随着人工智能技术的爆发式发展,个人知识管理的范式正在被深刻重塑。传统的笔记软件依赖人工整理与记忆关联,效率存在瓶颈。如今,基于 AI 的工具能够理解内容、自动建立连接、智能问答,将静态的知识库转化为动态…

pprint(Pretty-Printer)是Python标准库中一个用于美化输出复杂数据结构的模块,特别适用于嵌套较深或元素较多的字典、列表、元组等。相比普通的print(),它能自动格式化输出,使其更具可读性。 主要特点 …

PyClustering简介 PyClustering 是一个功能丰富的数据挖掘库,特别专注于聚类分析、振荡网络和神经网络。PyClustering 是一个算法覆盖面广、实现质量高的库,特别在以下方面表现突出: 聚类算法全面性:从经…

scikit-learn-extra简介 scikit-learn-extra 是 scikit-learn 的一个官方扩展工具包,专为提供那些新颖、专用或尚未纳入主库的机器学习算法而设计。它完全兼容 scikit-learn 的 API 规范,让你能在熟悉的生态里,…

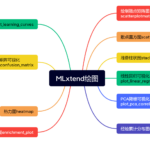
Mlxtend 简介 Mlxtend 是一个Python开源库,全称为 “machine learning extensions”(机器学习扩展)。由 Sebastian Raschka 创建并维护,其核心目标是提供一系列在日常数据科学和机器学习任务中非常实用的工具和扩…
WinGet简介 作为微软官方出品的 Windows 包管理器,WinGet 旨在让 Windows 上的软件管理像在 Linux 中使用 apt或 yum一样高效、便捷。它通过命令行帮你发现、安装、升级、卸载和配置应用程序,特别适合开发者和IT…
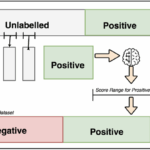
什么是 PU Learning? PU Learning 的全称是 Positive-Unlabeled Learning,即正例-无标记学习。它是一种在半监督学习范畴内的特殊机器学习设定。 与传统的监督学习(数据有明确的“正例”和“负例”标签)不同…
Newspaper3k Newspaper3k 是一个专门用于新闻文章抓取和内容提取的Python库。该项目由 Lucas Ou-Yang 开发,灵感来源于Requests库的简洁性,底层使用lxml实现高效解析。 核心特性 文章内容提取 自…

CSS的基本概念 CSS 是什么? CSS 的全称是 Cascading Style Sheets,中文翻译为 层叠样式表。 样式表 (Style Sheets):意味着它是一套规则集,用于指定网页上元素(如文本、图片、布局)应该如何被呈现(即“…

Coze简介 Coze(中文名“扣子”)是字节跳动推出的一站式AI应用开发平台,旨在降低AI应用开发门槛,让用户无需编程经验即可快速创建、调试和部署各类AI智能体(如聊天机器人、自动化工具等)。以下将从平台定位、核…