Ray简介 Ray是一个开源的分布式计算框架,专为机器学习和人工智能应用设计。它提供了一种灵活、高效的方式来构建和运行分布式应用程序,特别是在需要大规模并行计算的场景中。Ray的核心是一个通用的分布式执行引擎…

OpenMetadata简介 OpenMetadata是一个开源的元数据管理和数据治理平台,旨在帮助企业更好地管理、发现和治理其数据资产。它提供了一个统一的框架,用于收集、存储和查询各种数据源的元数据,支持数据的发现、血缘分…
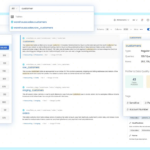
Marquez简介 Marquez是一个开源的元数据服务平台,专注于数据管道的可观察性和数据治理。它旨在帮助企业跟踪和管理数据流动,提供关于数据集和数据处理作业的详细元数据。通过提供数据血缘、数据质量和数据依赖关系…

LakeFS简介 LakeFS是一个开源的数据湖管理平台,旨在为数据湖提供类似于Git的版本控制和管理功能。它允许用户对数据湖中的数据进行版本化、分支和合并操作,从而提升数据管理的灵活性和可控性。LakeFS支持在大规模…
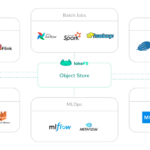
DataHub简介 DataHub是一个开源的元数据平台,最初由LinkedIn开发,旨在帮助企业实现数据的发现、管理和治理。DataHub提供了一套工具和服务,用于收集、存储和查询数据资产的元数据,帮助用户理解和利用企业的数据…
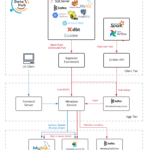
Databend简介 Databend是一个开源的云原生数据仓库,专为现代数据分析需求设计,旨在提供高性能、高弹性和易于使用的数据分析解决方案。Databend的架构充分利用了云计算的优势,支持大规模数据处理和实时分析,适合…

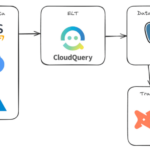
CloudQuery简介 CloudQuery是一个开源的数据集成工具,专为云环境中的数据提取、转换和加载(ETL)任务而设计。它允许用户从各种云服务和基础设施中提取数据,并将这些数据转换为常见的分析格式,通常存储在数据仓…
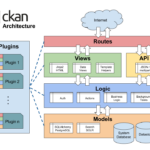
CKAN简介 CKAN(Comprehensive Knowledge Archive Network)是一个开源的数据管理系统,专门用于发布、共享和发现数据集。它被广泛用于政府、组织和公司,帮助他们将数据发布到数据门户网站,以便公众或内部用户可…
Apache TinkerPop简介 Apache TinkerPop是一个开源的图计算框架,旨在提供一套通用的工具和接口来处理图数据。它支持各种图数据库和图处理系统,通过统一的接口和查询语言简化了图数据的管理和分析。 产生背…

Neo4j简介 Neo4j是一种广泛使用的图数据库管理系统,以其高性能和可扩展性著称,特别适合处理复杂的关系和连接数据。作为图数据库领域的领导者,Neo4j被广泛应用于各种行业和应用场景。 核心概念 图数据模型:N…






