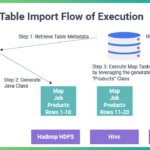
Sqoop简介 Sqoop(SQL-to-Hadoop)是一个开源工具,主要用于在Apache Hadoop和传统关系型数据库(如MySQL、PostgreSQL、Oracle、SQL Server等)之间高效传输大规模数据。它简化了数据从关系数据库到Hadoop分布式文…
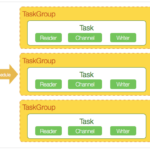
DataX简介 DataX是阿里巴巴开源的一款轻量级的数据同步工具,旨在解决异构数据源之间的数据传输问题。它支持多种数据源,包括关系型数据库、NoSQL数据库、Hadoop、FTP、消息队列等。DataX的设计目标是提供一个简单…
Paimon简介 Apache Paimon是一个面向大数据生态系统的高性能数据湖存储系统。它最初是由Flink社区开发的,旨在为大数据处理提供高效的存储解决方案。 Apache Paimon(以前称为Flink Table Store)是一个专为流处…
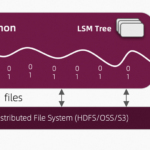
HDF5简介 HDF5(Hierarchical Data Format version 5)是一种用于存储和管理大规模数据的开放文件格式和软件库。它广泛应用于科学计算、工程、金融等领域,尤其适合存储复杂数据结构和需要高效读写操作的大型数据集…
Dask简介 Dask是一个用于并行计算的Python库,它旨在扩展Python的生态系统,使其能够处理大规模数据计算。Dask通过提供动态任务调度系统和大数据集合(如并行数组、数据帧等),帮助开发者在多核处理器或集群上有效…

Presto是什么? Presto是Facebook开源的MPP(Massive Parallel Processing)SQL引擎,其理念来源于一个叫Volcano的并行数据库,该数据库提出了一个并行执行SQL的模型,它被设计为用来专门进行高速、实时的数据分析…
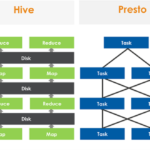
Hive简介 Hive由Facebook实现并开源,是基于Hadoop的一个数据仓库工具。可以将结构化的数据映射为一张数据库表并提供HQL(Hive SQL)查询功能。底层数据是存储在HDFS上,Hive的本质是将SQL语句转换为MapReduce任务运…

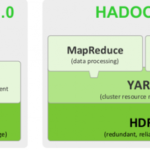
这篇一开始文章整理于2014年,在此的7~8年时间里,Hadoop已经发生了很多变化,但最为核心的内容并没有变化那么多,当时的文章还是有一定的参考意义。再次重新做下整理。 Hadoop的概要介绍 Hadoop,是一个分布式系统…
Google,作为全球最大的搜索引擎公司,其伟大之处不仅在于建立了一个强大的搜索引擎,还在于它创造了3项革命性的技术,即:GFS、MapReduce和BigTable。作为Google早期三驾马车,这三项革命性的技术不仅在大数据领域…

Bigtable是2005年谷歌的论文:《Bigtable: A Distributed Storage System for Structured Data》中介绍的一种分布式存储系统,后来被Hadoop社区实现为HBase。读懂这篇论文,那么理解HBase也就非常容易了。 摘要(…