Greenplum是一个开源的分布式数据仓库系统,基于PostgreSQL构建,专为大规模数据分析和处理设计。它采用共享无架构(shared-nothing architecture),通过将数据分布到多个节点上并行处理,实现高性能的数据存储和查询能力。

核心特性
- 分布式架构:
- Greenplum使用共享无架构,将数据水平分片到不同的节点,每个节点独立存储和处理数据。
- 这种架构提高了系统的可扩展性和性能,能够处理PB级别的数据。
- 并行处理:
- 支持大规模并行处理(Massively Parallel Processing, MPP),通过在多个节点上同时执行查询来加速数据处理。
- 提供高效的查询优化和执行计划,能够充分利用集群资源。
- 基于PostgreSQL:
- 继承了PostgreSQL的丰富特性,包括复杂SQL查询支持、事务处理、丰富的数据类型和扩展能力。
- 提供与PostgreSQL兼容的SQL接口,易于迁移和集成。
- 高级分析功能:
- 支持复杂的分析功能,包括窗口函数、子查询、CTE(公用表表达式)等。
- 提供机器学习和数据挖掘扩展(MADlib),支持高级数据分析和建模。
- 灵活的数据存储:
- 支持多种数据存储格式,包括行存储和列存储,用户可以根据查询模式选择合适的存储方式。
- 提供压缩和分区功能,优化存储空间和查询性能。
使用场景
- 大规模数据分析:适合处理需要高并发和低延迟的大规模数据分析任务,如商业智能(BI)和数据仓库应用。
- 复杂查询和报告:支持复杂的SQL查询和实时报告,适合需要复杂数据分析的应用场景。
- 机器学习和数据挖掘:通过MADlib扩展,Greenplum支持在数据库内进行机器学习和数据挖掘。
- ETL处理:通过高效的数据加载和转换能力,Greenplum可以用于大规模的ETL(提取、转换、加载)任务。
优势
- 高性能:通过MPP架构和并行处理,Greenplum能够高效处理大规模数据。
- 可扩展性:支持水平扩展,能够轻松增加节点以提高处理能力。
- 丰富的功能:继承PostgreSQL的强大功能,并提供高级分析和机器学习扩展。
- 开源和社区支持:作为开源项目,Greenplum拥有活跃的社区和丰富的生态系统。
Greenplum的架构
Greenplum是一个基于PostgreSQL的开源数据仓库软件,设计用于处理大规模并行数据处理(MPP)。其架构允许在大规模数据集上执行快速查询和分析。
MPP架构
Greenplum的核心是其大规模并行处理架构。MPP允许将数据和查询负载分布到多个节点上,以便并行处理。这种架构通过水平扩展来提高性能和容量。MPP(Massively Parallel Processing,大规模并行处理)架构是一种用于处理和分析大规模数据集的计算架构。它通过将计算任务分解并分布到多个处理器或节点上并行执行,从而提高计算效率和处理能力。
简单来说,MPP是将任务并行的分散到多个服务器和节点上,在每个节点上计算完成后,将各自部分的结果汇总在一起得到最终的结果(与Hadoop相似)。
MPP(大规模并行处理)架构
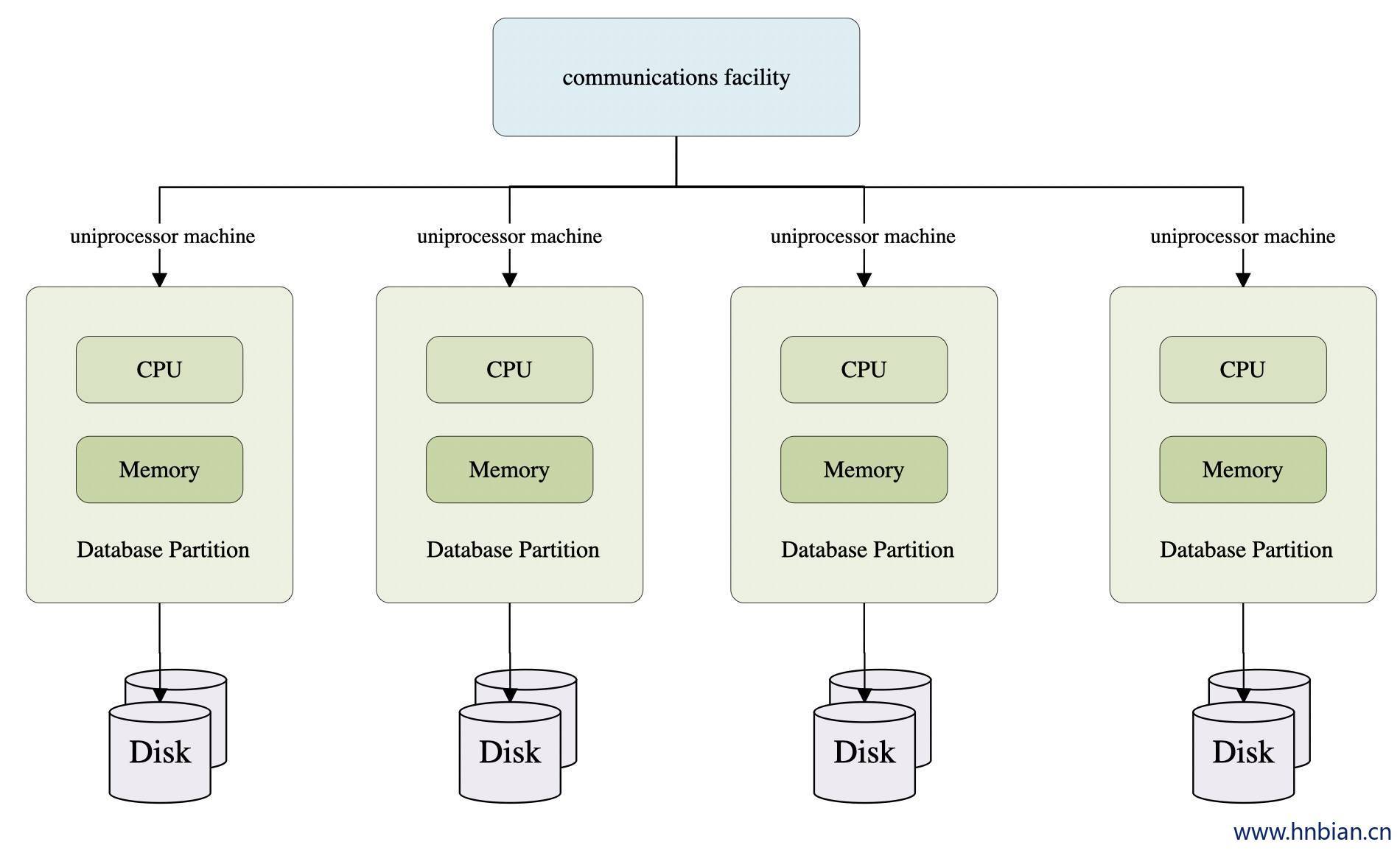
它由多个SMP服务器通过一定的节点互联网络进行连接,协同工作,完成相同的任务,从用户的角度来看是一个服务器系统。其基本特征是由多个SMP服务器(每个SMP服务器称节点)通过节点互联网络连接而成,每个节点只访问自己的本地资源(内存、存储等),是一种完全无共享(Share Nothing)结构,因而扩展能力最好,理论上其扩展无限制。
Greenplum架构
Greenplum是典型的Master/Slave架构,在Greenplum集群中,存在一个Master节点和多个Segment节点,每个节点上可以运行多个数据库。Greenplum采用shared nothing架构(MPP),典型的Shared Nothing系统汇集了数据库、内存Cache等存储状态的信息,不在节点上保存状态的信息。节点之间的信息交互都是通过节点互联网络实现的。通过将数据分布到多个节点上来实现规模数据的存储,再通过并行查询处理来提高查询性能。每个节点仅查询自己的数据,所得到的结果再经过主节点处理得到最终结果。通过增加节点数目达到系统线性扩展。
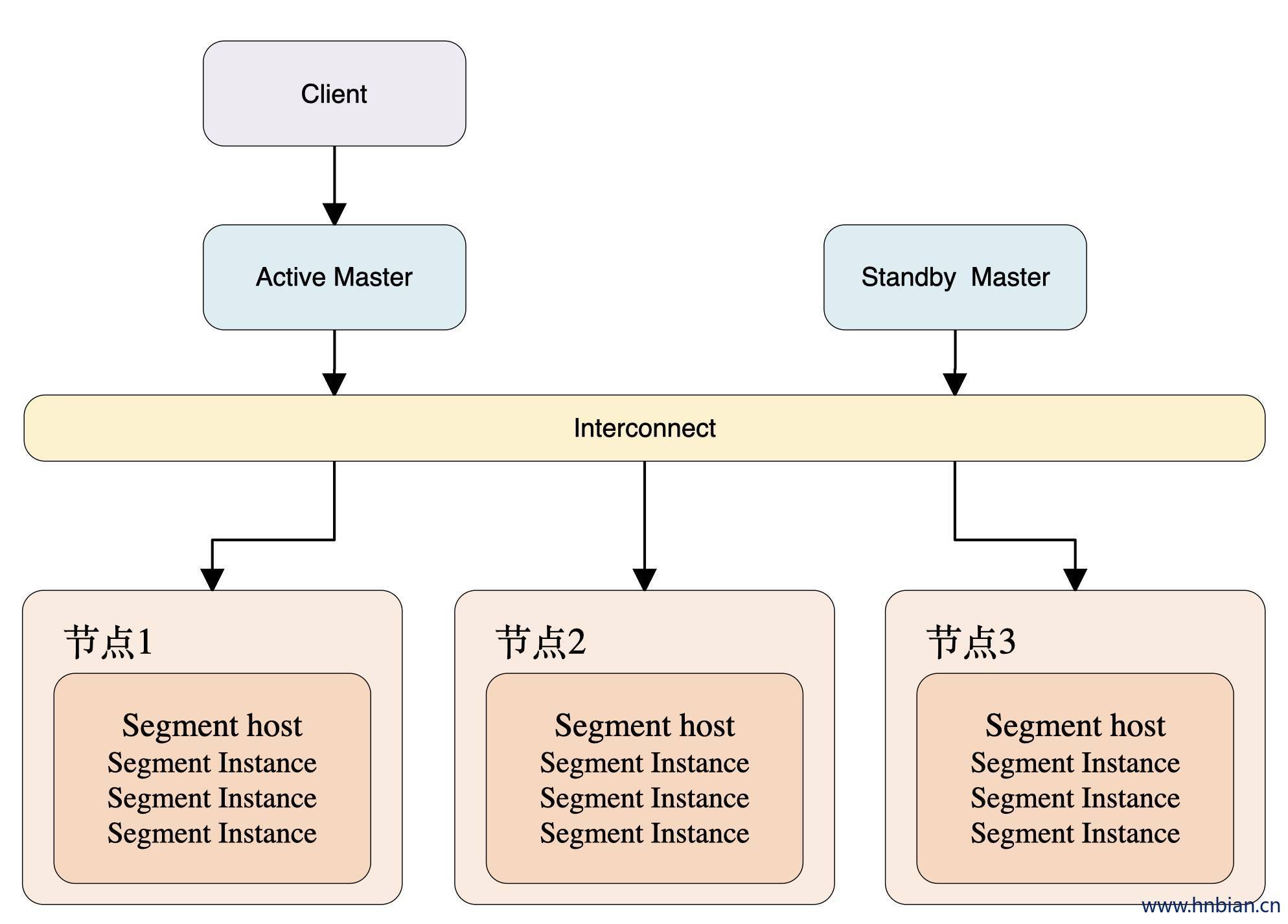
上图为Greenplum的基本架构,客户端通过网络连接到gpdb,其中Master是GP的主节点(客户端的接入点),Segment Host是子节点(连接并提交SQL语句的接口),主节点不存储用户数据,子节点存储数据并负责SQL查询。主节点负责相应客户端请求并将请求的SQL语句进行转换,转换之后调度后台的子节点进行查询,并将查询结果返回客户端。
Master节点
Greenplum的Master节点在整个集群架构中扮演着至关重要的角色。它是系统的控制中心,负责处理客户端连接、查询解析和优化,以及协调各个Segment节点的工作。
角色与功能
- 客户端接口:Master节点是客户端与Greenplum集群交互的入口。所有的SQL查询和管理命令首先由Master节点接收。
- 查询解析与优化:
- Master节点负责将客户端提交的SQL查询解析为内部表示。
- 使用查询优化器生成高效的执行计划,以便在Segment节点上并行执行。
- 任务调度与分发:
- 将优化后的查询计划分发到各个Segment节点。
- 负责协调Segment节点之间的通信和数据传输。
- 系统目录管理:
- Master节点维护全局系统目录,存储关于数据库对象(如表、视图、索引等)的元数据。
- 目录信息用于查询解析和优化。
系统目录
- 元数据存储:
- 系统目录存储数据库的元数据,包括表结构、用户信息、权限等。
- 任何对数据库对象的更改都会更新系统目录。
- 全局一致性:
- Master节点确保系统目录的一致性和完整性,以支持正确的查询解析和执行。
查询处理流程
- 接收查询:
- 客户端将SQL查询发送到Master节点。
- 解析查询:
- Master节点将SQL查询解析为语法树。
- 优化查询:
- 使用查询优化器生成执行计划,考虑并行执行和数据分布。
- 分发查询计划:
- 执行计划被分发到各个Segment节点进行并行处理。
- 结果汇总:
- 各个 Segment 节点处理完后,将结果返回给 Master 节点。
- Master 节点汇总并返回最终结果给客户端。
高可用性
- 故障恢复:
- Master 节点通常配置为高可用,以防止单点故障。
- 可以使用备用 Master 节点进行故障切换和恢复。
- 备份与恢复:
- 定期备份系统目录和相关数据,以支持数据恢复和灾难恢复。
性能与扩展
- 性能优化:
- 通过优化查询解析和计划生成过程,提高查询执行效率。
- 管理和监控 Segment 节点的负载以保持系统性能。
- 扩展能力:
- 虽然 Master 节点本身不负责数据存储,但其性能可能成为瓶颈,因此需要适当的硬件配置和优化。
Master 节点是 Greenplum 集群中至关重要的组件,负责系统的控制和管理。通过高效的查询解析和优化机制,Master 节点确保整个集群的高性能和高效性。
Segment 节点
在 Greenplum 数据仓库系统中,Segment 节点是实际存储数据和执行查询的工作单元。它们是 MPP(大规模并行处理)架构的核心组件,通过分布式计算实现数据的并行处理。以下是对 Segment 节点的详细介绍:
角色与功能
- 数据存储:
- Segment 节点负责存储数据库中的实际数据。每个 Segment 节点运行一个 PostgreSQL 实例。
- 数据按照一定的分片策略分布在多个 Segment 节点上。
- 查询执行:
- 接收从 Master 节点分发的查询计划,并在本地执行相应的查询操作。
- 处理数据的选择、投影、聚合、连接等操作。
- 并行处理:
- 各个 Segment 节点独立且并行地处理数据,充分利用集群的计算资源。
- 通过并行处理,提高数据查询和分析的速度。
数据分片与分布
- 数据分片(Sharding):
- 数据库表的数据按照某种策略(如哈希、范围分片)分片,并分布在不同的 Segment 节点上。
- 分片策略影响数据的均匀分布和查询性能。
- 数据均衡:
- 为了避免负载不均和性能瓶颈,数据在所有 Segment 节点之间应尽可能均匀分布。
查询处理流程
- 接收查询计划:
- 从 Master 节点接收分发的查询计划。
- 执行查询操作:
- 在本地数据库上执行计划中的操作,如扫描、过滤、聚合等。
- 数据交换:
- 根据查询需要,可能需要在 Segment 节点之间交换数据。
- 使用 Interconnect 层进行高效的数据传输。
- 结果返回:
- 将本地计算的结果返回给 Master 节点,或者参与进一步的计算和汇总。
网络互连(Interconnect)
- 数据传输:
- Segment 节点通过 Interconnect 网络层进行数据交换。
- 通常使用高速网络(如 InfiniBand、10GbE)来确保低延迟和高吞吐量。
- 通信模式:
- 支持多种通信模式,如广播、单播和多播,适应不同的查询需求。
高可用性与容错
- 数据冗余:
- Segment 节点可以配置为镜像模式,提供数据冗余以防止单点故障。
- 当一个 Segment 节点失效时,其镜像节点可以接管工作,确保系统的连续性。
- 故障恢复:
- 支持自动故障检测和恢复机制,减少节点故障对系统的影响。
性能与扩展
- 扩展能力:
- 通过增加 Segment 节点数量来水平扩展系统的存储容量和计算能力。
- 新增节点后,系统会自动重新分布数据以保持均衡。
- 性能优化:
- 通过调优分片策略和优化查询执行,提高 Segment 节点的处理效率。
Segment 节点是 Greenplum 集群的计算和存储基础,通过并行处理和分布式存储实现大规模数据集的高效查询和分析。其设计目标是通过扩展节点数量来提升系统性能,以应对不断增长的数据处理需求。
Interconnect
在 Greenplum 数据仓库系统中,Interconnect 是节点之间进行通信的网络层,它在整个 MPP(大规模并行处理)架构中起着关键作用。Interconnect 负责在 Master 节点和 Segment 节点之间,以及各 Segment 节点之间传输数据,以支持并行查询处理和结果汇总。
角色与功能
- 数据传输:
- Interconnect 负责将数据在 Master 和 Segment 节点之间,以及 Segment 节点之间传输。
- 支持查询执行过程中需要的数据交换,如数据分发、聚合和连接操作。
- 通信管理:
- 管理节点之间的通信会话,确保数据在正确的时间和地点被正确的节点接收。
- 处理数据包的路由和传输控制。
通信模式
- 单播(Unicast):
- 数据从一个节点发送到另一个特定节点。
- 常用于点对点的数据传输。
- 广播(Broadcast):
- 数据从一个节点发送到所有其他节点。
- 用于需要将数据分发到所有节点的操作。
- 多播(Multicast):
- 数据从一个节点发送到多个特定节点。
- 适用于需要将数据分发到部分节点的情况。
性能特点
- 高吞吐量:
- Interconnect 使用高速网络(如 InfiniBand 或 10GbE)以确保高数据吞吐量,支持大规模数据集的快速传输。
- 低延迟:
- 通过优化网络协议和数据包传输路径,尽可能降低延迟,以提高查询响应速度。
- 可靠性:
- 实现可靠的数据传输,确保数据包在网络传输过程中不丢失或损坏。
- 使用错误检测和恢复机制来处理网络传输中的异常情况。
技术实现
- TCP/IP 协议:
- Greenplum 的 Interconnect 通常基于 TCP/IP 协议实现,以利用现有网络基础设施。
- TCP 提供可靠的、面向连接的数据流传输服务。
- 自定义优化:
- 可能包含自定义的网络协议优化,以适应特定的硬件环境和应用需求。
扩展与管理
- 网络配置:
- 配置网络拓扑和参数,以支持集群的扩展和性能优化。
- 需要考虑网络带宽、节点数量和物理连接的布局。
- 监控与调优:
- 监控网络性能,识别潜在的瓶颈和故障。
- 通过调优网络设置和查询计划,优化数据传输效率。
重要性
- 关键组件:
- 作为 Greenplum 系统的核心组件,Interconnect 的性能直接影响到整个集群的查询速度和数据处理能力。
- 确保高效的数据传输对于实现 MPP 架构的高性能至关重要。
Interconnect 是 Greenplum 数据仓库系统中实现高效并行处理的关键,通过优化的数据传输机制和可靠的网络协议,支持大规模数据集的快速查询和分析。其设计目标是提供高吞吐量和低延迟的通信能力,以满足复杂数据处理任务的需求。
Greenplum 的使用
数据加载和导出
在 Greenplum 数据仓库系统中,数据加载和导出是关键操作,涉及将数据高效地导入和导出系统。Greenplum 提供多种工具和方法来处理这些任务,以满足不同的性能和数据集成需求。
数据加载
- gpload 工具:
- 基于 Python 的 ETL 工具,使用外部表和 COPY 命令来加载数据。
- 支持 CSV、文本文件等格式。
- 提供批量加载功能,适合大规模数据集。
- COPY 命令:
- 直接在 SQL 中使用 COPY 命令从文件或标准输入加载数据。
- 支持多种格式,如 CSV、文本、二进制等。
- 可以指定分隔符、转义字符和 NULL 表示等选项。
- 外部表(External Tables):
- 通过创建外部表,可以直接从文件系统或 HDFS 中读取数据。
- 支持数据流式加载,无需将数据全部加载到内存。
- 常用于处理大数据集和与 Hadoop 集成。
- gpfdist(Greenplum File Distribution):
- Greenplum 提供的轻量级文件分发服务,优化并行数据加载。
- 在多个 Segment 节点上并行读取数据,显著提高加载速度。
- 适合用于大规模数据加载场景。
- 外部数据源(External Data Sources):
- 通过 Greenplum 外部数据源框架,可以从外部数据库(如 Oracle、MySQL)中加载数据。
- 支持通过 JDBC、ODBC 等接口进行连接和数据提取。
数据导出
- gpfdist:
- 除了用于数据加载,gpfdist 也可以用于数据导出。
- 将数据从 Greenplum 导出到外部文件,支持并行写入,提高导出速度。
- COPY TO 命令:
- 使用 COPY TO 命令将数据从表中导出到文件。
- 支持多种格式和选项,类似于 COPY FROM 命令。
- 外部表:
- 通过定义写入外部表,将数据直接写入文件系统或 HDFS。
- 适用于需要与 Hadoop 生态系统集成的场景。
- SQL 查询结果导出:
- 通过 SQL 查询将结果直接导出到客户端应用程序,适合小规模数据集或临时分析。
通过合理选择和配置这些工具和方法,Greenplum 用户可以实现高效的数据加载和导出,满足大数据环境下的性能和集成需求。
示例 SQL 操作
-- 创建数据库 CREATE DATABASE example_db; -- 连接到数据库 \c example_db -- 创建表 CREATE TABLE example_table ( user_id INT, event_time TIMESTAMP, event_type TEXT ) DISTRIBUTED BY (user_id); -- 插入数据 INSERT INTO example_table VALUES (1, '2023-10-01 10:00:00', 'login'); -- 查询数据 SELECT user_id, COUNT(*) AS event_count FROM example_table WHERE event_time > '2023-10-01 00:00:00' GROUP BY user_id;


