SingleStore简介
SingleStore(以前称为MemSQL)是一种现代化的分布式SQL数据库管理系统,专为实时分析和事务处理设计。它结合了行存储和列存储技术,能够在单一平台上支持混合事务和分析处理(HTAP)。SingleStore的架构允许在大规模分布式环境中进行高效的数据存储和查询。
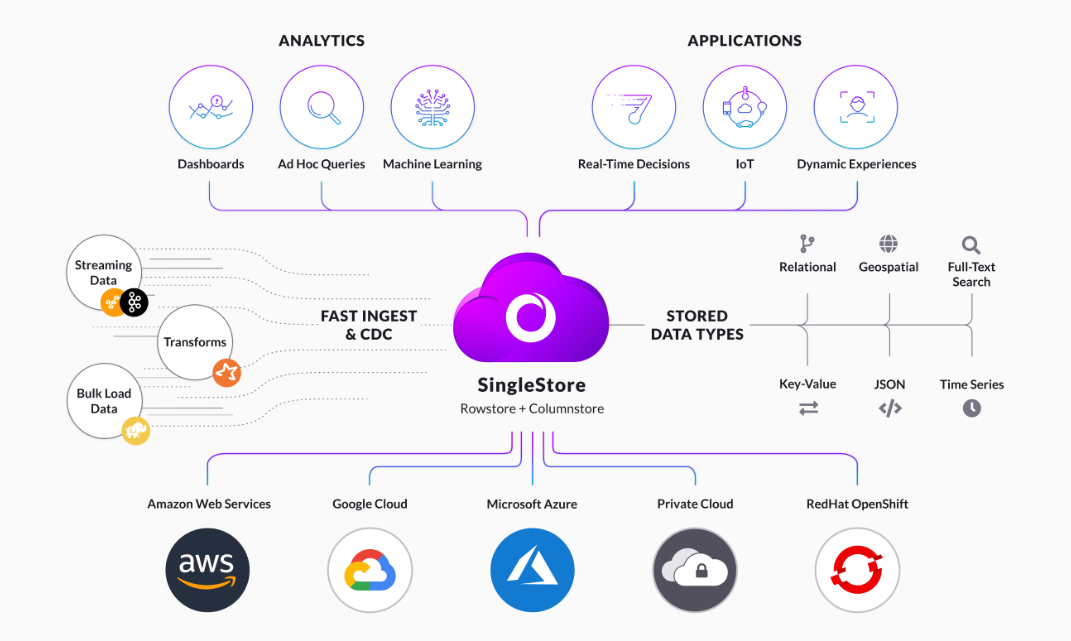
核心特性
- 混合事务和分析处理(HTAP):
- 支持同时处理在线事务处理(OLTP)和在线分析处理(OLAP),无需数据迁移。
- 通过行存储和列存储的结合,实现高效的事务处理和快速的分析查询。
- 分布式架构:
- 支持水平扩展,通过增加节点来提升性能和容量。
- 数据自动分片和负载均衡,确保系统的高可用性和可靠性。
- 实时分析:
- 提供实时数据摄取和分析能力,支持复杂查询和大规模数据处理。
- 通过内存计算和列存储技术,实现低延迟的分析查询。
- 高性能:
- 通过内存优化、分布式计算和并行处理,提供极高的查询和事务吞吐量。
- 支持SIMD指令和向量化执行,以提高计算效率。
- SQL支持:
- 兼容ANSI SQL,支持复杂查询、索引、存储过程和触发器。
- 提供与现有SQL工具和应用的集成能力。
- 云原生和多云支持:
- 支持在各种云平台和本地环境中部署,提供灵活的部署选项。
- 提供自动化管理和弹性扩展功能,适应动态的业务需求。
SingleStore的架构
- 行存储和列存储:
- 行存储用于事务处理,适合频繁的读写操作。
- 列存储用于分析查询,适合大规模数据扫描和聚合。
- 分布式计算:
- 使用分布式查询执行和数据分片技术,实现高效的并行处理。
- 支持数据的自动分片和重分布,确保负载均衡和高可用性。
- 内存优化:
- 内存中存储热数据,提高数据访问速度和事务处理性能。
- 支持持久化存储,确保数据的安全性和持久性。
- 高可用性和故障恢复:
- 支持多副本机制,确保数据的高可用性和容错性。
- 提供自动故障检测和故障转移机制,确保系统的连续运行。
SingleStore的原理
HTAP-统一数据存储
业界的HTAP解决方案
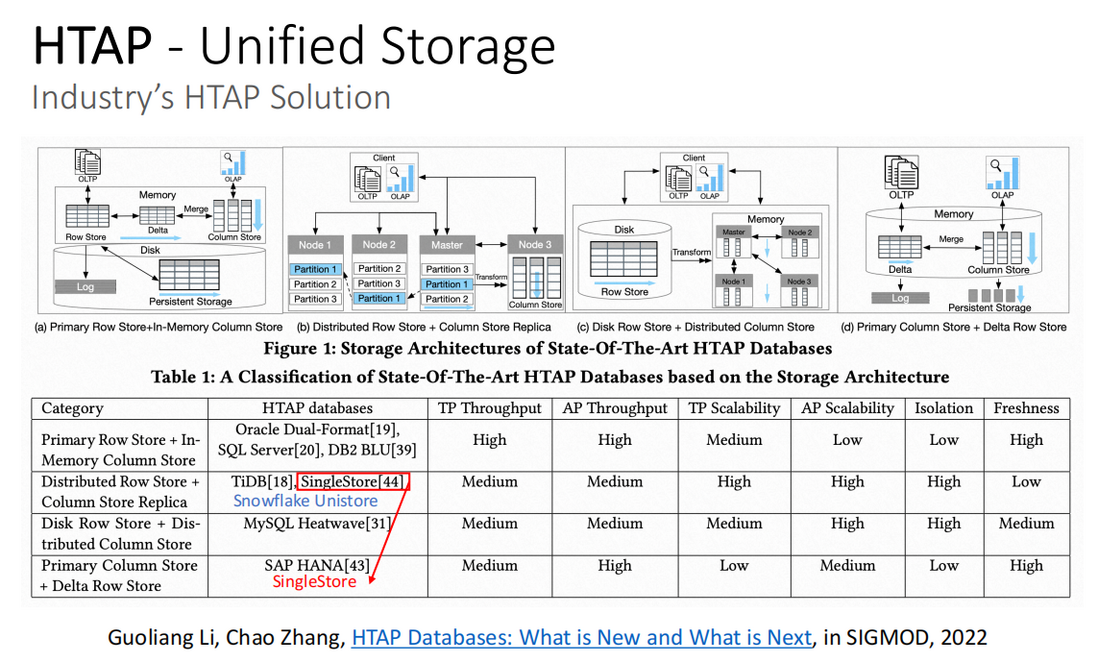
2022发表在SIGMOD的这篇论文《HTAP Database: What is New and What is Next》中,介绍了HTAP数据库的架构。HTAP数据库主要分为四部分:
- 主行存储+内存中列式存储(Primary RowStore+In-Memory ColumnStore)
- 分布式行式存储+列式存储副本(Distributed RowStore+ColumnStore Replica)
- 磁盘行式存储+分布式列式存储(Disk RowStore+Distributed ColumnStore)
- 主列存储+增量行式存储(Primary ColumnStore+Delta RowStore)
值得注意的是,在下表中列出的典型数据库,在论文发表后,其中一些数据库有了新的发展方向:SingleStore数据库已经不再是”分布式行式存储+列式存储副本”,而属于第四部分”主列存储+增量行式存储”数据云公司Snowflake于近期发布Unistore存储引擎,属于第二部分”分布式行式存储+列式存储副本”
SingleStore的HTAP特性
- 一份统一存储
- In-Memory行存储
- On-Disk列存储
- 主键唯一性约束
- 二级索引
- 细粒度数据读取
- Row-Level Locking(行级锁)
一份统一存储副本
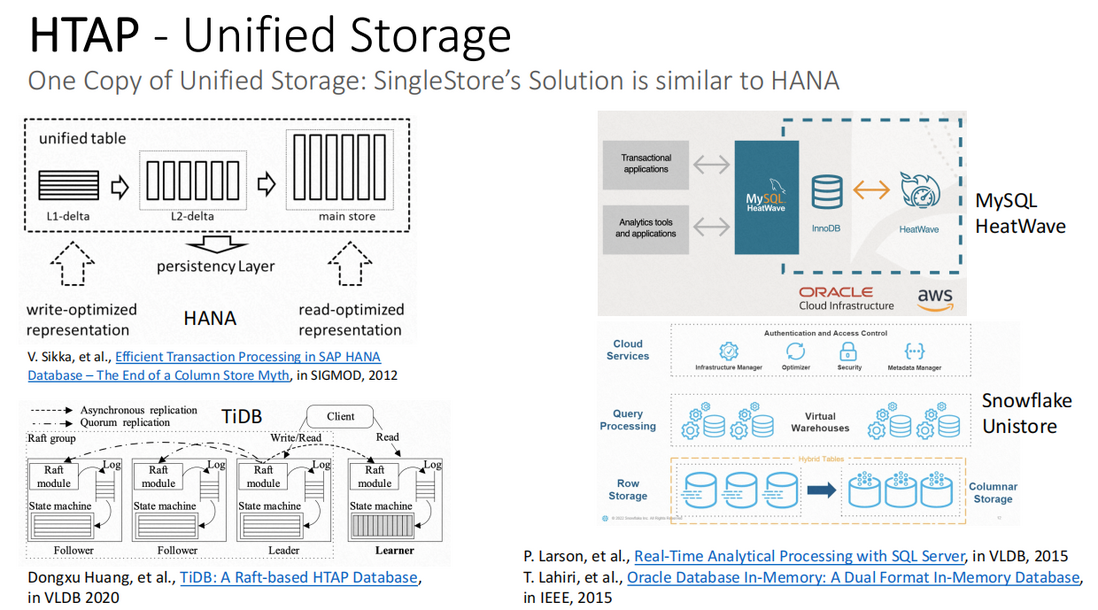
SingleStore的解决方案与HANA类似。下图列举了HANA、TiDB、MySQL HeatWave和Snowflake四个数据库的架构,从架构中可以看到,只有HANA是一份存储,而TiDB、MySQL HeatWave和Snowflake都是两份存储。
相关参考:
- Sikka, et al., Efficient Transaction Processing in SAP HANA Database–The End of a Column Store Myth, in SIGMOD, 2012
- Dongxu Huang, et al., TiDB: A Raft-based HTAP Database, in VLDB 2020
- Larson, et al., Real-Time Analytical Processing with SQL Server, in VLDB, 2015
- Lahiri, et al., Oracle Database In-Memory: A Dual Format In-Memory Database, in IEEE, 2015
基于Skiplist的内存中行存储和基于LSM树的磁盘列存储
如下图所示,左边是基于Skiplist的In-Memory行式存储架构,右边是基于LSM树的磁盘列式存储架构:
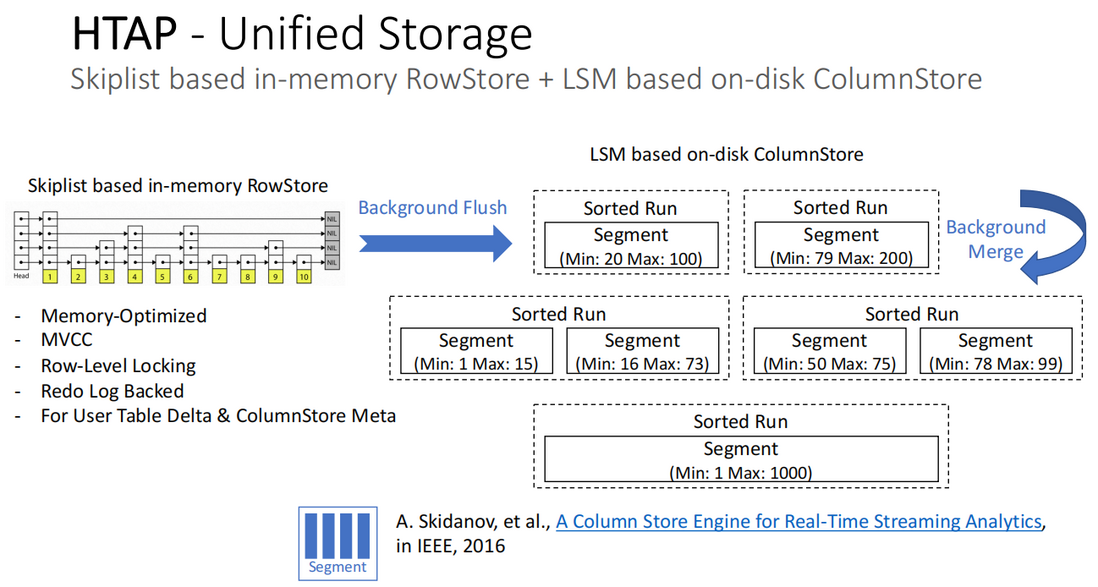
- 基于Skiplist的In-Memory行存储,具备的能力包括:
- 内存优化
- MVCC(多版本并发控制)
- Row-Level Locking(行级锁)
- Redo Log 支持
- 提供给用户表 Delta 部分和列存储 Meta 部分
- 基于 LSM 树的 On-Disk 列存储
- 内存中行存储被 flush 到磁盘形成以列存组织的 segment 文件;
- segment 文件会被组织到不同的 SortedRun 中,每个 SortedRun 有 min/max 值,一个 SortedRun 中可以包含一个或多个 segment 文件,如果包含多个 segment 文件,需要确保文件之间的 min/max 不会重叠
- SortedRun 的优势在于,如果扫描过滤列中带有排序列,每个 SortedRun 只需要访问一次 segment 文件即可;
- 当有空闲资源时,SortedRun 之间会进行 background merge,确保每个 SortedRun 中的 segment 文件足够大,实现最佳的扫描过滤效果。
相关参考:
- Skidanov, et al., A ColumnStore Engine for Real-Time Streaming Analytics, in IEEE, 2016
列式存储的主键和二级索引
SingleStore 数据库采用的索引方式,是 2 层结构的组合方式,如下图所示,包括:Data Segment 和 Global Hash index。
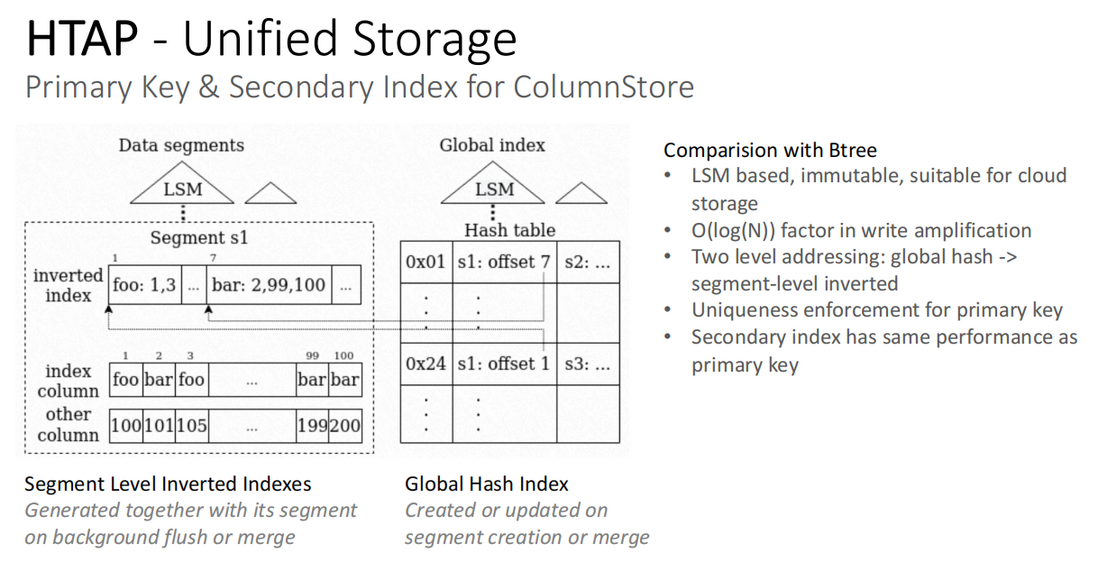
- Data Segment
- 在每个 segment 内部,对索引列建立一个 Inverted Index(倒排索引),每个列存文件都对应一个倒排索引
- Segment 的 flush 或合并都会生成新的 segment,同时伴随生成新的索引
- Global Hash Index
- 每个 segment 创建时都会对应创建一个 Hashtable,记录每个列存文件所在的 segment 以及 offset 值
- Segment 创建或合并后会创建新的 Hashtable
- SingleStore 的索引方式与 Btree 的不同在于:
- 基于 LSM,Immutable,适用于云存储
- O(log(N)) 写放大
- 二级定址:global hash -> segment-level inverted
- 主键的唯一性强制执行
- 二级索引与主键具有相同的性能
这种索引方式对于高性能点查必不可少。
细粒度 Subsegment 访问实现有效的点查找
可搜索的列式存储:
- 搜索位置由主键或二级索引确定
- 列编码支持 bit-packing、字典编码(dictionary)、游程长度编码(run-length encoding)和 LZ4 编码等
- 一个列支持跨 segment 选择不同编码
- 压缩单位是紫色的 subsegment 层级(见下图)。

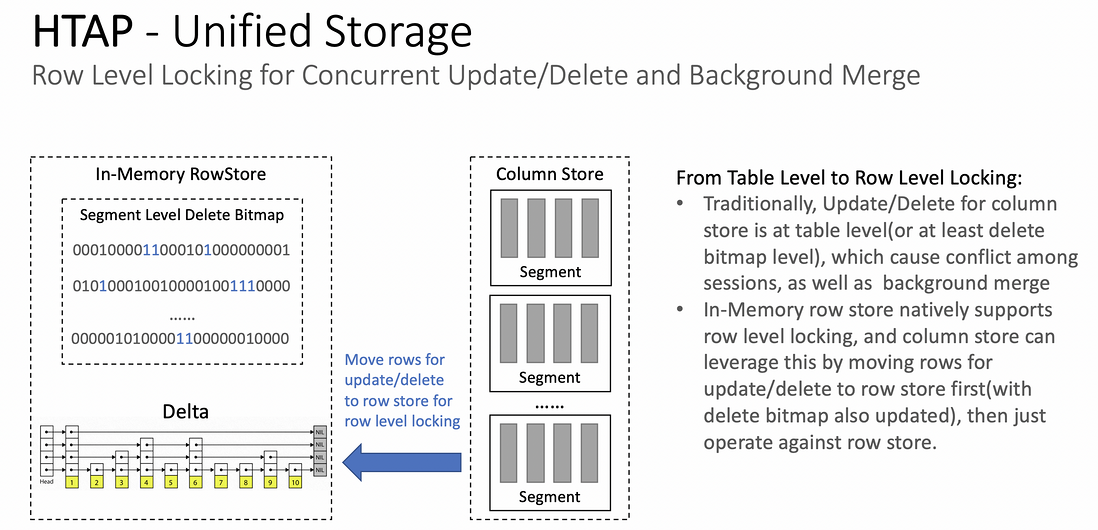
行级锁在并发更新/删除和后端合并中的应用
从表级锁到行级锁的转变:
- 传统方式中,列存储的更新/删除是在表级别(或 delete bitmap 级别),这会引起前端并发更新/删除的会话之间的冲突,以及后端合并的冲突
- 基于 Skiplist 的 In-Memory 行式存储原生的支持 level locking,并且列式存储可以利用这一点,首先将需要更新/删除的行移动到行存中(同时在 delete bitmap 中标记),然后只对行存储进行操作
- 因此,利用行式存储实现列式存储的行级锁,让列式存储也可以进行并发更新/删除
云原生-存储和计算分离
业界的云原生解决方案
业界的云原生解决方案中,比较典型的有以下三个:
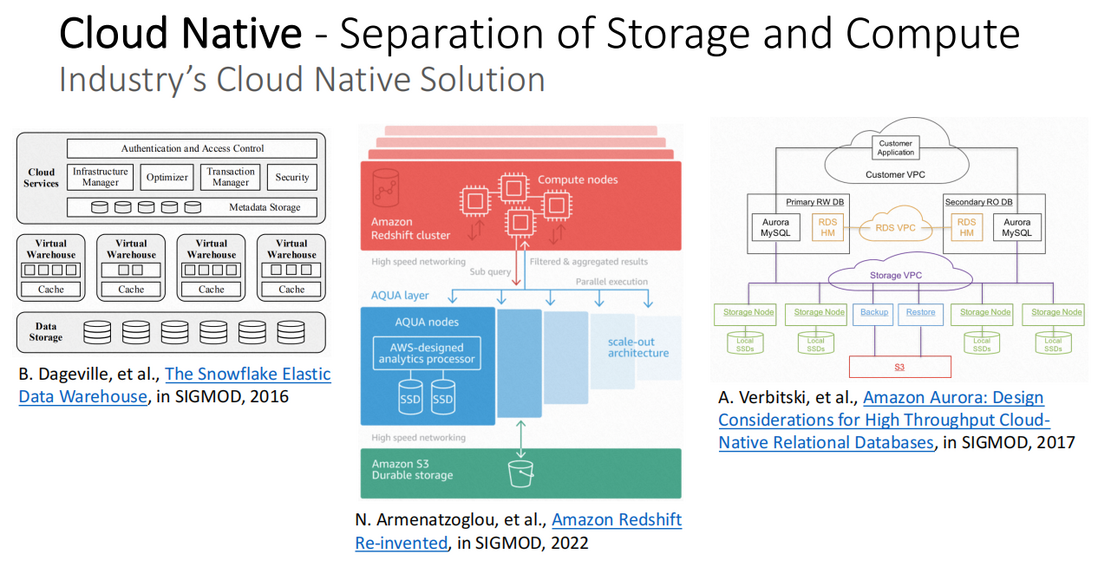
- Snowflake:Dageville, et al., The Snowflake Elastic Data Warehouse, in SIGMOD, 2016
- Redshift:Armenatzoglou, et al., Amazon Redshift Re-invented, in SIGMOD, 2022
- Aurora:Verbitski, et al., Amazon Aurora: Design Considerations for High Throughput Cloud Native Relational Databases, in SIGMOD, 2017
SingleStore 的云原生架构的特性
- 通过综合利用本地内存+本地 SSD+基于数据热度的远程云存储以支持 HTAP 工作负载
- 这里的云存储指 S3/OSS 这类低成本对象存储器
- 为了实现高吞吐低延迟的 TP 需求,事务提交路径不会写穿到远程云存储
- OSS 延迟大概是 20 毫秒
- 支持在云存储中的快照和 redo log 存储的快速 PITR
- 支持多种只读副本(在 SingleStore 称作 workspace,与 Snowflake 的虚拟仓库类似),以实现 HTAP 工作负载的隔离和扩展
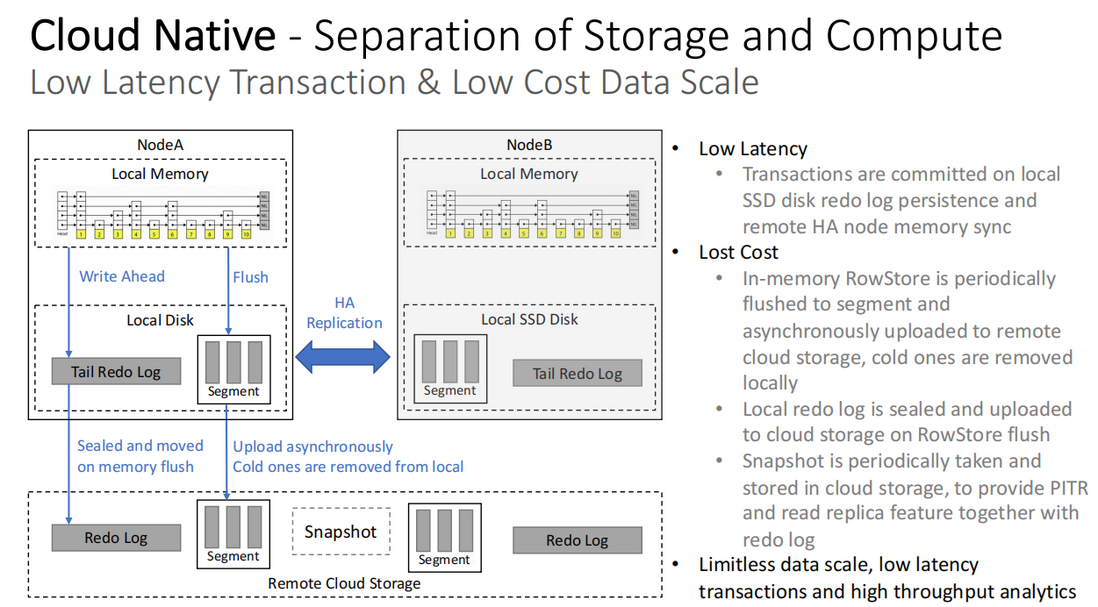
低延迟事务和低成本数据规模
- 低延迟:事务写入本地 SSD 磁盘 redo log 以确保持久性,并同步到远程 HA 节点内存中
- 低成本:
- In-Memory 行式存储会定期 flush 到本地盘的 Segment,并且异步上传到远程云存储,同时本地冷数据会定期移除,以减少本地空间占用
- 将行存储 flush 之前的 redo log 密封并上传到远端云存储,本地盘只保留 tail redo log
- 快照也会定期被整理并存储到云上,提供 PITR 和只读副本能力以及 redo log
- 基于以上能力可以实现无限的数据规模、低延迟事务和高吞吐量分析
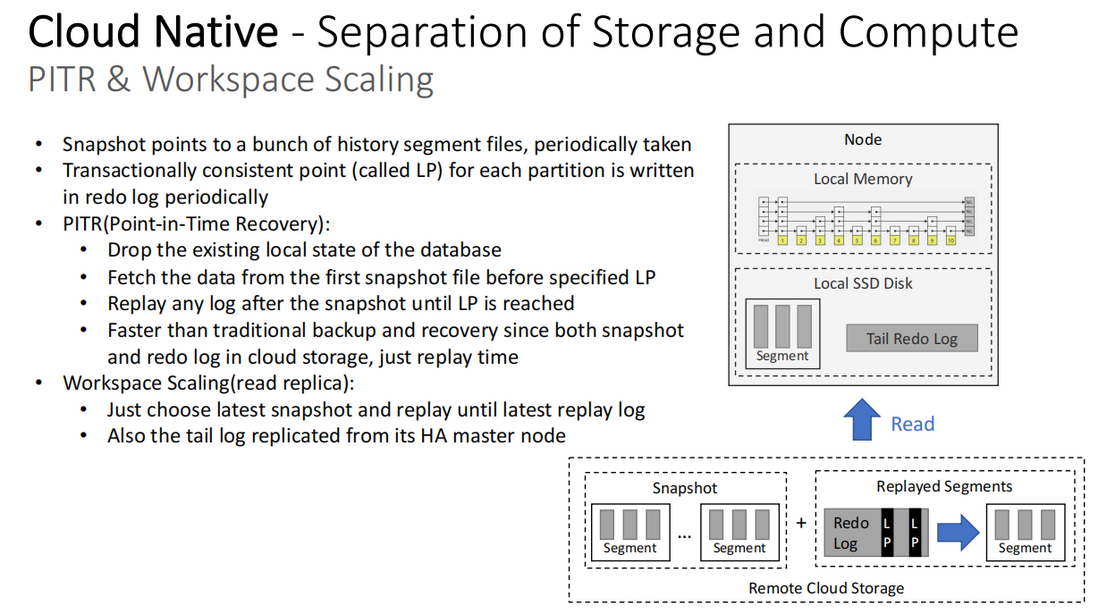
PITR 和 Workspace 扩展能力
- 快照指向一堆定期获取的历史 segment 文件
- 每个 partition 的事务一致性点(称为 LP,Logpoint)都会定期写入 redolog
- PITR(Point-in-Time Recovery,时间点恢复)
- 删除数据库当前的本地状态
- 从指定 LP 前的第一个快照文件中获取数据
- 根据这个快照的 redolog 起始点一直重放 log 直到达到 LP
- 由于快照和 redolog 都在云上存储,因此比传统的备份和恢复速度快得多
- Workspace 扩展能力(只读副本)
- 选择最后一个快照并重放到最近的一个 LP
- 同时从 HA 主节点复制 tail log
SingleStore 的云原生 HTAP
SingleStore 系统架构
SingleStore 将 HTAP 和云原生很好的结合在一起。下图左边是 SingleStore 的整体架构图,其中包括两种节点:aggregators 节点和负责计算的 leaf 节点,两个 workspace:主 workspace 和只读 workspace,以及对象存储(云存储):其中包含数据文件、logs、快照文件。
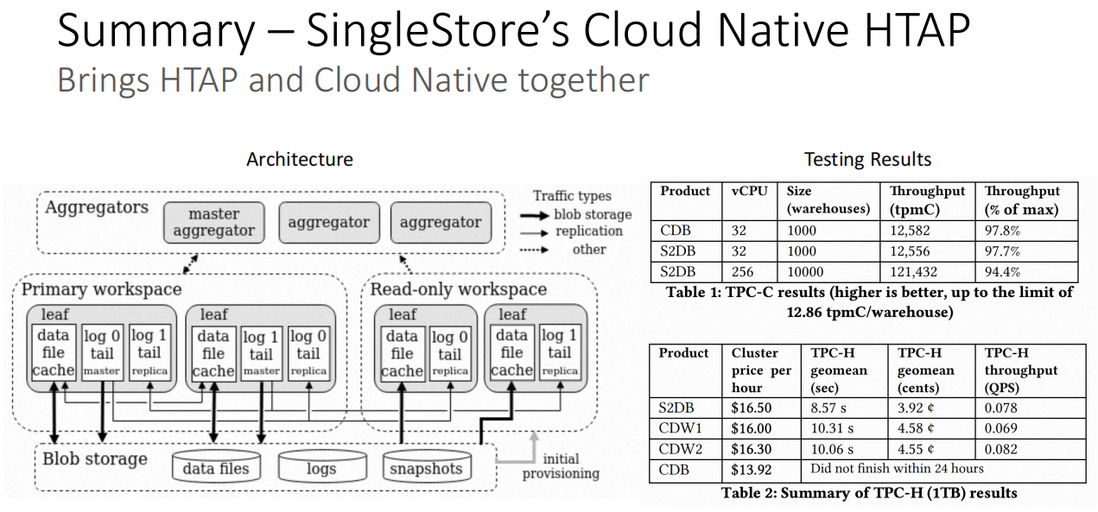
测试数据分析
在上图右边是两个测试数据表:
- 表 1:TPC-C 测试结果;
- 表 2:TPC-H 测试结果;
- S2DB:SingleStore;
- CDB(Cloud Database):云 TP 数据库;
- CDW(Cloud Data Warehouse):云 AP 数仓;
从两个测试结果可以看到,对比同类产品,SingleStore 数据库,在扩展能力和综合处理能力方面有不错的表现。
参考链接:


