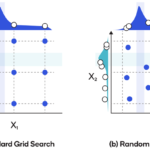
什么是超参数? 学习器模型中一般有两类参数,一类是可以从数据中学习估计得到,我们称为参数(Parameter)。还有一类参数时无法从数据中估计,只能靠人的经验进行设计指定,我们称为超参数(Hyperparameter)。超…
由于某些不可抗因素,Python官方的包在国内有时无法访问或出现网络不稳定现象。conda源也会出现网络链接失败的问题。为了解决这个问题,这里梳理了一些配置方法。 Pip与Conda的比较 依赖项检查 pip:不一定会展…

使用 Python 编程时,经常会遇到读写文件的操作。对于读写文件的各种模式(如阅读、写入、追加等)有时真的会迷惑人,以及搞不清 open、read、readline、readlines、write、writelines 等方法的使用也会把你绕的云…

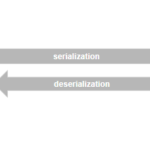
Pickle Python中有个序列化过程称为pickle,它能够实现任意对象与文本之间的相互转化,也可以实现任意对象与二进制之间的相互转化。也就是说,pickle可以实现Python对象的存储及恢复。 序列化(picking):把变量从…
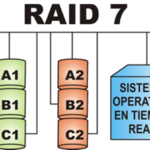
单机时代,采用单块磁盘进行数据存储和读写的方式,由于寻址和读写的时间消耗,导致I/O性能非常低,且存储容量还会受到限制。另外,单块磁盘极其容易出现物理故障,经常导致数据的丢失。因此大家就在想,有没有一种…
AIML简介 AIML全名为 Artificial Intelligence Markup Language(人工智能标记语言),是一种创建自然语言软件代理的 XML 语言,是由 Richard S. Wallace 博士和 Alicebot 开源软件组织于 1995-2000 年间发明创造的…

在使用Python处理数据的时候,经常会需要处理Excel中的数据。现在基本上都使用Pandas读取Excel中的数据,但是除了Pandas以外,还有一些Python包可以满足对Excel数据的读取。 在开始之前,先学习下Excel中涉及到…

先前在使用Python进行抓取的时候,遇到读取数据的错误。经过分析发现原来返回的HTML中包含控制字符(原来防爬虫还可以这么干,控制字符在抓取程序中容易引起报错,但是在浏览器中呈现给用户的时候确没有什么影响)…

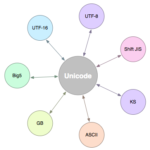
程序开发中最容易遇到,最烦,最恶心的问题是什么?字符编码问题!本文期望通过最详尽的梳理来解决这个问题。 什么是编码? 计算机中储存的信息都是用二进制数表示的;而我们在屏幕上看到的英文、汉字等字符是二…
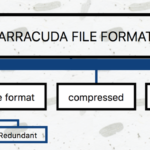
在早期的 InnoDB 版本中,由于文件格式只有一种,因此不需要为此文件格式命名。随着 InnoDB 引擎的发展,开发出了不兼容早期版本的新文件格式,用于支持新的功能。为了在升级和降级情况下帮助管理系统的兼容性,以…