Dubbo简介 Apache Dubbo是一个高性能的Java RPC(Remote Procedure Call)框架,最初由阿里巴巴开源,并在2018年成为Apache软件基金会的孵化项目。Dubbo专为提供微服务架构中的服务治理和服务通信而设计,广泛应用…
PostgreSQL 简介 PostgreSQL 是一个功能强大、开源的对象关系型数据库管理系统(ORDBMS),以其可靠性、特性丰富和性能卓越而闻名。它最初于 1986 年由加州大学伯克利分校的计算机科学研究团队开发,目前由全球开…

Hazelcast简介 Hazelcast是一个流行的开源内存计算平台,提供分布式缓存、数据网格、流处理和计算功能。它被设计为一个高性能、易于使用的解决方案,适合需要快速数据访问和处理的应用场景。 核心功能 内存数据…
Apache Ignite简介 Apache Ignite是一个分布式数据库、内存缓存和计算平台,旨在提供高性能、高可用性和可扩展性的实时数据处理能力。它可以在内存中存储和处理数据,从而显著提高数据访问速度和计算效率。 产生…
Apache Hama简介 Apache Hama是一个开源的分布式计算框架,主要用于大规模图处理和机器学习任务。它最初是作为Apache软件基金会的一个项目,旨在提供一种高效的计算模型,能够处理大规模的数据集。 核心特点 Bu…

最近在使用搜狗输入法的时候,发现其会给右键菜单加上很多乱七八糟的东西。尝试使用Windows右键管理工具ContextMenuManager,发现过了一会时间还是会再次加上。针对这种流氓行为实在是不能忍。于是对输入法进行了一…

FlatBuffers简介 FlatBuffers是由Google开发的一种高效的跨平台序列化库,专为需要快速访问序列化数据的应用场景而设计。与传统的序列化格式相比,FlatBuffers提供了更高的性能,尤其是在游戏开发和实时数据处理等…

Cap'n Proto简介 Cap'n Proto是一种高效的二进制序列化库,由Kenton Varda开发并开源。它旨在提供比其他序列化格式(如Protocol Buffers和JSON)更高的性能和更低的内存开销。Cap'n Proto的设计重点在于零拷贝访问…

MessagePack简介 MessagePack是一种高效的二进制数据序列化格式,旨在提供JSON的功能,但具有更紧凑的二进制表示。它被设计为在不同语言之间进行高效的数据交换,同时保持对人类可读格式的透明支持。 核心特性 …

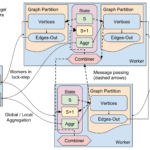
Pregel简介 Pregel是由 Google 提出的一个专门用于大规模图计算 的分布式系统框架,旨在高效处理超大规模图数据,如社交网络、Web 图、道路网络等。Pregel 的设计受 Google MapReduce 成功经验的启发,但针对图计算…