据结构。
以下是定义包含自引用的结构体的基本语法:
struct struct_name {
//...
struct struct_name *pointer_name;
//...
};
其中:
- struct_name是结构体的名称。
- pointer_name是指向该结构体类型的指针的名称。
结构体与链表
“`链表是一种常见的数据结构,它是由一系列结点(每个结点至少包含一个指向下一个结点的指针)组成的线性集合。在C语言中,我们通常使用包含自引用的结构体来实现链表。
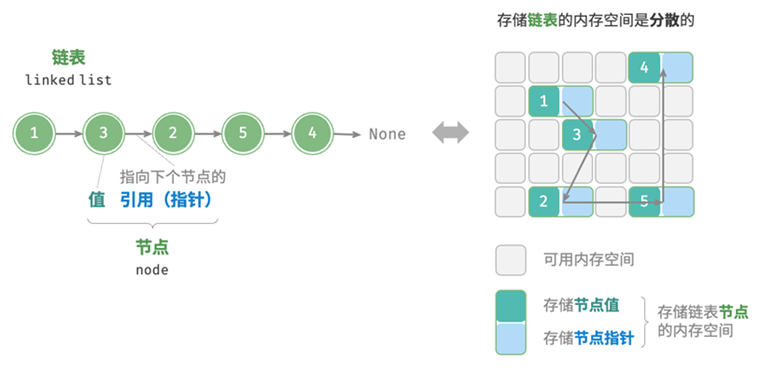
以下是一个简单的链表结点的定义:
struct Node {
int data;
struct Node* next;
};
在这个结构体中,data是用来存储数据的字段,next是一个指向下一个结点的指针。第一个结点通常被称为链表的头结点。
可以这样创建链表:
struct Node node1, node2, node3; node1.data = 1; node2.data = 2; node3.data = 3; node1.next = &node2; node2.next = &node3; node3.next = NULL;
在这个例子中,我们创建了一个包含三个结点的链表。node1的next成员指向node2,node2的next成员指向node3,node3的next成员为NULL,表示这是链表的末尾。
在链表中,我们可以方便地向链表中添加和删除结点。例如,要在node1和node2之间插入一个新的结点node4,我们可以这样做:
struct Node node4; node4.data = 4; node4.next = node1.next; node1.next = &node4;
通过node1.next=&node4;和node4.next=node1.next;两步操作,我们就成功地将node4插入到node1和node2之间。
链表与数组相比,最大的优点是链表在插入和删除数据时更加高效,因为链表在插入和删除数据时不需要移动其他元素。但是,链表的访问速度比数组慢,因为链表不支持随机访问,如果要访问链表中的某个元素,需要从头结点开始,按顺序遍历链表。
结构体与树
树是一种常见的非线性数据结构,它是由结点以及连接结点的边组成。树结构中的结点有一个根结点,每个结点有零个或多个子结点,并且每个结点只有一个父结点。在C语言中,我们通常使用结构体来实现树,其中结构体中的指针字段用于指向子结点。

以下是一个简单的二叉树结点的定义:
struct Node {
int data;
struct Node* left;
struct Node* right;
};
在这个结构体中,data是用来存储数据的字段,left和right是指向左、右子结点的指针。
创建一个二叉树可以这样进行:
struct Node node1, node2, node3; node1.data = 1; node2.data = 2; node3.data = 3; node1.left = &node2; node1.right = &node3; node2.left = NULL; node2.right = NULL; node3.left = NULL; node3.right = NULL;
在这个例子中,我们创建了一个简单的二叉树,node1是根结点,node2和node3是它的左、右子结点。
在树结构中,我们可以方便地进行添加和删除结点的操作。例如,我们想要在node2下添加一个子结点node4,我们可以这样做:
struct Node node4; node4.data = 4; node4.left = NULL; node4.right = NULL; node2.left = &node4;
通过node2.left=&node4;操作,我们就成功地将node4添加为node2的左子结点。
树结构在处理某些问题时具有很大的优势,例如在文件系统、数据库系统和路由算法中都有广泛的应用。但是,与链表一样,树结构不支持快速的随机访问,访问树中的元素需要从根结点开始,依照特定的路径一步步进行。
结构体传参
结构体可以作为函数的参数进行传递。有两种方式可以实现这一操作:传值调用和传引用调用。
传值调用
这种方式是将整个结构体复制一份传递给函数,函数对复制的结构体进行操作,不会影响原结构体的值。例子如下:
struct Student {
char name[50];
int age;
float score;
};
void printStudent(struct Student stu) {
printf("%s, %d, %.2f\n", stu.name, stu.age, stu.score);
}
int main() {
struct Student stu = {"Alice", 20, 90.5};
printStudent(stu);
return 0;
}
以上代码中,printStudent函数接收一个Student类型的参数stu,然后打印学生的信息。在main函数中,我们创建了一个Student类型的变量stu,然后将stu作为参数传递给printStudent函数。此过程中,stu的值被复制,并传递给了printStudent函数。
传引用调用
这种方式是将结构体的地址传递给函数,函数通过指针访问和操作原结构体。这种方式可以修改原结构体的值。例子如下:
struct Student {
char name[50];
int age;
float score;
};
void updateStudent(struct Student* stu, int age, float score) {
stu->age = age;
stu->score = score;
}
int main() {
struct Student stu = {"Alice", 20, 90.5};
updateStudent(&stu, 21, 95.5);
printf("%s, %d, %.2f\n", stu.name, stu.age, stu.score);
return 0;
}
以上代码中,updateStudent函数接收一个指向Student类型的指针stu,然后更新学生的年龄和分数。在main函数中,我们创建了一个Student类型的变量stu,然后将stu的地址传递给updateStudent函数。此过程中,updateStudent函数通过stu指针直接修改了原stu结构体的值。
总的来说,传值调用是安全的,但可能因为复制结构体而导致内存和性能开销,尤其当结构体很大时。传引用调用则可以避免这种开销,但需要注意函数可能会修改原结构体的值。
结构体内存对齐
CPU访问内存时,并不是逐个字节访问,而是以字长(word size)为单位访问。比如32位的CPU,字长为4字节,那么CPU访问内存的单位也是4字节。
这么设计的目的,是减少CPU访问内存的次数,加大CPU访问内存的吞吐量。比如同样读取8个字节的数据,一次读取4个字节那么只需要读取2次。
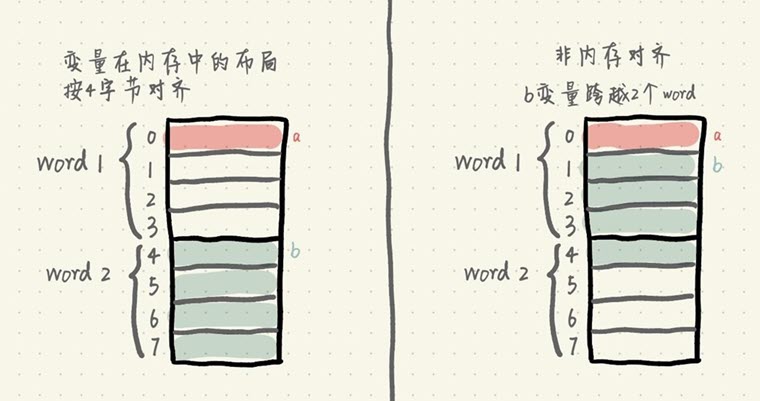 如果变量在内存中的布局按4字节对齐,那么读取a变量只需要读取一次内存,即word1;读取b变量也只需要读取一次内存,即word2。而如果变量不做内存对齐,那么读取a变量也只需要读取一次内存,即word1;但是读取b变量时,由于b变量跨越了2个word,所以需要读取两次内存,分别读取word1和word2的值,然后将word1偏移取后3个字节,word2偏移取前1个字节,最后将它们做或操作,拼接得到b变量的值。
如果变量在内存中的布局按4字节对齐,那么读取a变量只需要读取一次内存,即word1;读取b变量也只需要读取一次内存,即word2。而如果变量不做内存对齐,那么读取a变量也只需要读取一次内存,即word1;但是读取b变量时,由于b变量跨越了2个word,所以需要读取两次内存,分别读取word1和word2的值,然后将word1偏移取后3个字节,word2偏移取前1个字节,最后将它们做或操作,拼接得到b变量的值。
显然,内存对齐在某些情况下可以减少读取内存的次数以及一些运算,性能更高。另外,由于内存对齐保证了读取b变量是单次操作,在多核环境下,原子性更容易保证。但是内存对齐提升性能的同时,也需要付出相应的代价。由于变量与变量之间增加了填充,并没有存储真实有效的数据,所以占用的内存会更大。这也是一个典型的空间换时间的应用场景。
在C语言中,为了提高内存访问效率,编译器会按照某种规则对结构体进行内存对齐。这种规则依赖于具体的编译器和硬件平台,但一般都遵循以下基本原则:
- 结构体的起始地址应该与其最宽基本类型成员的大小对齐。例如,如果结构体中有double类型的成员,那么结构体的起始地址应该是8的倍数(在大多数平台上,double类型的大小是8字节)。
- 结构体中的每个成员相对于结构体起始地址的偏移量(offset)应该是该成员类型大小的整数倍。例如,如果结构体中有int类型的成员,那么这个成员的偏移量应该是4的倍数(在大多数平台上,int类型的大小是4字节)。
- 结构体的总大小应该是其最宽基本类型成员大小的整数倍。如果不是,那么编译器会在结构体的末尾添加填充字节。
例如,我们有如下的结构体:
struct S {
char a;
int b;
char c;
};
在32位系统上,int类型的大小是4字节,char类型的大小是1字节。根据内存对齐的规则,结构体S的内存布局如下:
- a占用1字节。
- 为了让b的偏移量是4的倍数,需要添加3个填充字节。
- b占用4字节。
- c占用1字节。
为了让结构体的总大小是其最宽基本类型成员(这里是int)的整数倍,需要添加3个填充字节。
所以,结构体S的总大小是12字节。
注意,虽然内存对齐可以提高内存访问效率,但同时也可能浪费一些内存空间。如果需要更紧凑的内存布局,可以使用编译器提供的特定的打包指令(例如GCC的__attribute__((packed)))来关闭内存对齐,但这可能会降低内存访问效率。


