文章内容如有错误或排版问题,请提交反馈,非常感谢!
CloudQuery简介
CloudQuery是一个开源的数据集成工具,专为云环境中的数据提取、转换和加载(ETL)任务而设计。它允许用户从各种云服务和基础设施中提取数据,并将这些数据转换为常见的分析格式,通常存储在数据仓库或数据库中,以便进行进一步的分析和报告。
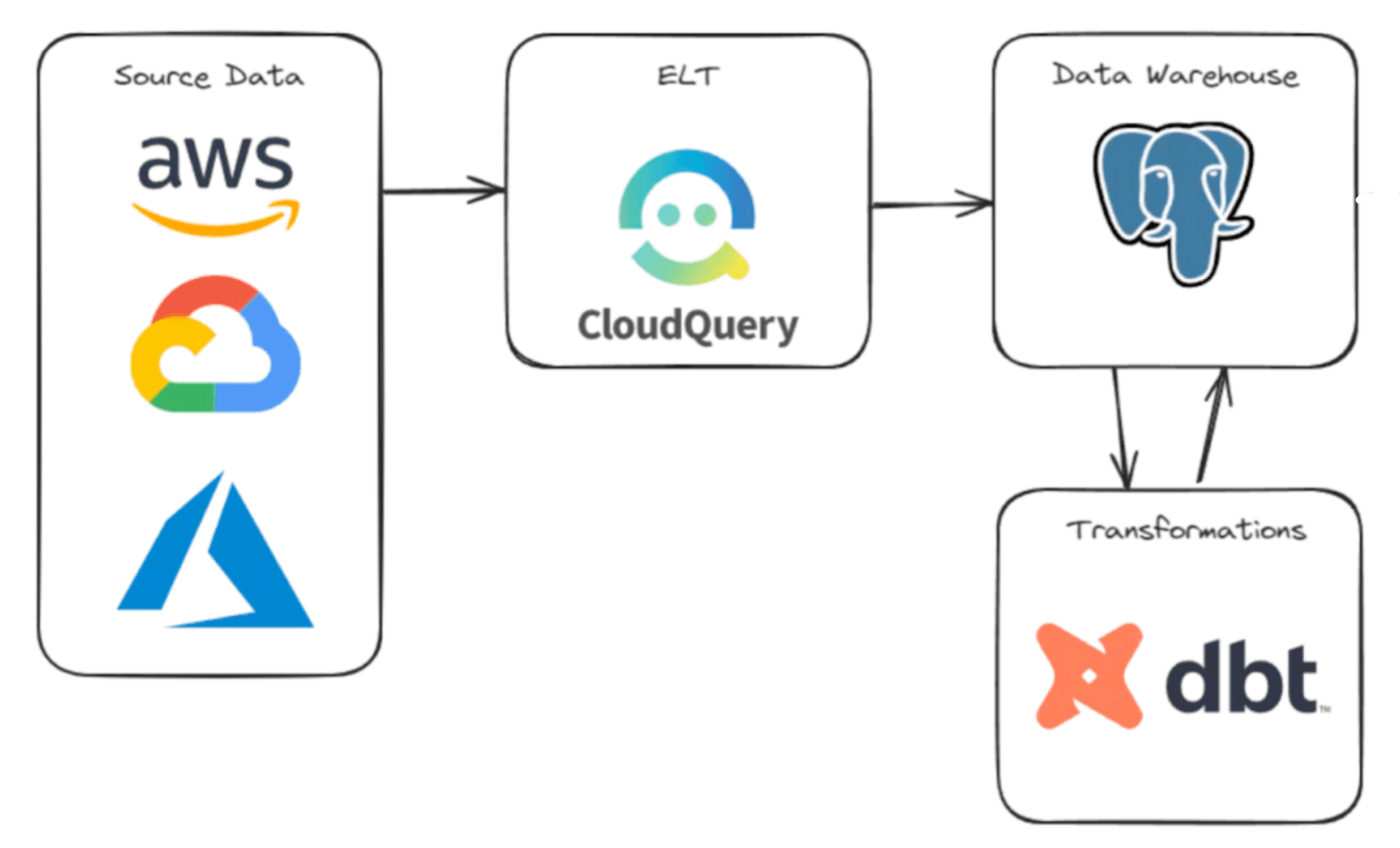
核心特性
- 多云支持:
- CloudQuery支持从多个云服务提供商(如AWS、Google Cloud、Azure)中提取数据。
- 提供对各种云服务的原生集成,包括云存储、计算服务、监控工具等。
- 灵活的数据转换:
- 提供灵活的数据转换功能,允许用户根据需要自定义数据格式和结构。
- 支持丰富的数据操作和转换规则,适应不同的分析需求。
- 开源和可扩展性:
- 作为开源工具,CloudQuery允许用户根据特定需求进行定制和扩展。
- 用户可以开发自定义插件和连接器,以支持新的数据源和目标。
- 高效的数据加载:
- 优化的数据加载机制,支持将数据高效地加载到目标数据仓库或数据库中。
- 提供增量加载和全量加载选项,适应不同的数据同步需求。
- 安全性和合规性:
- 提供数据加密和访问控制,确保数据在传输和存储过程中的安全性。
- 支持合规性要求,帮助企业满足数据隐私和安全标准。
应用场景
- 云资源监控和分析:
- 从云服务中提取监控和性能数据,用于资源优化和成本管理。
- 支持跨云的资源使用分析,帮助企业优化云资源配置。
- 安全和合规报告:
- 提取安全事件和日志数据,用于合规性报告和安全审计。
- 支持自动化的合规检查和报告生成,确保企业满足法规要求。
- 数据迁移和整合:
- 支持云间和云到本地的数据迁移,简化数据整合过程。
- 提供灵活的数据转换功能,确保数据在不同环境中的一致性。
- 业务智能和数据分析:
- 将云服务数据加载到数据仓库中,支持复杂的分析和报告。
- 与BI工具集成,实现数据的可视化和业务洞察。
CloudQuery的架构
CloudQuery是一个开源的工具,旨在帮助用户从云基础设施中提取、转换和加载(ETL)数据,以便进行数据分析和合规性检查。它的架构设计旨在简化从多种云服务中收集和处理数据的过程,支持灵活的数据查询和转换。
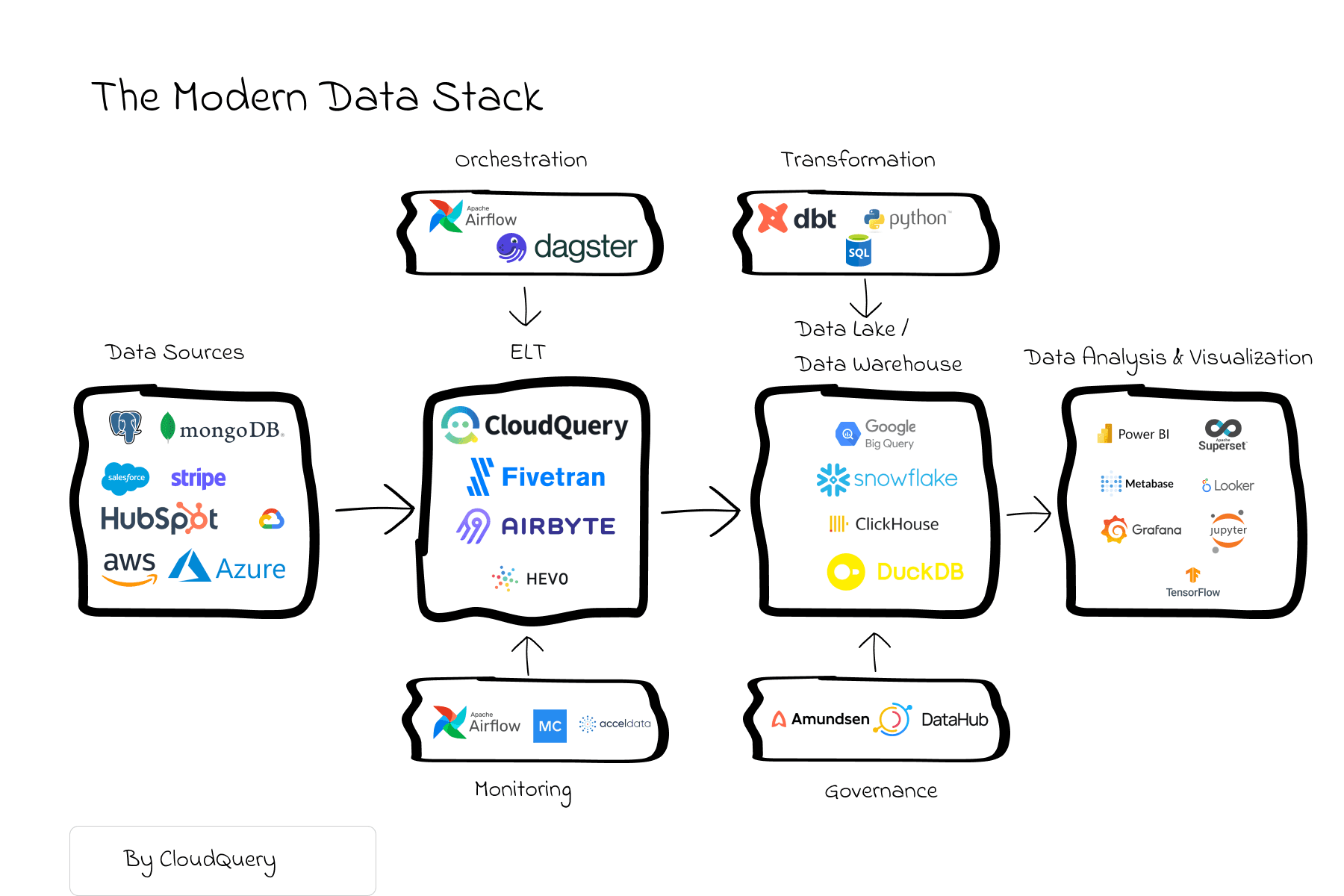
以下是CloudQuery的主要架构组件和设计原则:
- 数据源连接器
- 功能:CloudQuery支持多种数据源连接器,用于从不同的云服务(如AWS、Azure、Google Cloud等)中提取数据。这些连接器封装了与特定云服务API的交互逻辑。
- 可扩展性:通过插件机制,CloudQuery可以轻松扩展以支持新的云服务和数据源。
- 数据提取
- 批量提取:CloudQuery通过批量请求从数据源中提取数据,优化了网络和API调用的效率。
- 增量提取:对于支持增量数据更新的服务,CloudQuery可以配置为仅提取自上次同步以来的更改,以减少数据传输量和处理时间。
- 数据转换
- 模式转换:CloudQuery支持将提取的数据转换为符合目标数据仓库或数据库模式的结构。这包括数据类型转换、字段映射和数据清洗等操作。
- 灵活的转换规则:用户可以通过配置文件定义自定义的转换规则,以满足特定的数据处理需求。
- 数据加载
- 目标存储支持:CloudQuery可以将转换后的数据加载到多种目标存储系统中,如关系型数据库(PostgreSQL、MySQL)、数据仓库(Snowflake、BigQuery)等。
- 批量加载:为了提高性能,CloudQuery通常会使用批量加载技术,将大量数据一次性写入目标存储。
- 调度与自动化
- 任务调度:CloudQuery支持任务调度,用户可以配置定时任务,以自动化数据提取、转换和加载过程。
- 自动重试:在网络或服务中断的情况下,CloudQuery提供自动重试机制,确保任务的可靠性和数据的完整性。
- 监控与日志
- 日志记录:CloudQuery记录详细的操作日志,包括数据提取、转换和加载的状态、错误信息等,方便用户进行调试和问题排查。
- 性能监控:通过集成监控工具,用户可以实时监控CloudQuery的性能指标,如数据处理速度、资源使用情况等。
- 安全与权限管理
- 认证与授权:CloudQuery支持与云服务的安全认证机制集成,确保数据访问的安全性。
- 敏感数据处理:提供对敏感数据的加密和脱敏选项,以保护数据隐私和合规性。
CloudQuery的架构设计强调灵活性和可扩展性,以适应不同的云环境和数据处理需求。通过模块化的设计和插件机制,CloudQuery能够快速适应新的数据源和目标存储系统,帮助用户简化从云基础设施中提取和分析数据的流程。其自动化和监控功能进一步增强了数据处理的可靠性和效率,使其成为云数据管理和合规性检查的有力工具。
参考链接:


