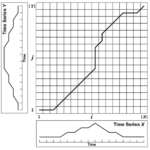
DTW简介 DTW(Dynamic Time Warping)是一种用于比较时间序列之间相似性的算法。它可以有效地处理在时间轴上存在偏移、缩放和扭曲等变形的时间序列数据。DTW算法通过对两个时间序列进行动态规整,将它们按最优路径…
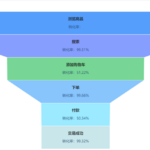
当一些转化率指标发生波动时,往往需要分析原因,以转化率为例,影响转化率变化的可能因素有: 流量结构发生了变化,部分高转化的渠道或低转化的渠道的流量发生了较大的变化 部分渠道的转化发生了变化 …
针对个人的知识体系的管理,用的比较多的可能是各类云笔记工具。但是的云笔记工具又有非常多的类型,自己在选择的时候也非常的纠结,这里仅做一些简单的盘点,看选择哪种类型的软件更加合适。 一、以 Evernote 为…
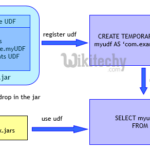
Hive内置了很多函数,可以参考Hive Built-In Functions。但是有些情况下,这些内置函数还是不能满足我们的需求,这时候就需要UDF出场了。 UDF全称:User-Defined Functions,即用户自定义函数,在Hive SQL编译成Ma…
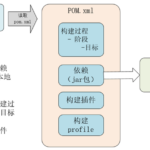
Maven 是一个强大的 Java 项目构建工具,基于 POM (项目对象模型) 文件,可用于项目构建、依赖模块管理和 Javadoc 生成等。构建工具是软件构建过程自动化的一种工具。一个软件项目的构建通常包含以下几部分: 生…
针对 Facebook Prophet 的使用,很多年以前就整理过一篇文章《Facebook 时间序列预测工具 fbprophet》,过了 N 年以后当重新需要使用这个工具的时候,发现部分内容已经更新,中间的很多细节内容都没有表述清楚。实…
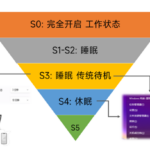
平时下班的时候会将笔记本直接塞书包里。有时候到家拿出来发现非常的烫,给我的感觉是盒盖后电脑还一直在运行,于是花时间研究了下 Windows 下的睡眠和休眠机制。 官网上 Windows 的睡眠和休眠状态介绍 睡眠 睡眠…
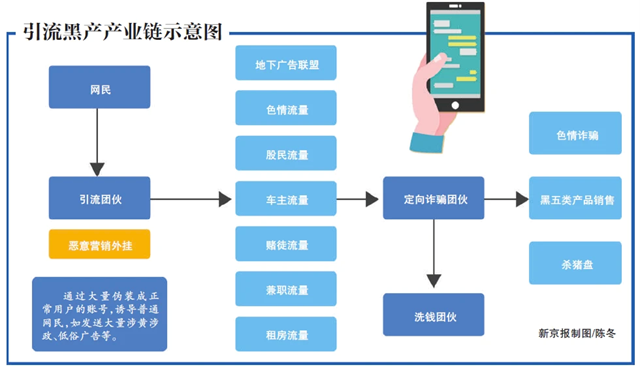
黑灰产的英文翻译是 Black Market,被定义为通过人工方式或者技术手段实施的操纵网络信息内容,获取违法利益、破坏网络生态秩序的行为。对很多人来说,黑灰产的代名词就是“薅羊毛”。实际上,除了薅羊毛,每个行业都…
JAVA开发与运行环境 Java的开发和运行环境是指在进行Java应用程序开发和执行过程中所需的软件和工具。下面分别介绍Java的开发环境和运行环境: Java开发环境(Java Development Environment): JDK(Java …

家里的电脑比较多,安装了不同的 Windows 版本,从 Windows XP、Win&、Win 8.1、Win 10、Win 11 都有。由于 Office 版本在部分操作系统无法安装,且不同的 Office 对系统的要求不同。特梳理下不同操作系统下最合适…






