LakeFS简介
LakeFS是一个开源的数据湖管理平台,旨在为数据湖提供类似于Git的版本控制和管理功能。它允许用户对数据湖中的数据进行版本化、分支和合并操作,从而提升数据管理的灵活性和可控性。LakeFS支持在大规模数据集上进行原子操作,帮助企业更好地管理和治理数据湖。
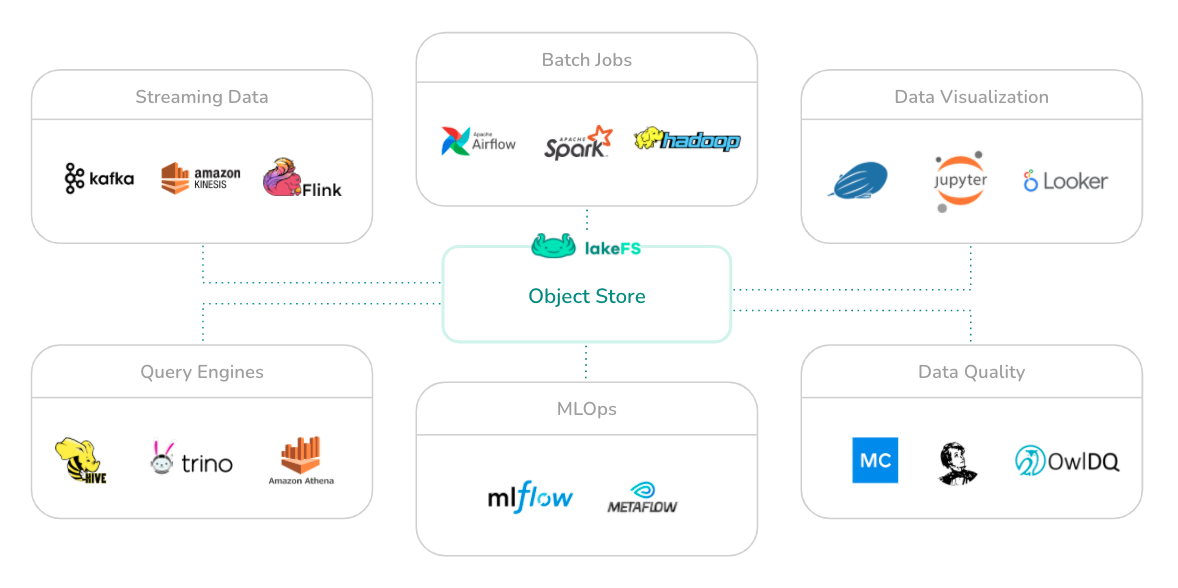
产生背景
LakeFS是一个开源的数据版本控制系统,专门设计用于数据湖(Data Lake)的管理和治理。它的产生背景可以从以下几个方面来理解:
数据湖管理的挑战
随着大数据技术的发展,越来越多的企业开始构建数据湖,以存储和管理大规模的原始数据。然而,数据湖管理面临着一系列挑战:
- 数据版本控制:缺乏有效的数据版本控制机制,导致数据的变更难以追踪和回滚。
- 数据一致性:在多用户和多任务环境下,数据的一致性和完整性难以保证。
- 数据治理:缺乏统一的数据治理工具,导致数据质量低下和合规性问题。
- 数据共享:数据的共享和协作困难,尤其是在跨团队和跨项目的情况下。
版本控制的需求
在软件开发领域,版本控制系统(如Git)已经被广泛使用,有效解决了代码的版本控制、协作和回滚问题。然而,数据湖缺乏类似的工具,无法有效地管理数据的版本和变更历史。
- 数据版本控制:类似于Git,数据湖也需要一个版本控制系统来记录数据的变更历史,支持数据的回滚和恢复。
- 数据协作:多用户和多团队需要在一个数据湖中协同工作,版本控制系统可以帮助管理不同版本的数据,避免冲突和数据丢失。
数据治理的重要性
数据治理是数据湖成功的关键因素之一。有效的数据治理可以确保数据的质量、安全性和合规性。然而,传统的数据治理工具往往难以应对大规模数据湖的复杂性。
- 数据质量:数据版本控制系统可以帮助跟踪数据的来源和变更历史,提高数据质量。
- 数据安全:通过版本控制,可以更容易地审计数据的访问和变更,增强数据的安全性。
- 数据合规:数据版本控制系统可以提供详细的数据变更日志,帮助企业满足合规性要求。
现代数据处理的需求
现代数据处理需要高效、灵活和可扩展的工具。数据湖作为存储和处理大规模数据的主要方式,需要一个能够支持这些需求的管理系统。
- 高效性:数据版本控制系统需要支持高效的数据读写和查询,以满足大规模数据处理的需求。
- 灵活性:数据版本控制系统需要支持多种数据格式和存储后端,以适应不同的数据处理场景。
- 可扩展性:数据版本控制系统需要支持水平扩展,以处理不断增长的数据量。
LakeFS的设计理念
LakeFS正是在这样的背景下产生的,它借鉴了Git的设计理念,专门为数据湖设计了一个版本控制系统。LakeFS的主要目标是:
- 数据版本控制:记录数据的变更历史,支持数据的回滚和恢复。
- 数据协作:支持多用户和多团队在同一个数据湖中协同工作。
- 数据治理:提供数据质量、安全性和合规性的管理工具。
- 高效性和灵活性:支持高效的数据读写和查询,适应多种数据格式和存储后端。
核心特性
LakeFS是一个开源的数据版本控制系统,专门为数据湖设计,旨在提供类似于Git的版本控制功能。它帮助用户更好地管理、治理和协作处理数据湖中的数据。

以下是LakeFS的核心特性:
- 数据版本控制
- 分支和合并:类似于Git,LakeFS支持为数据创建分支,这使得用户可以在不影响主数据集的情况下进行数据实验。完成后,可以将更改合并回主分支。
- 快照和回滚:支持对数据湖进行快照,记录数据的特定状态,用户可以随时回滚到之前的版本。
- 历史记录:详细记录数据的变更历史,使得用户可以追踪每一次数据修改,了解数据的演变过程。
- 数据一致性和治理
- 事务支持:LakeFS提供原子性的数据操作,确保在多用户和多任务环境下的数据一致性。
- 数据审计:提供详细的数据变更日志,帮助用户进行数据审计和合规性检查。
- 访问控制:支持基于角色的访问控制,确保只有授权用户可以访问和修改特定的数据。
- 数据协作
- 多用户协作:允许多个用户和团队在同一数据湖中协同工作,通过分支和合并功能有效管理数据冲突。
- 隔离环境:通过分支功能,用户可以在隔离的环境中进行数据实验和开发,避免对生产数据的影响。
- 高效性和可扩展性
- 无缝集成:LakeFS可以无缝集成到现有的数据处理工作流中,支持多种数据格式和存储后端(如Amazon S3、Azure Blob Storage、Google Cloud Storage)。
- 可扩展架构:设计为支持水平扩展,能够处理不断增长的数据量和并发用户请求。
- 低延迟:优化的数据访问路径,确保在大规模数据集上的高效读写操作。
- 数据保护和安全
- 数据完整性:通过版本控制和快照功能,保护数据不被意外修改或删除。
- 灾难恢复:支持数据的快照和回滚功能,使得在数据损坏或丢失时可以快速恢复。
- 集成与兼容性
- 与现有工具兼容:LakeFS可以与现有的大数据工具(如Apache Spark、Presto、Hive)集成,提供一致的版本控制体验。
- 开放API:提供开放的API,方便开发者将LakeFS集成到自定义应用和工具中。
LakeFS通过其核心特性,为数据湖提供了类似于Git的版本控制功能,解决了数据版本管理、数据一致性和协作等关键问题。它使得用户能够在数据湖中进行高效的数据治理和协作,同时确保数据的安全性和完整性。无论是数据科学家、数据工程师还是数据分析师,LakeFS都能够帮助他们更好地管理和利用数据湖中的数据。
应用场景
LakeFS是一个专为数据湖设计的版本控制系统,类似于Git,但专注于数据管理。它的设计目标是帮助企业和组织更好地管理、治理和协作处理大规模数据集。以下是LakeFS的一些典型应用场景:
- 数据实验和开发
- 数据科学和机器学习:数据科学家可以使用LakeFS创建数据分支,在不影响生产数据的情况下进行实验和模型训练。这使得团队能够并行开发和测试不同的模型版本。
- 特征工程:在特征工程过程中,团队可以使用分支来开发和测试新的特征转换流程,然后在验证后合并到主分支。
- 数据版本管理
- 数据变更跟踪LakeFS允许用户记录和跟踪数据的每一次变更,提供数据版本历史,便于审计和回溯。
- 回滚能力:在数据处理或分析出错时,用户可以快速回滚到之前的稳定版本,减少数据损坏的风险。
- 数据协作和团队开发
- 多团队协作:不同团队可以在同一数据湖上创建各自的分支,进行独立开发,避免冲突。完成后,可以将更改合并到主分支。
- 数据隔离:通过分支机制,用户可以在隔离环境中进行开发和测试,确保生产数据的安全性。
- 数据治理和合规
- 数据审计:LakeFS提供详细的变更日志,帮助企业满足合规性要求,便于进行数据审计。
- 访问控制:支持基于角色的访问控制,确保数据只被授权用户访问和修改,增强数据安全。
- 数据湖的管理和优化
- 数据管理:通过版本控制,用户可以更好地管理数据湖中的数据资产,确保数据的一致性和完整性。
- 存储优化:通过快照和版本管理,用户可以更有效地管理存储空间,减少冗余数据。
- 灾难恢复和数据保护
- 数据保护:LakeFS的快照功能允许用户在关键操作前创建数据快照,确保在数据丢失或损坏时可以快速恢复。
- 灾难恢复:在发生数据灾难时,LakeFS的版本控制功能使得数据恢复过程更加快速和可靠。
- ETL和数据集成
- ETL管道开发:在开发和测试ETL(提取、转换、加载)流程时,LakeFS提供了一个安全的环境,便于测试不同的数据转换和加载策略。
- 数据集成测试:用户可以在分支中进行数据集成测试,确保在合并到生产环境前,所有数据处理流程都已验证。
LakeFS的架构
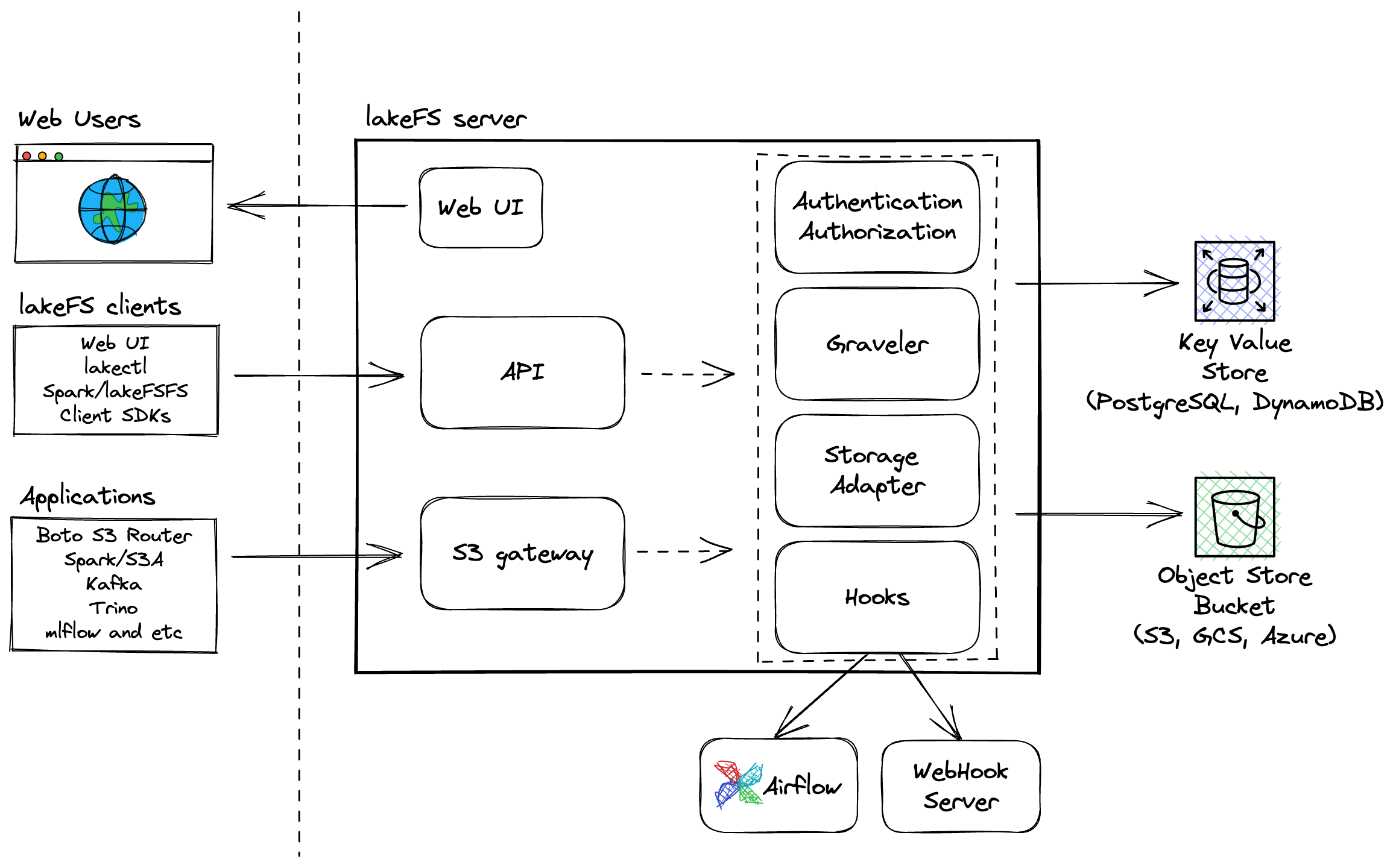
- Object Store:
- 使用现有的对象存储系统(如AWS S3)作为底层存储,确保数据的高可用性和扩展性。
- LakeFS在对象存储之上构建版本控制和管理功能。
- LakeFS Server:
- 作为核心服务,负责处理版本控制、分支、合并和事务性操作。
- 提供RESTful API,支持与客户端和其他系统的交互。
- CLI和SDK:
- 提供命令行工具和SDK,帮助用户管理数据湖和自动化操作。
- 支持常见的操作,如创建分支、提交更改、合并分支等。
- Web UI:
- 提供用户友好的Web界面,支持数据湖的可视化管理和操作。
- 允许用户浏览数据版本、分支和操作历史。
参考链接:


