Spark简介 ApacheSpark是一个开源的分布式计算框架,专为大规模数据处理而设计。它提供了丰富的工具和库,支持多种数据处理任务,包括批处理、流处理、机器学习和图计算。Spark以其速度、易用性和通用性而闻名,广…

Apache Storm简介 Apache Storm是一个开源的、分布式的实时计算系统,旨在处理和分析大规模的数据流。它可以持续地接收数据,并在收到数据后立即进行处理,适用于需要低延迟的数据处理场景,如实时数据分析、在线机…
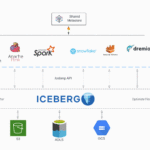
Apache Iceberg 简介 Apache Iceberg 是一种用于庞大分析数据集的开放表格式。它的设计目标是解决传统数据湖存储格式(如 Hive)在管理大规模数据时遇到的关键问题,提供可靠的数据存储和管理功能。 基本定…
Hudi简介 Apache Hudi(Hadoop Upserts and Incrementals)是一个开源的数据湖存储框架,旨在支持高效的数据更新、删除和增量处理。Hudi通过提供数据湖存储的事务能力,简化了数据的管理和查询,使其成为构建实时数…

Redpanda简介 Redpanda是一种现代流处理平台,旨在提供高性能、低延迟的消息流处理能力。它是一个Kafka API兼容的流处理引擎,专为云原生环境设计,提供了许多改进的特性和功能。 基础特性 兼容性:Redpanda与…

Flink简介 Apache Flink是一个开源的流处理框架,旨在提供高性能、低延迟的实时数据流处理能力,同时支持批处理任务。Flink以其强大的流处理能力、灵活的API和丰富的生态系统而广受欢迎。 Flink核心特性 处理无界…

Kudu简介 Apache Kudu是一个开源的列式存储引擎,专为快速分析和随机访问而设计,适用于大数据工作负载。它填补了Hadoop生态系统中对需要快速分析和低延迟更新的应用程序的需求。 核心特性 列式存储:Kudu采用…

Hbase简介 产生背景 Apache HBase的产生背景可以追溯到对大规模数据存储和处理需求的迅速增长,尤其是在互联网公司和其他需要处理海量数据的行业中。 大数据需求的增长:随着互联网的快速发展,尤其是社交媒体…

Airflow简介 Apache Airflow是一个用于编排和调度复杂工作流的开源平台,广泛应用于数据工程和数据科学领域。它提供了一种灵活的方式来定义、调度和监控数据管道。 Airflow是一个编排、调度和监控 workflow 的平台…
Apache NiFi 简介 Apache NiFi 是一个强大的数据流管理和自动化工具,旨在简化数据的采集、传输、处理和分发。它特别适合于构建和管理复杂的数据流管道,支持从各种数据源到不同目标系统的数据传输。 Apache NiFi…