Apache TinkerPop简介
Apache TinkerPop是一个开源的图计算框架,旨在提供一套通用的工具和接口来处理图数据。它支持各种图数据库和图处理系统,通过统一的接口和查询语言简化了图数据的管理和分析。

产生背景
Apache TinkerPop的产生背景与图计算和图数据库领域的发展密切相关。随着大数据时代的到来,传统的关系型数据库在处理复杂关系和网络结构数据时显得力不从心。图数据库和图计算框架应运而生,专门用于处理这种复杂的关系数据。
- 图数据的重要性
- 复杂关系建模:许多现实世界的问题,如社交网络分析、推荐系统、知识图谱等,都涉及到复杂的关系建模。图数据模型能够自然地表示实体及其关系,适合这类问题的处理。
- 灵活的数据结构:图结构允许动态和灵活的数据表示,相较于传统的行列结构,图可以更直观地表达网络和关系。
- 图数据库的兴起
- 需求增长:随着互联网的普及和社交媒体的兴起,企业和组织对图数据库的需求不断增长,以便更好地分析和利用数据中的关系。
- 技术演进:早期的图数据库和图计算系统各自为政,缺乏统一的标准和接口,这限制了图技术的广泛应用。
- 标准化的需求
- 接口统一:不同的图数据库和计算系统之间缺乏统一的接口和语言,使得用户在切换系统时面临巨大的学习成本和迁移挑战。
- 跨平台支持:需要一个通用的框架,能够支持多种图数据库和计算引擎,提供跨平台的兼容性。
- Apache TinkerPop的诞生
- 统一的图计算框架:TinkerPop作为一个开源项目,最初由Marko A. Rodriguez发起,旨在提供一个通用的图计算框架,以解决图数据库和计算系统的多样性问题。
- Gremlin查询语言:引入Gremlin作为统一的图遍历语言,使得用户能够在不同的图数据库上使用相同的查询语言进行操作。
- Apache基金会支持:成为Apache基金会的顶级项目后,TinkerPop获得了更广泛的社区支持和资源,促进了其快速发展和广泛应用。
- 目标与愿景
- 增强图计算能力:通过提供强大的图遍历和计算能力,帮助用户更高效地进行图数据分析。
- 促进图技术普及:通过标准化和简化图计算接口,降低图技术的使用门槛,促进其在各个领域的普及和应用。
Apache TinkerPop的产生是应对图数据处理需求增长和技术标准化的结果。它通过提供统一的接口和强大的图计算能力,解决了图数据库和计算系统的多样性问题,极大地促进了图技术在各个领域的应用和发展。作为一个开放的框架,TinkerPop为图计算和分析提供了一个强大而灵活的平台。
功能特性
Apache TinkerPop是一个强大的图计算框架,提供了多种功能特性来支持复杂的图数据管理和分析。以下是其主要功能特性:
- Gremlin图遍历语言
- 多语言支持:Gremlin是一种图遍历语言,支持多种编程语言接口,包括Java、Groovy、Python、JavaScript等。这使得开发者可以在熟悉的语言环境中使用图遍历功能。
- 多范式编程:支持命令式、声明式和函数式编程风格,提供灵活的遍历和查询能力。
- 复杂查询支持:能够表达复杂的图查询和数据操作,包括路径查询、模式匹配和聚合操作。
- 图计算模型
- OLTP(在线事务处理):支持实时图遍历和查询,适合处理小规模、实时的图数据操作。
- OLAP(在线分析处理):支持大规模图数据的批量处理和分析,适合复杂的图计算任务,如社交网络分析、路径计算等。
- 图数据结构
- 顶点和边:基本的数据结构,支持附加属性(键值对),用于表示实体和关系。
- 图的可扩展性:支持有向图和无向图,以及多重图和属性图等复杂图结构。
- 兼容性与集成
- 图数据库支持:TinkerPop支持多种图数据库,如JanusGraph、Neo4j、Amazon Neptune等,通过标准接口与这些数据库集成。
- 数据格式支持:支持多种数据格式的输入输出,包括GraphSON、Gryo、GraphML等,方便与其他系统进行数据交换。
- 工具与组件
- Gremlin Server:用于执行Gremlin查询的服务器,支持通过HTTP和WebSocket接收查询请求。
- Gremlin Console:一个交互式命令行工具,允许用户直接在控制台中运行Gremlin查询,适合开发和测试。
- Gremlin Driver:客户端驱动程序,用于在不同编程语言中与Gremlin Server通信。
- 扩展与插件
- 自定义扩展:允许开发者编写自定义的遍历步骤和策略,扩展TinkerPop的功能。
- 插件生态系统:支持第三方插件和扩展,丰富了TinkerPop的功能和应用场景。
- 性能与优化
- 遍历优化:提供遍历策略和优化器,自动优化查询执行计划,提高遍历效率。
- 并行计算:支持并行遍历和计算,利用多核和分布式计算资源提升性能。
- 社区与支持
- 开源社区:作为Apache基金会的顶级项目,TinkerPop拥有活跃的开源社区,提供持续的更新和支持。
- 文档与资源:提供详尽的文档、教程和示例,帮助用户快速上手和解决问题。
Apache TinkerPop提供了全面的功能特性,支持从实时图遍历到大规模图计算的各种需求。其统一的Gremlin查询语言、多语言支持和广泛的数据库兼容性,使得TinkerPop成为处理图数据的强大工具。通过丰富的扩展能力和优化特性,TinkerPop能够适应不同的应用场景和性能要求,是图数据管理和分析的理想选择。
优势与应用场景
Apache TinkerPop是一个强大的图计算框架,具有许多优势,使其在各种应用场景中成为理想的选择。以下是TinkerPop的主要优势和常见的应用场景:
优势
- 统一的查询语言 Gremlin:作为一门强大的图遍历语言,Gremlin 提供了统一的接口,支持多种编程语言。这使得开发者能够在不同的环境中使用一致的查询语言进行图数据操作。
- 多语言支持:TinkerPop 支持多种编程语言(如 Java、Groovy、Python、JavaScript 等),使得开发者可以在熟悉的语言环境中进行开发,提高了开发效率和灵活性。
- 广泛的兼容性:支持多种图数据库和图计算引擎,如 JanusGraph、Neo4j、Amazon Neptune 等,通过标准接口实现无缝集成。
- 灵活的图计算模型:支持 OLTP 和 OLAP 模式,能够处理实时的图查询和大规模的图分析任务,适用于不同的计算需求。
- 丰富的生态系统:提供多种工具和组件,如 Gremlin Server、Gremlin Console 和 Gremlin Driver,方便用户进行开发、测试和部署。
- 可扩展性:允许自定义遍历步骤和策略,支持第三方插件和扩展,用户可以根据具体需求扩展 TinkerPop 的功能。
- 性能优化:提供遍历优化策略和并行计算支持,能够有效利用计算资源,提高图遍历和计算的性能。
应用场景
- 社交网络分析:分析社交网络中的关系和影响力,例如寻找社区结构、计算节点的中心性、发现关键人物等。
- 推荐系统:利用图算法实现个性化推荐,例如基于用户行为和兴趣图进行物品推荐,提高用户体验和满意度。
- 知识图谱:管理和查询复杂的知识图谱数据,支持语义搜索和推理,广泛应用于智能问答和信息检索。
- 网络安全:通过图分析检测网络中的异常活动和威胁模式,例如识别潜在的攻击路径、监控网络流量等。
- 供应链管理:优化供应链网络,通过图分析识别关键节点和路径,提高物流效率和风险管理能力。
- 生物信息学:分析生物网络中的关系和模式,例如基因网络分析、蛋白质相互作用网络研究等。
- 金融欺诈检测:通过图分析识别和检测金融交易中的欺诈行为,增强金融系统的安全性。
Apache TinkerPop 以其强大的功能、广泛的兼容性和灵活的计算模型,成为处理复杂图数据的理想选择。其在社交网络、推荐系统、知识图谱、网络安全等多个领域的成功应用,证明了其在图数据管理和分析中的优势。通过提供统一的查询语言和丰富的工具支持,TinkerPop 帮助用户更高效地进行图数据处理和应用开发。
图查询语言 Gremlin
Gremlin 是一个图遍历语言,它是 Apache TinkerPop 图计算框架的一部分。Gremlin 被设计用于在图数据库和图处理系统中执行复杂的遍历操作。

以下是对 Gremlin 的详细介绍:
核心特性
- 图遍历语言:Gremlin 是一种 DSL(领域特定语言),专门用于在图数据结构上进行遍历。它支持丰富的图遍历操作,包括深度优先、广度优先、循环检测、路径查找等。
- 多平台支持:Gremlin 可以在各种图数据库和处理系统上运行,包括 Apache TinkerGraph、JanusGraph、Amazon Neptune、Azure Cosmos DB、Neo4j 等。
- 可组合性:Gremlin 的遍历步骤是可组合的,开发者可以通过组合基本步骤来构建复杂的查询。
- 多种编程语言支持:Gremlin 有多种语言的实现,包括 Java、Groovy、Python、JavaScript 等,使得开发者可以在自己熟悉的语言环境中使用 Gremlin。
- 图分析功能:Gremlin 支持高级图分析功能,如模式匹配、聚合、排序、过滤、路径计算等,适用于复杂的图数据分析任务。
优势与限制
优势
- 强大的表达能力:Gremlin 支持复杂的图遍历和分析操作,适用于多种应用场景。
- 跨平台兼容性:支持多种图数据库和处理系统,提供灵活的部署选择。
- 可扩展性:能够处理大规模图数据,适用于大数据环境。
限制
- 学习曲线:Gremlin 的语法和思维方式可能对习惯于关系型数据库的开发者有一定的学习成本。
- 性能依赖:性能表现很大程度上依赖于底层图数据库的实现和优化。
工作原理
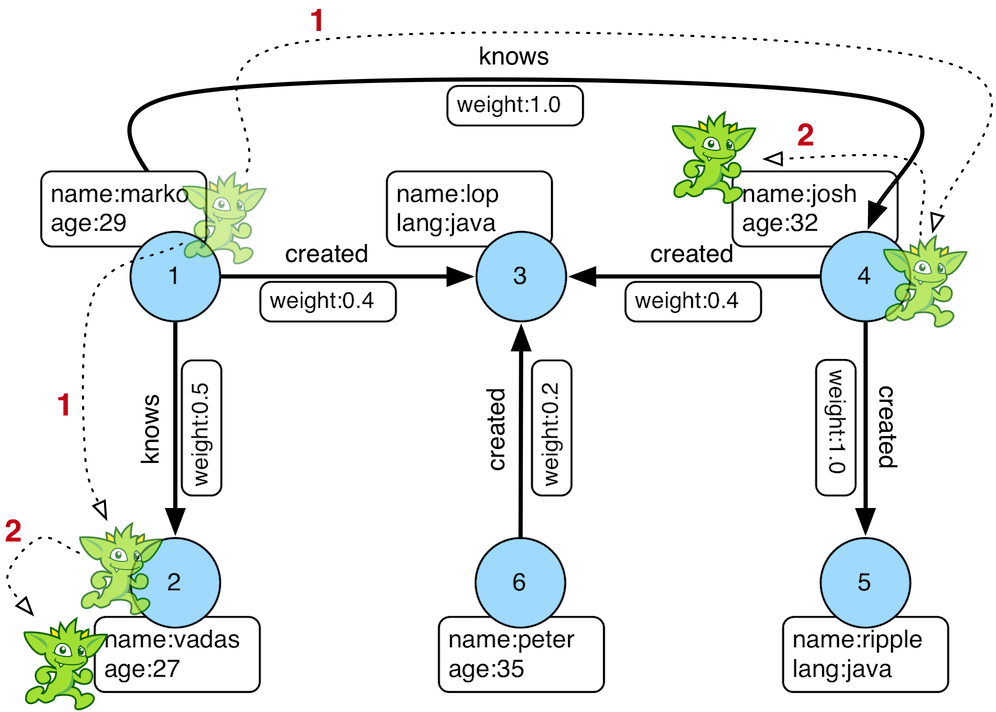
- 图模型:Gremlin 操作的是图数据结构,包括顶点(vertices)和边(edges)。顶点和边可以有属性(properties),用来存储与节点或关系相关的数据。
- 遍历步骤:Gremlin 使用一系列的遍历步骤(steps)来操作图数据。每个步骤执行一个特定的操作,如过滤、映射、聚合等。
- 遍历链:步骤可以链式组合形成遍历链。遍历链描述了从起始顶点开始的图遍历路径,最终返回结果集。
- 执行环境:Gremlin 遍历在 Gremlin 机器上执行,Gremlin 机器负责解析、优化和执行遍历。
语法示例
以下是一个简单的 Gremlin 查询示例,用于查找某个顶点的所有邻居:
g.V().hasLabel('person').has('name','Alice').out('knows').values('name')
这个查询的意思是:从图中找到标签为 person 且名字为 Alice 的顶点,然后找到 Alice 通过 knows 边连接的所有顶点,并返回这些顶点的 name 属性。
Gremlin 作为一种强大的图遍历语言,为开发者提供了灵活和高效的图数据处理能力。它在社交网络分析、推荐系统、欺诈检测等领域有广泛的应用。通过支持多种图数据库和处理平台,Gremlin 为开发者在图数据的存储和分析提供了多样化的选择。随着图数据应用的普及,Gremlin 在图计算中的作用将愈发重要。
参考链接:


