大数据印象
当别人谈论“大数据”时,你的感觉是?
状态1:不明觉厉
突如其来起来的名词可能把你搞蒙,如分布式、云存储、云计算、数据仓库、数据挖掘你能说清楚到底是什么吗?这时候的认知可能是高深莫测,高端、大气、上档次!

状态2:人艰不拆
通常出现这种状态是在接触“大数据”以后,或因数据量过于庞杂不知如何处理,或因投入后未能发现实际价值而倍感挫折。

大数据之歧路
IBM提出的“5V”模型是理解大数据的经典框架:
- Volume(数量):数据规模巨大。
- Variety(多样性):数据类型和来源多样。
- Value(价值):数据中蕴藏价值,但密度相对较低,需要挖掘。
- Velocity(速度):数据产生和处理速度快。
- Veracity(真实性):数据的准确性和可信度。
现实世界的问题:
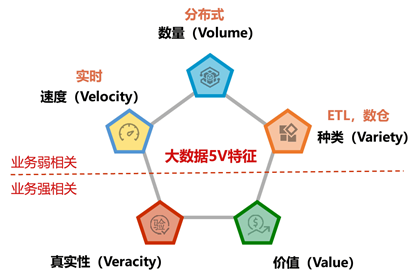
然而,许多数据团队的误区在于过分关注“速度”、“数量”和“多样性”,而忽视了“真实性”和“价值”。前三者相对容易量化和实现,有大量开源项目可供参考;

而后两者则需要深入理解业务,且“真实性”校验耗时费力,“价值”挖掘的成功率难以保证。此外,组织架构的割裂(懂数据的不懂业务,懂业务的不懂数据)以及技术的快速迭代也分散了人们的注意力,导致本末倒置。
数据越大越好?
人们常常用“日处理数据量”、“总存储量”、“集群节点数”等指标来衡量大数据的价值。然而,如果数据得不到有效利用,这些数字仅仅是“资产负债”,而非真正的价值。

盲目追求数据量是常见的误区。收集数据容易,但剔除噪音、提取关键信息却充满挑战。未经有效处理的数据反而会增加工作量,降低效率。掌握数据并不等同于理解世界运行的规律。我们需要通过统计推断等方法,将数据简化并转化为易于理解和建模的形式,从而揭示数据背后的规律。
小数据的价值
与大数据相比,小数据在某些方面具有独特的优势:
- 信息密度高:小数据通常是针对特定问题精心挑选的,包含更多有效信息。
- 针对性强:小数据更专注于解决具体问题,例如通过用户访谈深入了解用户体验。
- 可解释性强:小数据更易于人工分析和理解,结论更具可解释性。
- 获取和处理成本低:小数据的获取和处理成本相对较低。
因此,小数据并非价值低下,关键在于根据具体问题选择合适的数据类型和分析方法。
统计推断与数据量
传统统计学强调总体和样本的概念,通过分析样本来推断总体。在大数据时代,我们似乎可以获取所有数据(N=全部),但这是一种误解。即使分析网站流量,我们也只能获取访问过网站的用户数据,而无法了解未访问用户的行为。

此外,“n=1”(只观察一个个体就得出总体结论)也是不可取的。
“大数据”的概念常常让人望而却步,甚至放弃接触真实数据的念头。PC时代,我们通过数据洞悉用户需求;
而大数据时代,我们却常常沉溺于各种报表,反而失去了对数据本身的理解。
报表的危机

报表虽然是常见的数据呈现方式,但也存在诸多问题:
- 需求泛滥且紧急。
- 报表之间缺乏逻辑关联。
- 数据加工缺乏设计。
- 长期使用率低,造成重复开发和浪费。
- 信息展示有限,细节容易被掩盖。
- 开发往往基于易实现性而非实际价值。
因此,我们需要警惕对报表的过度依赖。
我们应该分析多大的数据?
“大”是相对的。当数据的规模对现有技术构成挑战时,才能称之为“大”。因此,“大数据”的定义是动态变化的。当单机无法处理时,就需要采用新的工具和方法,这时就可以称为“大数据”。

报表危机:
- 报表需求铺天盖地
- 每次业务都很紧急
- 报表之间缺少逻辑
- 数据加工缺少设计
- 时间久了很少用起
- 重复开发成为垃圾
- 用和不用放在那里
- 增加成本没有意义
与其纠结于数据量的大小,不如关注如何有效地利用数据。Excel可以处理的数据可以称为小数据,百万级以下的数据通常可以使用单机进行分析。

日常分析中,数据量应大于“(数值型特征数量+类别型特征的类别数)*10”,且小于100万,并采用合适的抽样方法(如随机抽样、等距抽样、分层抽样)进行数据提取。
质量和相关性至上
“垃圾进,垃圾出”是数据分析的基本原则。与其追求数据量,不如关注数据的质量和相关性。高质量的数据能够降低噪音干扰、更易于理解和解释,并节约资源和成本。
数据大小不是真正的问题
硬件的进步使得处理大部分数据成为可能。许多企业的数据量远没有想象中那么大。与其担心数据量,不如关注如何有效地使用数据,并选择合适的工具。数据本身也是一种负债,保留数据需要承担成本和风险。
“让数据说话”的误区
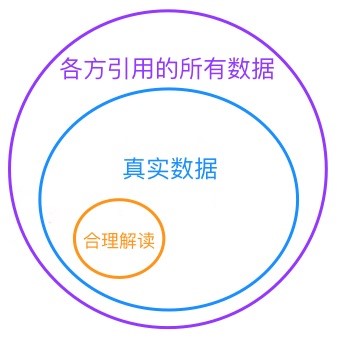
“让数据说话”的说法常常被误用。数据本身不会说话,它只是客观的记录。会说话的是人,数据分析需要人的解读和判断。数据可能被误用或曲解,因此,数据的验证至关重要。
你需要认知到的是:忽视因果关系是大数据法则的一种缺陷,而不是特征。忽视因果关系的模型无助于解决现存问题,而只会增加更多问题。数据也不会自己说话,它只能够以一种量化的、无力的方式去描述、再现我们身边的事件。
- 数据不会说话,会说话的是人。
- 数据不会撒谎,会撒谎的是人。
- 真数据未必代表着真相,假数据一定意味着谎言。
- 数据可以生产结论,结论同样可以生产数据。
- 当一个数据无法验证的时候,它毫无用处。
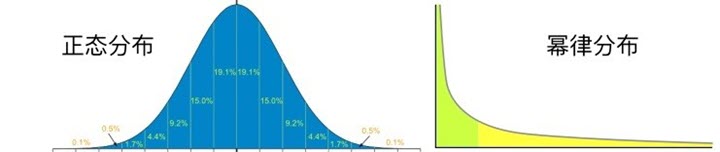
幂律分布的数据在很多地方都会误导人。
大数据是泡沫吗?
关于大数据是否是泡沫的争论由来已久。
- 正方观点:概念炒作、应用落地困难、技术门槛高、数据质量问题、安全和隐私风险等。
- 反方观点:数据驱动决策、提高效率和降低成本、创新产品和服务、科学研究的重要工具等。
与其说大数据是泡沫,不如说对大数据的理解和应用存在泡沫。真正的大数据应用需要明确的业务目标、高质量的数据、强大的数据分析能力和有效的数据治理。
不要被“大数据”的概念所迷惑。我们需要理性看待大数据,关注数据的质量和应用,培养数据分析能力,才能真正发挥数据的价值。

关键问题:
- 我属于什么级别的玩家?
- 我是技术驱动、业务驱动还是数据驱动?
- 我是否清楚大数据应用的局限?
- 我是否准备好打一场大数据应用持久战?
- 我是否了解大数据风险与数据偏见?
- 我是否理解并能贯彻大数据思维?
参考链接:



楼主见的深刻,文笔精湛。道出了数据开发人的困扰,报表人的无奈。佩服三连~