Adaptive Alerting(AA)是Expedia开源的异常检测项目,整个项目也是完整一套监控体系,包括事件处理恢复操作都在内。系统设计主要在如何方便集成不同的异常检测算法和评估方法,然后根据指标的情况来路由和触发重训练等等。目前已经集成的算法比较基础,以下内容翻译自其Wiki文档。
Adaptive Alerting的整体定位
Adaptive Alerting de的设计目标:
- 首要目标:降低异常发现的平均时间(MTTD),即从某个生产事件开始到某人知道它之间的平均时间,其中”某人”可以是某人,也可以是自动响应系统。对于”知道”一个事件意味着什么,有不同的思考方式,但对我们来说,即使在某种意义上监控系统”知道”了这个事件,但如果一个警报在大量警报中丢失,它也不算数。
- 为了支持这一点,我们需要监测尽可能多的健康信号。否则我们会错过问题,MTTD也会受到影响。所讨论的信号或度量可以表示业务、应用程序或系统级别的关注点。我们的工作假设是,在一个大型企业中,存在成千上万甚至数百万这样的问题,因此Adaptive Alerting de需要相应地扩大规模。
- 为了实现可伸缩性,我们必须积极限制误报(即假警报)的数量。假警报使人们对真正的影响因素失去了关注,削弱了监测系统的有效性。
- 同样为了可伸缩性,我们必须自动化模型选择和调整。典型的用户不会知道基于EWMA的异常检测器和基于LSTM的异常检测器之间的区别,更不用说如何调整它们了。乘以数千或数百万个指标,很明显我们必须实现自动化。
Adaptive Alerting是整个警报处理流程中的一环,Adaptive Alerting的主要目的是降低异常发现的平均时间(MTTD),它通过监听流式度量数据、识别候选异常、验证它们以避免误报并最终将它们传递给下游组件和响应系统来实现。整体流程如下图:
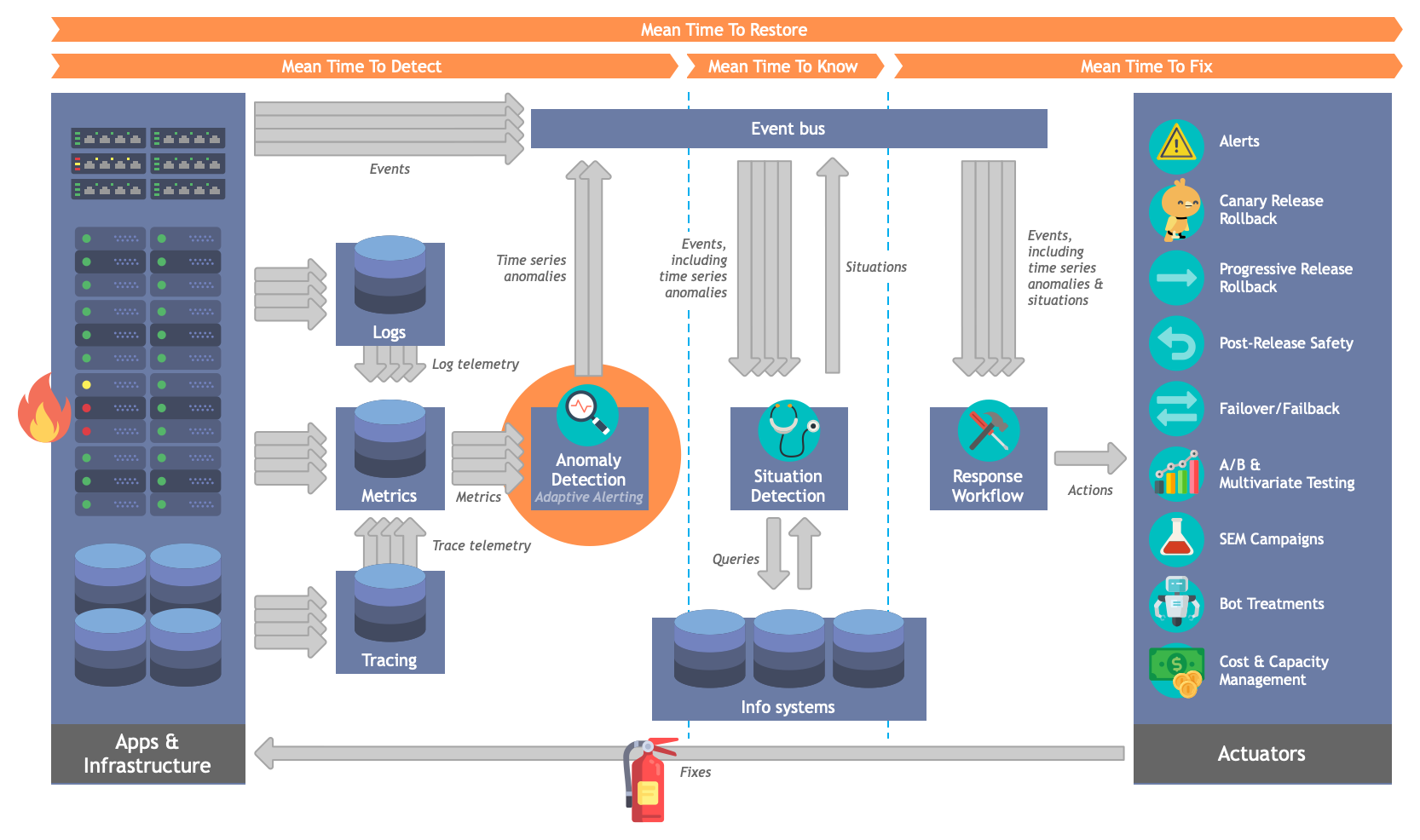
Adaptive Alerting的架构设计
从上图可知,Adaptive Alerting包含三部分主要内容:
- Anomaly Engine:异常引擎,其运行时接受来自任意时间序列度量源系统的传入度量流;将单个度量点分类为正常、弱异常或强异常;然后将它们传递给消费者系统,如警报管理系统(用于最终用户)和自动响应系统(用于解决问题的自动工作流)
- Model Building:模型构建系统,用于训练异常探测器下的某些模型
- Model Selection and Autotuning:模型选择和自动调参系统,自动选择最佳模型并针对给定指标进行调参
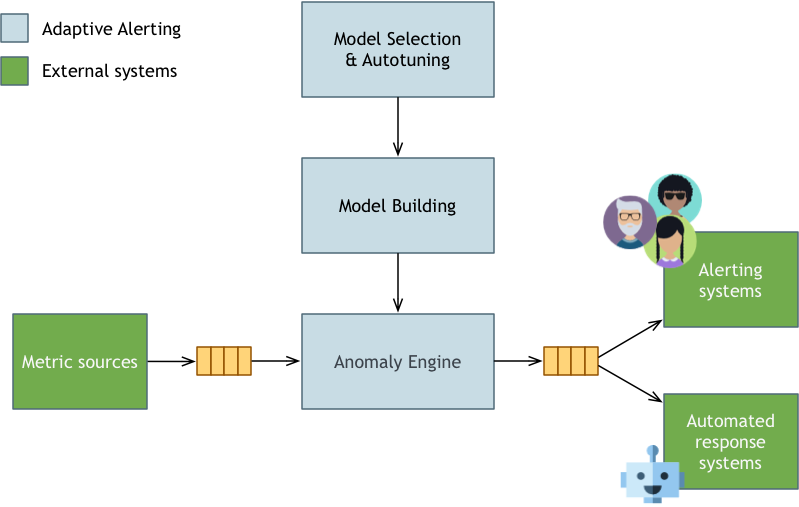
下图展示了系统的更多细节:
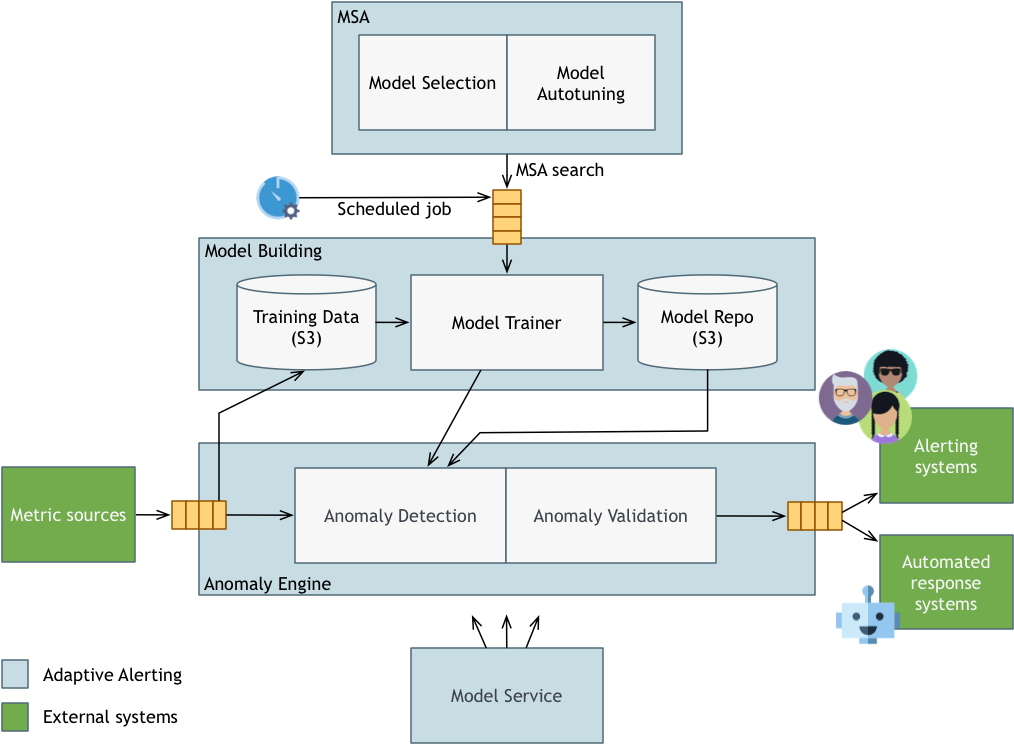
Anomaly Engine
正如我们上面提到的,异常检测系统的工作是处理输入的度量流,决定哪些点表示异常,并将信息传递给下游系统(最终用户警报和自动响应)。但现在我们可以看到一些关键部分:
- 一种度量路由器(图中未展示,但为异常检测的一部分),它确定任何给定的度量点,异常检测器将其发送到哪个异常检测器。本质上,是我们先查询数据来自哪个度量,然后在模型服务中查询映射关系。
- 一组异常检测器,其任务是快速确定给定点是否为异常。异常检测器通常通过将观测到的时间序列值与某个潜在时间序列模型产生的预测值进行比较来实现这一目的。如果观测距离预测”有点远”,异常检测器会将该点分为弱异常(该点距离预测有点远,需要进一步调查)或强异常(该点距离模型预测的相当远)。
- 一组异常验证器。任何熟悉监控系统的人都知道一个大问题是错误的警报——即使没有任何错误,也会出现警报。误报是不好的,因为它们会将注意力从”真实”的警报上转移开,并最终损害用户对系统的信心。为了让Adaptive Alerting以处理数百万个度量,我们需要对误报的数量进行严格限制,这就是异常验证的来源。在此,我们对候选异常进行更详细的检查,然后将其作为异常传递给下游系统。
Model Building
并非所有的时间序列模型都涉及离线训练,但很多有趣的模型都涉及离线训练。模型构建既包括训练作业的调度,也包括训练本身。
训练作业通过topic进入模型构建,它主要来自三个来源:
- 作为模型搜索过程的一部分运行的模型选择和自动调优作业
- 定期进行的模型重建
- 当”性能”检测器监测到模型匹配性能下降时的”性能重建”
在图中,您可以看到我们有一个用于训练数据的存储库和一个模型存储库。这两个都基于Amazon S3,至少目前是这样。其思想是,模型构建消耗训练数据并生成模型,然后将这些模型加载到异常检测系统中进行异常检测。训练数据通过连接传入度量主题和训练数据repo的管道到达。
Model Selection and Autotuning(MSA)
前面我们注意到需要代表用户执行自动模型选择和自动调参。”自动调整”部分在机器学习界被称为”超参数优化”(hyperparameter optimization,HPO)。以下是这些用准外行人的术语表达的意思:
- 模型选择是决定哪一类模型最适合于给定的时间序列。有许多不同的模型族,它们服务于不同的目的。例如,对于跟踪可用硬盘空间量的度量,或者对于表示某个给定事务的成功率的度量,我们可以选择使用常量阈值模型。另一方面,对于每日和每周季节性较强的指标,我们可能希望使用Twitter’s Seasonal Hybrid ESD、random cut forests或LSTM network。模型选择的挑战性任务是找到合适的模型族。
- 超参数优化(HPO)。为了从给定的族生成模型,我们运行机器学习训练算法。这些训练算法使用训练数据将模型”拟合”到数据中,这意味着找到该模型的参数值,从而在实际(非训练)数据上产生最佳性能。结果发现,算法本身就有需要选择的参数。这些算法参数(相对于模型参数)称为超参数。为一个给定的模型找到合适的超参数常常是一个充满挑战的过程。HPO的问题是自动搜索好的超参数。
一旦MSA找到正确的模型和超参数,它就会将此信息保存在模型服务中(见下文)。
Model Service模型服务
模型服务起到了辅助作用。它为其他Adaptive Alerting子系统提供数据服务。例如,MSA需要一个地方来保存它发现的度量到模型映射,而度量路由器需要一个地方来查找这些映射。模型构建需要知道哪些模型需要重建。异常检测需要将用户偏好存储在阈值敏感度附近。模型服务在体系结构中提供了一个共享位置来管理这类数据。
Adaptive Alerting的代码模块
代码库被组织成许多 Maven 模块:
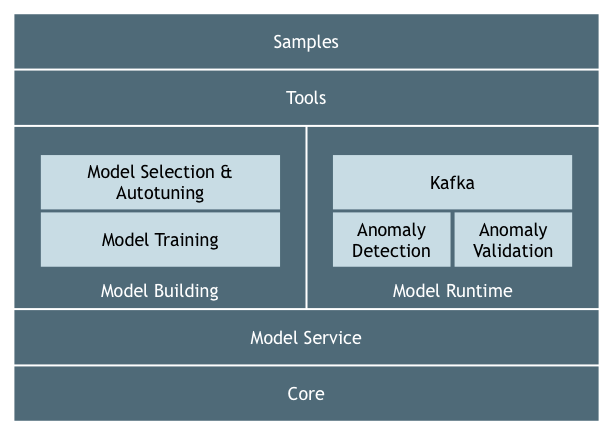
图中较高的模块依赖于图中较低的模块。例如,Samples 模块依赖于所有模块,所有模块都依赖 Core 模块。
下面是模块的简要描述:
- core:核心模块包含许多甚至所有其他模块想要使用的代码。这通常是实用程序代码,尽管域代码在某些情况下也是有意义的。例如,模型评估是跨多个模块的常见问题(我们用它来进行模型选择和自动调参、训练和模型性能监视),因此核心包含模型评估组件。
- modelservice:ModelService 模块包含如上所述的模型服务。
- modeltrain:某些异常检测模型需要离线训练。modeltrain 提供了一个接口,用于将模型训练算法附加到系统中,以便可以在模型选择和自动调参期间调用它们,或者作为模型进行的定期重新训练的一部分。我们预计这将主要是一个到外部训练算法的简要,比如在机器学习框架中,比如像 Tensorflow 这样的机器学习框架。这个想法是将这些模型作为 Docker 容器部署到 AdaptiveAlerting 环境中,并让 modeltrain 接口知道如何调用这些模型。
- msa 模块处理模型搜索和自动调优,如上所述。
- anomdetect:异常检测包含异常检测器以及模型性能监视器
- anomvalidate:异常验证模块包含异常验证器。
- kafka:kakfa 模块使其他模块可在 Kafka 中使用,比如说,我们将其用于异常检测模块、anomdetect 和 anomvalidate。
- tools:工具模块包含模型开发工具,例如数据源和可视化工具。
- samples:示例模块包含使用工具模块构建的示例数据管道。
AnomalyDetection 异常监测详解
异常检测概览
异常检测模块支持两阶段警报生成过程的第一阶段。在第一阶段,我们的目标是通过时间序列异常值分析快速识别候选异常。在第二阶段,在异常验证模块的支持下,我们旨在通过对候选异常进行更彻底的调查来消除误报。已验证的异常会生成警报。
异常检测架构
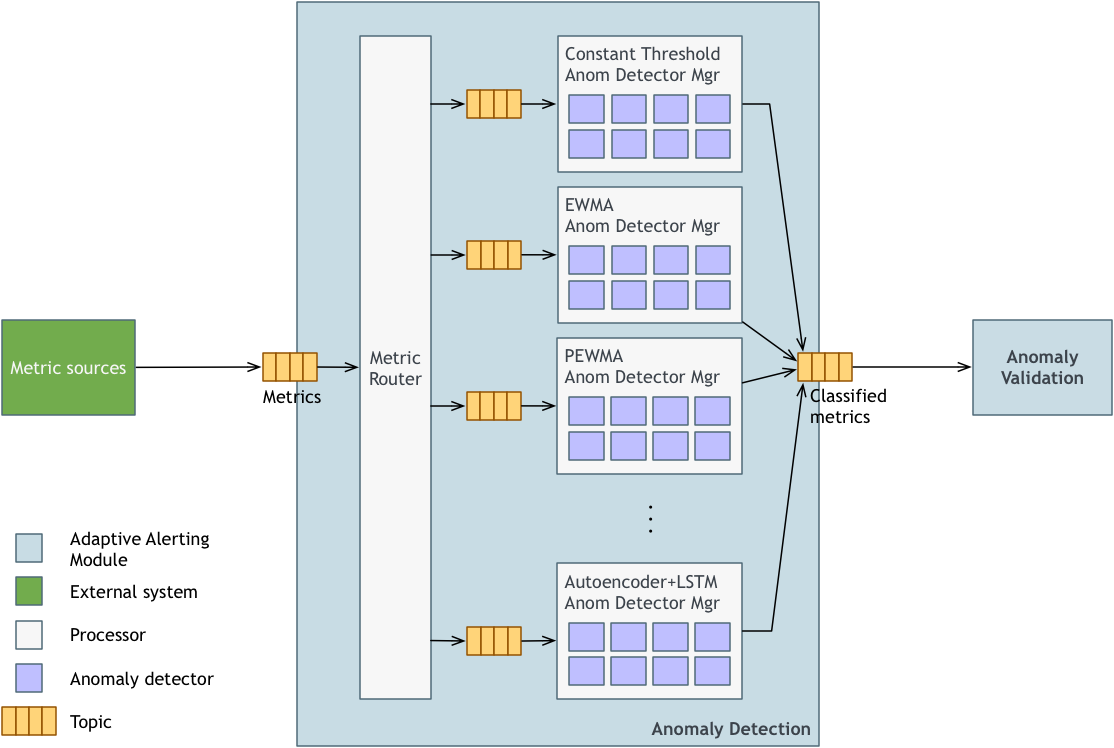
- 度量主题(Metric topic):这是接收所有传入度量的单个主题。(供讨论:针对不同消息格式的不同主题。有人讨论了同时支持 Metrics 2.0 和 Graphite 消息的必要性。需要解决这个问题。)
- 度量路由(Metric Router):度量路由将度量点路由到模型特定的异常检测器管理器。度量路由器使用模型服务来获取映射信息。
- 异常检测管理器(Anomaly Detector Managers):异常检测器管理器(ADM)管理大量给定类型的异常检测器。一般来说,一组 ADM 将协同工作以处理某些给定类型的度量。例如,一个 ADM 可能处理 10,000 个 EWMA 指标,另一个 ADM 可能处理不同的 10,000 个 EWMA 指标。
- 异常探测器(Anomaly Detectors):异常探测器是异常检测系统的核心。他们的工作是快速地将每个进来的度量点分类为正常、弱异常或强异常,然后将分类的度量点转移到下游进行进一步分析。
- 分类度量主题(Classified metric topic):在异常检测之后,每个度量点都有以下分类之一:正常、弱异常或强异常,异常检测器将分类的度量标准放在分类的度量主题上,异常验证系统将从中获取这些度量标准以进行进一步处理。
异常探测器剖析(Anatomy of an anomaly detector)
异常探测器的内部结构:
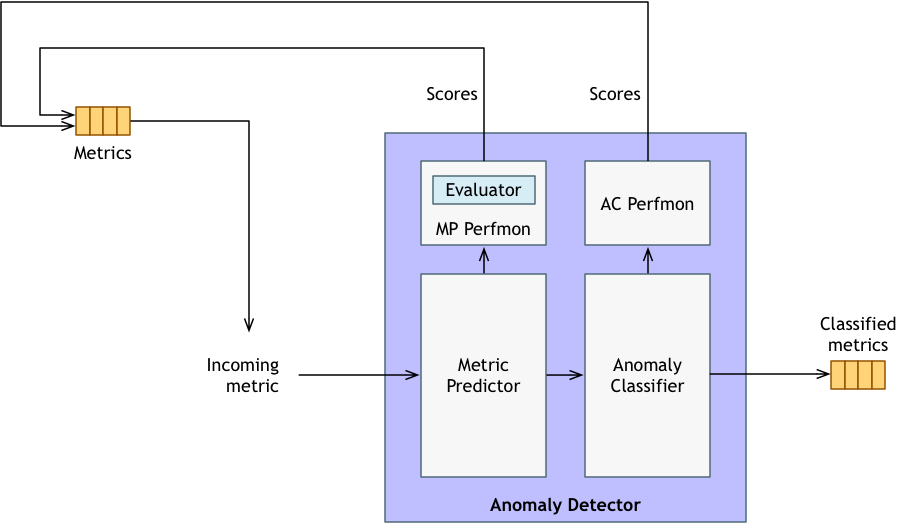
- 度量预测器(Metric Predictor):大多数异常检测器都有时间序列预测模型支持。预测允许我们通过观察预测误差,或者观察值和预测值之间的差异,为输入的指标分配数值的离群值得分。不同的预测模型有不同的分配离群值的方法。请注意,这些分数并不会立即转化为异常分类。它们只是一个数值分数,表明预测模型将度量点视为离群值的程度。这个分数成为下面分类模型的输入。
- 度量预测性能(Metric Predictor Perfmon):许多时间序列预测模型随着时间的推移变得“陈旧”。例如,当时间序列具有自上一个模型构建以来发生变化的潜在趋势,或者当模型具有自上一个模型构建以来发生变化的其他特征(如季节性)时,就会发生这种情况。通常这些模型有一个定期的重建计划,以避免这样的问题。不过,我们还有一个度量预测性能监视器,它应用RMSE和sMAPE等标准度量来为模型本身的性能打分。我们将这些得分反馈回度量主题,以便可视化和异常检测。(请注意,我们没有将这些性能系列叠加在一起,我们只做一层。)如果一个性能系列出现问题,我们可以将其挂接到一个外部补救工作流程,该工作流程可以启动一个模型构建,或者简单地将问题记录下来以便将来修正。
- 异常分类器(Anomaly Classifier):在时间序列预测之后,我们现在有了一个离群值得分。异常分类器的工作就是将该分值转化为正常、弱异常或强异常的分类。例如,这可能是将任何 2 sigmas 作为弱异常处理,而将 3 sigmas 作为强异常处理。这通常是我们根据用户的反馈进行调整的判断,因为我们通常没有给定分类是否正确的“基本事实”。也许有一种方法可以捕获用户的反馈,并将其纳入分类器训练中,这正是我们感兴趣的探索。
- 异常分类器性能(Anomaly Classifier Perfmon):目前这是一个占位符组件,主要是用来传达异常分类器原则上可以执行好或差的想法。(也就是说,当出现警报时,即使我们不知道,事实上是否有一些潜在的过程实际上发生了变化,从而产生了异常值。)在已知基本事实的情况下,常常使用F1 score(参见precision/recall)。
时间序列预测模型列表(List of time series prediction models)
常量阈值 Constant threshold(备注:这不是时间预测模型)
对给定的时间序列应用用户选择的常数阈值。一个阈值用于弱异常,另一个阈值用于强异常。这部分与Seyren类似。目前常量阈值检测器是单尾的,这意味着检测器检查的值是太低(左尾)或太高(右尾),但不是两者兼有。我们将加强探测器,以便在某一时刻允许双尾检查。
指数加权移动平均 Exponentially Weighted Moving Average指数加权移动平均(EWMA)模型一方面是当前观测值的加权和,另一方面是历史观测值的加权和。该模型在范围[0,1]中有一个单一的参数$\alpha$,用于确定当前值与历史值的相对权重。对当前的观察值赋予更多的权重,使得模型对变化的响应更加灵敏,但是更容易出现过度拟合。
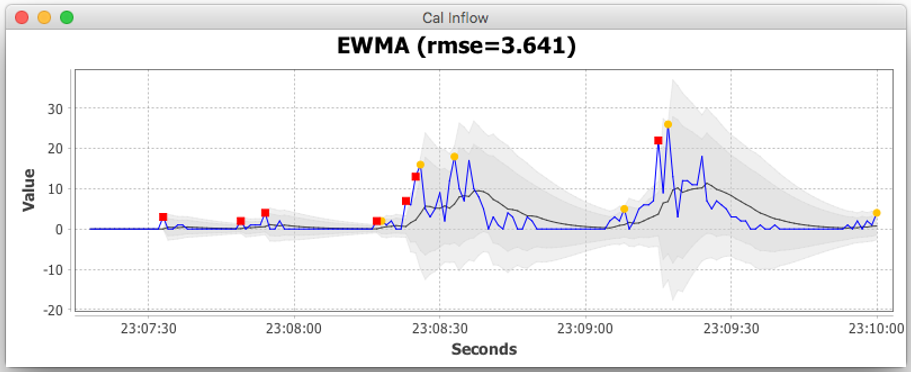
参见:https://en.wikipedia.org/wiki/Moving_average#Exponential_moving_average
概率指数加权移动平均 Probabilistic Exponentially Weighted Moving Average
PEWMA模型是EWMA模型的一个修正版本。该模型估计给定观测值的概率(基于假设正态分布的残差和方差的连续估计),然后降低不可能观测值的权重。在范围[0,1]中的第二个参数$\beta$控制了减权的程度。当$\beta=0$时,PEWMA降低为EWMA。
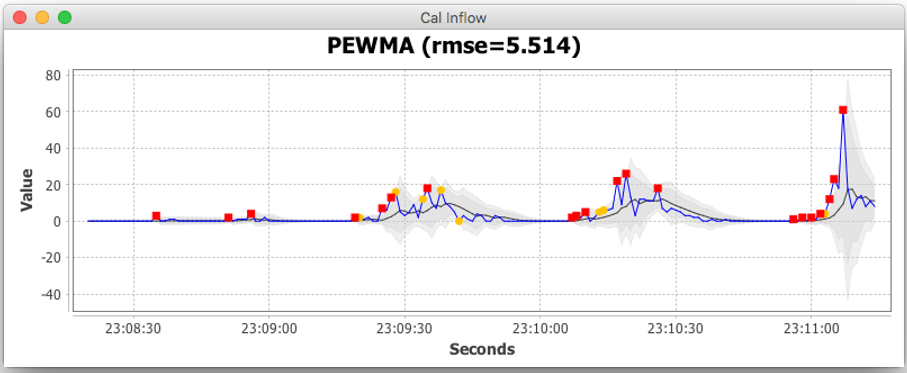
更多关于PEWMA(和EWMA)的信息,参见Anomaly Detection Using AWS IoT and AWS Lambda
模型评估器列表 List of model evaluators
平方根误差 Root Mean Square Error (RMSE)
参见:https://en.wikipedia.org/wiki/root-mean-square_deviation
未来的模型和评估器
这是目前感兴趣的一些算法:
- Cumulative Sum (CUSUM)
- Random Cut Forest
- Twitter Seasonal Hybrid ESD
- LSTM with autoencoders
- Aquila, based onSeasonal Trend Decomposition Using Loess
下面是一些感兴趣的模型评估器:
异常验证详解
误报是大多数监控系统面临的一个主要挑战。他们强迫用户花时间验证单个警报,这工作量太大。这会导致错过警报并使得整个监控系统并不那么有用。处理误报的一个重要策略是使用准确的异常检测模型。时间序列模型应该是准确的,离群值得分到离群值分类的映射也应该是准确的。这是异常检测模块的领域。不幸的是,这还不足以解决问题。在大多数真实时间序列中,噪声和异常之间存在重叠。换言之,有时噪声产生的数据点具有比与较小异常相关的数据点更大的异常值分数。
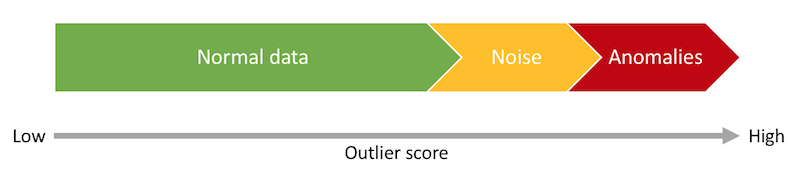
为了解决预测误差的“irreducible”部分,Adaptive Alerting包括异常验证模块。这里的想法是寻找超出异常值分数的证据,以证实或否认所谓的异常。
研究过程需要更多的时间来执行,但这就是为什么我们将异常引擎分为异常检测阶段和异常验证阶段。异常检测阶段可以快速识别候选异常,但由于不可减少的错误,会产生比我们希望看到的更多的误报。异常验证阶段比较慢,但我们只在异常检测器分类为异常的度量点的小子集上运行。
我们讲首先查看整个流程(flow),然后查看底层模块的架构。
异常验证流程 Anomaly Validation flow
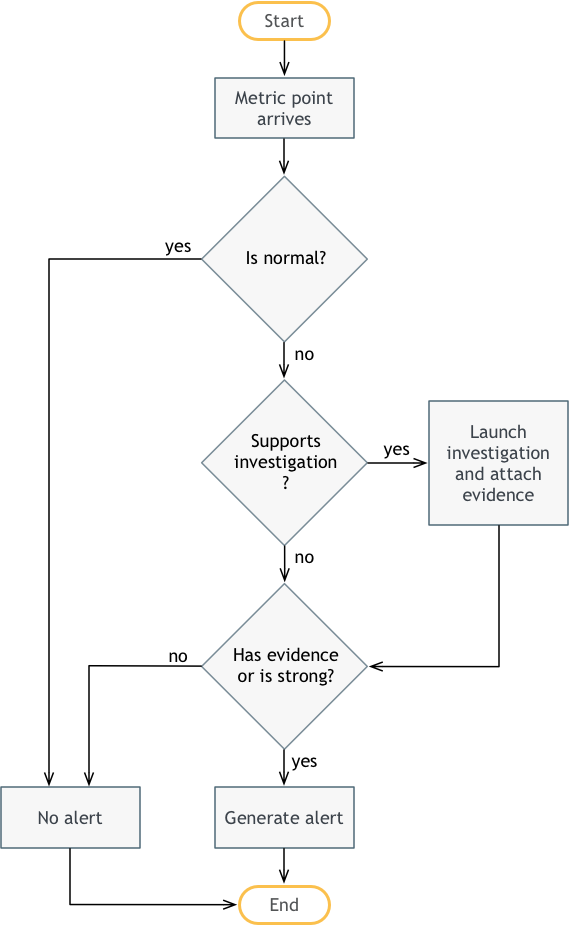
下面是发生的事情:
- 首先,一个分类的度量点从异常检测模块进入异常验证模块。分类为正常、弱异常或强异常。
- 如果度量点是正常的,则结束时不生成警报。
- 如果定义了针对异常的调查,那么我们就启动这些调查,并将我们发现的任何证据附加到异常上。
- 不管有没有调查,现在我们必须决定是否发出警报。如果调查发现了证据,或者异常很强,那么我们就会发出警报。否则,我们会在没有警报的情况下结束。
否则,我们检查异常是否有相关的调查过程。调查过程只是我们可以执行的一组附加查询,以确认异常是“真实的”,而不仅仅是噪音。这可能是针对 Splunk、ServiceNow 或任何其他可用的后端系统的查询,以帮助验证异常。通常,调查与更高级别的业务或应用程序度量(例如,预订下降、应用程序 KPI)相关,而不是与更低级别的系统度量相关。
这就是过程。现在让我们看看底层架构。
异常验证架构
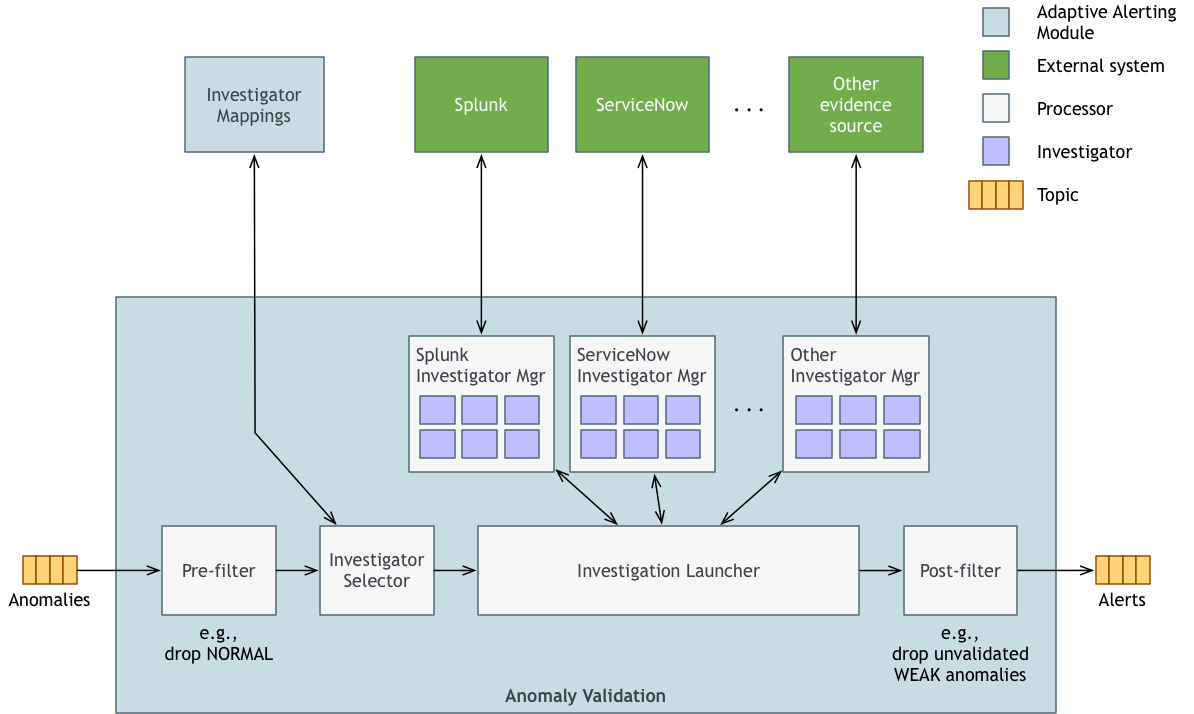
- 预过滤器(Pre-filter):预过滤器会删除我们可以立即从考虑中排除的任何度量点。例如,我们知道我们不想为正常数据点生成警报,所以我们只是在这里删除正常的数据点。
- 调查员选择器(Investigator Selector):预滤后进入调查阶段。关键是要找到产生警报的确凿证据。这种证据通常是为了寻找可能的原因,例如应用程序错误,这将解释预订下降的原因。但证据也可能是寻找相关的影响。例如,如果我们看到酒店预订量下降,我们可能会注意到同时发生的航班预订量下降和汽车预订量下降。如果我们在同一时间看到所有这些东西,那么很可能酒店预订量下降是“真实的”,即使我们不知道是什么原因造成的。进入调查阶段的入口点是调查员选择器。调查员选择器查找与所述度量相关联的任何调查员。并非所有指标都有相关调查人员。一般来说,与较低级别的系统度量相比,较高级别的业务或应用程序度量更有可能具有调查员。无论如何,选择器会找到任何映射的调查者。
- 调查发射器(Investigation Launcher):如果度量有一个或多个调查员,那么调查员发射器会并行地启动他们。调查人员必须在短时间内交还调查结果。这是可配置的,30 秒是典型的时间限制。调查发射器合并所有的证据(如果有的话)并将其放在异常上。
- 调查员经理(Investigator Managers):调查员经理帮助相关调查员组成小组。这里的“相关”一般指的是查询同一给定源系统的调查员。例如,Splunk 调查员可能有一个调查员经理,ServiceNow 调查员可能有另一个调查员经理。
- 调查人员(Investigators):调查人员进行实际调查。调查人员可以有很多不同类型——这取决于你所处环境中存在的证据来源。例如,在 Expedia,我们在 Splunk 中有大量的日志数据,在 ServiceNow 有大量的更改数据(软件发布、A/B 测试、网络路由更改等)。相应地,我们有调查人员知道如何查询这些系统,以找出哪些应用程序正在生成事件峰值,哪些最近发生的变化等等。
- 后过滤器(Post-filter):后过滤器在生成警报之前执行最后一次过滤。这里和预滤器中的过滤行为最终将是可配置的,但现在,后滤器仅在调查生成至少一个异常证据或异常是强异常时生成警报。换言之,我们忽略了没有证据支持的弱异常。
参考链接:https://github.com/ExpediaDotCom/adaptive-alerting/wiki


