HDF5简介
HDF5(Hierarchical Data Format version 5)是一种用于存储和管理大规模数据的开放文件格式和软件库。它广泛应用于科学计算、工程、金融等领域,尤其适合存储复杂数据结构和需要高效读写操作的大型数据集。HDF5由非营利组织HDF Group开发和维护。
HDF5的主要特点
- 层次结构:HDF5采用层次结构的方式组织数据,类似于文件系统。数据存储在文件中,文件中可以包含多个组(Groups),组内可以包含数据集(Datasets)和其他组。这种结构化的组织方式使得管理复杂的数据变得更加直观。
- 数据集和组:数据集是存储数据的基本单元,类似于多维数组。组用于组织数据集和其他组,类似于目录和子目录。
- 多种数据类型支持:HDF5支持多种数据类型,包括标量、矢量、矩阵、复数、字符串、图像等。这使得它非常适合存储多样化的数据。
- 数据压缩:HDF5支持数据压缩功能,提供多种压缩算法(如Zlib、SZIP)。这有助于减少存储空间,同时提高数据传输效率。
- 并行I/O支持:HDF5支持并行I/O操作,适合在高性能计算环境中使用,能够有效利用多处理器和分布式存储系统。
- 跨平台和可移植性:HDF5是一个跨平台的文件格式,支持在不同操作系统和硬件平台之间的数据交换。
- 元数据和属性:HDF5允许为数据集和组添加属性(Attributes),用于存储元数据。这使得用户可以记录关于数据的重要信息,如单位、描述、创建时间等。
应用领域
- 科学计算:HDF5广泛应用于气象、地球物理、天文学、生物信息学等领域,用于存储和管理大规模科学数据。
- 工程和仿真:在工程仿真和建模中,HDF5被用来存储复杂的模拟结果和输入数据。
- 金融和商业分析:用于存储和分析大量的市场数据和交易记录。
- 图像和视频处理:HDF5可以用于存储和管理大型图像和视频数据集,支持高效的随机访问。
HDF5文件结构
HDF5文件结构是一个分层的、灵活的数据存储模型,类似于文件系统。这种结构使得HDF5能够高效地存储和组织复杂的数据集。HDF5文件的基本组成部分包括文件、组(Groups)、数据集(Datasets)和属性(Attributes)。
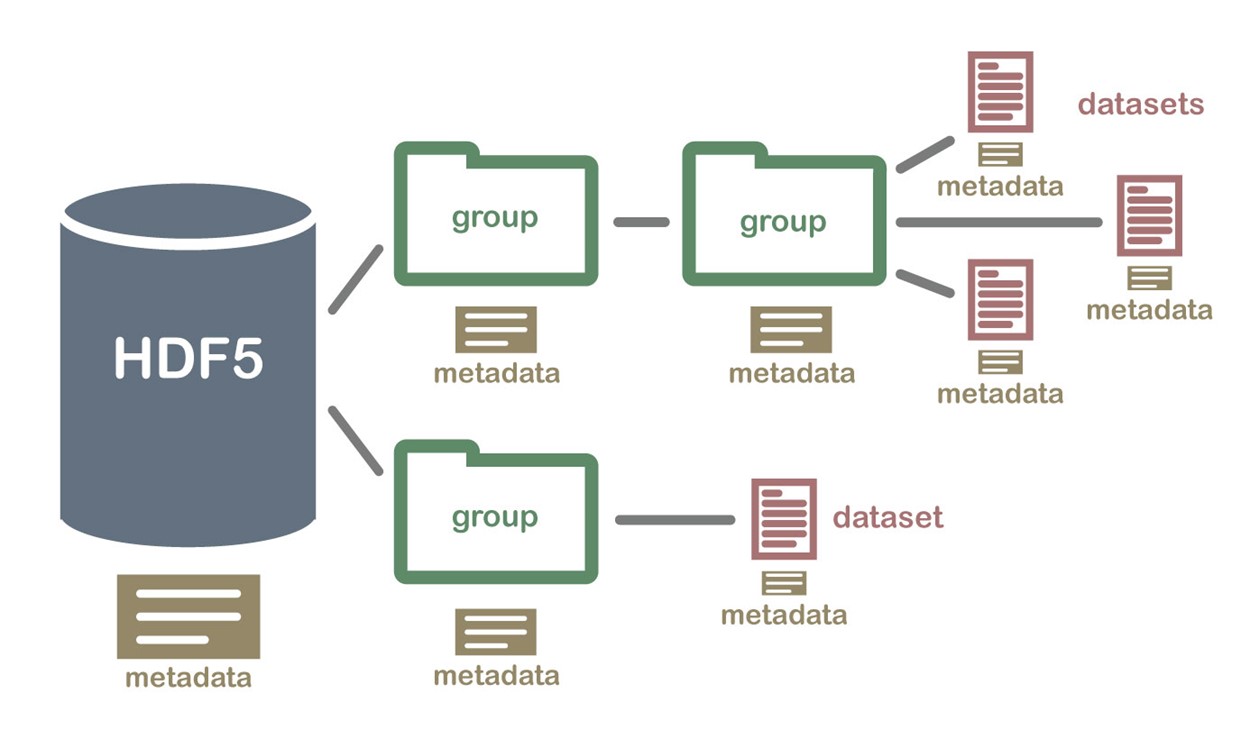
HDF5文件的基本组成
- 文件(File):HDF5文件是数据存储的容器。每个HDF5文件可以包含多个组和数据集。文件的创建、打开、关闭等操作由HDF5库提供的API进行管理。
- 组(Groups):组是HDF5文件中的容器对象,用于组织数据集和其他组。组可以嵌套,形成类似于文件系统目录结构的层次结构。每个组都有一个名称,并可以包含任意数量的子组和数据集。
- 根组(Root Group):每个HDF5文件都有一个默认的根组,路径为’/’,所有其他组和数据集都是从根组开始的。
- 数据集(Datasets):数据集是HDF5文件中的数据存储单元,类似于多维数组。每个数据集具有唯一的名称、数据类型(如整数、浮点数等)和数据空间(即数据的维度和大小)。数据集可以存储任意维度的数据,并支持多种数据类型。
- 属性(Attributes):属性是附加在组或数据集上的元数据,用于存储关于数据的额外信息(如单位、描述、版本等)。属性类似于键值对,键是属性名称,值是属性内容。属性可以是标量或数组,支持多种数据类型。
HDF5文件结构的特点
- 层次结构:HDF5的层次结构允许用户以直观的方式组织和管理数据。通过这种结构,用户可以轻松地在文件中找到和访问特定的数据集。
- 可扩展性:HDF5文件的结构是动态的,用户可以在文件创建后随时添加新的组和数据集。数据集的大小也可以根据需要进行扩展。
- 跨平台:HDF5文件格式是跨平台的,支持在不同操作系统和硬件平台之间的数据交换。
- 高效存储:HDF5提供了多种压缩选项和数据存储布局,支持高效的数据存储和检索。
示例结构
假设我们有一个HDF5文件example.h5,其结构可能如下:
/(Root Group) /experiment_1 (Group) /data (Dataset) /results (Dataset) /metadata (Group) /experiment_date (Attribute) /experimenter (Attribute) /experiment_2 (Group) /data (Dataset) /results (Dataset)
在这个例子中:
- 根组/ 包含两个子组 experiment_1 和 experiment_2。
- 每个实验组包含一个data 数据集和一个 results 数据集。
- experiment_1组还包含一个 metadata 子组,其中存储了一些实验的元数据属性。
HDF5的使用
HDF5的软件支持
- 库和工具:HDF5提供了一系列的API和工具,用于创建、读写和管理HDF5文件。支持多种编程语言,包括C、C++、Fortran、Python、Java等。
- Python支持:在Python中,h5py和 PyTables 是两个流行的库,提供了对HDF5文件的访问和操作功能。
基本用法示例(使用h5py)
以下是一个使用h5py库创建和读取HDF5文件的简单示例:
import h5py
import numpy as np
# 创建一个HDF5文件
with h5py.File('example.h5', 'w') as file:
# 创建组和子组
exp1 = file.create_group('experiment_1')
exp2 = file.create_group('experiment_2')
# 创建数据集
data1 = exp1.create_dataset('data', data=np.random.random((100, 100)))
results1 = exp1.create_dataset('results', data=np.random.random((10,)))
data2 = exp2.create_dataset('data', data=np.random.random((200, 200)))
results2 = exp2.create_dataset('results', data=np.random.random((20,)))
# 添加属性
exp1.attrs['experiment_date'] = '2023-10-01'
exp1.attrs['experimenter'] = 'Dr. Smith'
# 读取HDF5文件
with h5py.File('example.h5', 'r') as file:
# 列出根组中的所有对象
print(list(file.keys()))
# 访问特定数据集和属性
data = file['experiment_1/data'][:]
print(data.shape)
experiment_date = file['experiment_1'].attrs['experiment_date']
print(experiment_date)
注意事项
- 文件大小:虽然HDF5提供了压缩功能,但在创建和管理非常大的文件时,仍需考虑存储和内存资源。
- 并发访问:HDF5的并发访问需要小心管理,尤其是在多进程或多线程环境中,建议使用并行HDF5功能。
- 数据格式兼容性:在不同软件版本之间移动HDF5文件时,可能需要注意数据格式的兼容性。
h5py的使用
h5py是Python中用于操作HDF5文件格式的库。HDF5(Hierarchical Data Format Version 5)是一种高效存储和管理大规模科学数据的文件格式,支持:
- 层次化结构(类似文件系统的目录树)
- 多维数组(数据集)
- 元数据(属性)
- 压缩、分块存储、并行I/O等高级特性。
h5py通过Pythonic的接口将HDF5的功能与NumPy无缝集成,特别适合处理数值型数据和复杂数据结构。
h5py与HDF5的关系
- 底层实现:h5py是对HDF5 C库的Python封装,保留了HDF5的高性能特性。
- Pythonic设计:将HDF5的复杂操作简化为类似字典和NumPy数组的接口。
- 跨平台兼容:生成的HDF5文件可被其他语言(C/C++、MATLAB、Julia)直接读取。
h5py的核心对象
文件(h5py.File)
HDF5文件的入口点,支持读写模式(r、w、a、r+)。
示例:
with h5py.File("data.h5", "w") as f:
pass # 操作文件
组(h5py.Group)
类似文件夹的容器,用于组织数据集的层次结构。
示例:
group = f.create_group("/experiment1/sensors")
数据集(h5py.Dataset)
存储实际数据的多维数组,支持多种数据类型(整数、浮点、字符串、复合类型等)。
示例:
data = np.random.rand(100, 100)
dset = f.create_dataset("dataset1", data=data)
属性(Attributes)
附加到组或数据集的键值对元数据。
示例:
dset.attrs["unit"] = "meters"
基础操作
创建/打开文件
import h5py
# 创建新文件(覆盖已存在文件)
with h5py.File("data.hdf5", "w") as f:
pass
# 打开文件(只读)
with h5py.File("data.hdf5", "r") as f:
pass
# 追加模式(可读写,不覆盖)
with h5py.File("data.hdf5", "a") as f:
pass
创建组(Group)
with h5py.File("data.hdf5", "w") as f:
# 创建根组下的子组
group = f.create_group("group1/subgroup")
创建数据集(Dataset)
import numpy as np
data = np.random.rand(100, 100)
with h5py.File("data.hdf5", "w") as f:
# 创建数据集(自动推断数据类型和形状)
dset = f.create_dataset("dataset1", data=data)
# 指定数据类型和形状
dset2 = f.create_dataset("dataset2", shape=(50, 50), dtype=np.float32)
dset2[:] = np.random.rand(50, 50).astype(np.float32) # 填充数据
属性管理(Attributes)
with h5py.File("data.hdf5", "a") as f:
dset = f["dataset1"]
# 添加属性
dset.attrs["description"] = "Random data"
dset.attrs["unit"] = "meters"
# 读取属性
print(dset.attrs["description"]) # 输出: Random data
# 删除属性
del dset.attrs["unit"]
数据集操作
读写数据
with h5py.File("data.hdf5", "a") as f:
dset = f["dataset1"]
# 写入部分数据
dset[0:10, 0:10] = np.zeros((10, 10))
# 读取数据
subset = dset[5:15, 5:15]
print(subset.shape) # 输出: (10, 10)
压缩与分块存储
with h5py.File("data.hdf5", "w") as f:
# 启用压缩(gzip)和分块存储
dset = f.create_dataset(
"compressed_data",
shape=(1000, 1000),
dtype=np.float32,
chunks=(100, 100), # 分块大小
compression="gzip", # 压缩算法(可选"lzf"更快但压缩率低)
compression_opts=9 # 压缩级别(0-9)
)
dset[:] = np.random.rand(1000, 1000)
高级功能
数据类型支持
基础类型:整型、浮点型、布尔型、字符串。
复杂类型:
复合类型(类似结构化数组):
# 创建复合数据类型(类似结构化数组)
dt = np.dtype([("name", "S10"), ("value", np.float64)])
data = np.array([("Alice", 3.14), ("Bob", 6.28)], dtype=dt)
with h5py.File("structured.hdf5", "w") as f:
dset = f.create_dataset("structured_data", data=data)
# 读取复合数据
with h5py.File("structured.hdf5", "r") as f:
print(f["structured_data"][0]["name"]) # 输出: b'Alice'
可变长度数据(VLEN):
dt = h5py.vlen_dtype(np.int32)
dset = f.create_dataset("vlen_data", (5,), dtype=dt)
dset[0] = [1, 2, 3] # 每个元素可以是不同长度的数组
数据存储优化
分块存储(Chunking):
将数据集分割为固定大小的块,支持快速部分读写和压缩。
示例:
dset = f.create_dataset("chunked", shape=(1000, 1000), chunks=(100, 100))
压缩(Compression):
支持 gzip、lzf、szip 等算法。
示例:
dset = f.create_dataset("compressed", data=data, compression="gzip", compression_opts=9)
内存映射(Memory Mapping):
直接访问磁盘数据,避免加载整个数据集到内存。
示例:
dset = f["large_dataset"]
subset = dset[1000:2000, :] # 仅读取指定部分到内存
可扩展数据集(Resizable Datasets)
动态调整数据集大小,适合流式数据或增量更新。
示例:
with h5py.File("resizeable.hdf5", "w") as f:
# 创建可扩展数据集(maxshape设置为None表示无限扩展)
dset = f.create_dataset("dynamic_data", shape=(10,), maxshape=(None,), dtype=np.int32)
dset[:] = np.arange(10)
# 扩展数据集
dset.resize((20,))
dset[10:20] = np.arange(10, 20)
并行HDF5(Parallel I/O)
使用MPI实现多进程同时读写同一文件(需安装 h5py 的并行版本)。
示例:
from mpi4py import MPI
comm = MPI.COMM_WORLD
f = h5py.File("parallel.h5", "w", driver="mpio", comm=comm)
过滤器(Filters)
自定义预处理数据(如加密、校验和)。
示例:注册自定义过滤器(需实现C语言插件)。
引用与软链接
对象引用:跨组引用数据集或组。
软链接:类似符号链接,指向其他路径。
示例:
f["link_to_data"] = h5py.SoftLink("/group1/dataset1")
与NumPy的深度集成
零拷贝操作:数据集直接返回NumPy数组。
dset = f.create_dataset("numpy_data", data=np.arange(100))
array = dset[:] # 直接转换为NumPy数组
广播规则:支持NumPy风格的切片和索引。
dset[0:10, :] = np.zeros((10, dset.shape[1]))
实际应用场景
保存和读取NumPy数组
# 保存多个数组到同一文件
with h5py.File("arrays.hdf5", "w") as f:
f.create_dataset("array1", data=np.random.rand(100))
f.create_dataset("array2", data=np.random.rand(200, 200))
# 读取数组
with h5py.File("arrays.hdf5", "r") as f:
array1 = f["array1"][:]
array2 = f["array2"][:]
保存模型参数
model_params = {
"weights": np.random.rand(256, 128),
"bias": np.random.rand(128),
"learning_rate": 0.001
}
with h5py.File("model.hdf5", "w") as f:
for key, value in model_params.items():
if isinstance(value, np.ndarray):
f.create_dataset(key, data=value)
else:
f.attrs[key] = value
科学数据存储
存储实验数据(如传感器数据、3D模型、时间序列)。
示例:保存多通道传感器数据:
with h5py.File("sensor_data.h5", "w") as f:
for channel in ["temperature", "pressure"]:
data = np.random.rand(1000)
f.create_dataset(f"sensors/{channel}", data=data)
f["sensors"].attrs["sampling_rate"] = 1000 # Hz
机器学习模型参数
保存模型权重、超参数和训练元数据。
示例:
model = {
"weights": np.random.rand(256, 128),
"bias": np.random.rand(128),
"learning_rate": 0.001
}
with h5py.File("model.h5", "w") as f:
for key, value in model.items():
if isinstance(value, np.ndarray):
f.create_dataset(key, data=value)
else:
f.attrs[key] = value
大规模数据处理
分块处理TB级数据(如天文图像、基因组数据)。
示例:逐块处理大型数据集:
with h5py.File("big_data.h5", "r") as f:
dset = f["images"]
for i in range(0, dset.shape[0], 100):
chunk = dset[i:i+100, :, :] # 每次读取100张图像
process(chunk)
性能优化技巧
分块大小选择
原则:根据访问模式调整 chunks,例如:
- 按行访问:chunks=(1, N)
- 按列访问:chunks=(M, 1)
- 随机访问小块数据:较小的分块(如1KB-1MB)。
压缩与速度权衡
- gzip:高压缩率但较慢。
- lzf:快速压缩但压缩率低。
- 建议:对冷数据(不频繁访问)启用压缩。
避免频繁文件操作
- 尽量使用 with 语句集中读写,减少文件打开/关闭次数。
常见问题
文件占用无法删除
- 原因:文件未正确关闭。
- 解决:始终使用 with 语句或手动调用 close()。
字符串类型报错
dt = h5py.string_dtype(encoding="utf-8")
dset = f.create_dataset("text", data=["你好", "世界"], dtype=dt)
内存不足
解决:
- 使用分块存储或 File 的 libver="latest" 参数启用更高效的内存管理。
- 用分块存储(chunks=True)或逐块读写数据。
参考链接:
- HDF5快速上手全攻略-CSDN博客
- 官方文档:h5py Documentation
- HDF5教程:HDF5 for Python
h5py是Python中用于操作HDF5文件格式的库。HDF5(Hierarchical Data Format Version 5)是一种高效存储和管理大规模科学数据的文件格式,支持:
- 层次化结构(类似文件系统的目录树)
- 多维数组(数据集)
- 元数据(属性)
- 压缩、分块存储、并行I/O等高级特性。
h5py通过Pythonic的接口将HDF5的功能与NumPy无缝集成,特别适合处理数值型数据和复杂数据结构。
h5py与HDF5的关系
- 底层实现:h5py是对HDF5 C库的Python封装,保留了HDF5的高性能特性。
- Pythonic设计:将HDF5的复杂操作简化为类似字典和NumPy数组的接口。
- 跨平台兼容:生成的HDF5文件可被其他语言(C/C++、MATLAB、Julia)直接读取。
h5py的核心对象
文件(h5py.File)
HDF5文件的入口点,支持读写模式(r、w、a、r+)。
示例:
with h5py.File("data.h5", "w") as f:
pass # 操作文件
组(h5py.Group)
类似文件夹的容器,用于组织数据集的层次结构。
示例:
group = f.create_group("/experiment1/sensors")
数据集(h5py.Dataset)
存储实际数据的多维数组,支持多种数据类型(整数、浮点、字符串、复合类型等)。
示例:
data = np.random.rand(100, 100)
dset = f.create_dataset("dataset1", data=data)
属性(Attributes)
附加到组或数据集的键值对元数据。
示例:
dset.attrs["unit"] = "meters"
基础操作
创建/打开文件
import h5py
# 创建新文件(覆盖已存在文件)
with h5py.File("data.hdf5", "w") as f:
pass
# 打开文件(只读)
with h5py.File("data.hdf5", "r") as f:
pass
# 追加模式(可读写,不覆盖)
with h5py.File("data.hdf5", "a") as f:
pass
创建组(Group)
with h5py.File("data.hdf5", "w") as f:
# 创建根组下的子组
group = f.create_group("group1/subgroup")
创建数据集(Dataset)
import numpy as np
data = np.random.rand(100, 100)
with h5py.File("data.hdf5", "w") as f:
# 创建数据集(自动推断数据类型和形状)
dset = f.create_dataset("dataset1", data=data)
# 指定数据类型和形状
dset2 = f.create_dataset("dataset2", shape=(50, 50), dtype=np.float32)
dset2[:] = np.random.rand(50, 50).astype(np.float32) # 填充数据
属性管理(Attributes)
with h5py.File("data.hdf5", "a") as f:
dset = f["dataset1"]
# 添加属性
dset.attrs["description"] = "Random data"
dset.attrs["unit"] = "meters"
# 读取属性
print(dset.attrs["description"]) # 输出: Random data
# 删除属性
del dset.attrs["unit"]
数据集操作
读写数据
with h5py.File("data.hdf5", "a") as f:
dset = f["dataset1"]
# 写入部分数据
dset[0:10, 0:10] = np.zeros((10, 10))
# 读取数据
subset = dset[5:15, 5:15]
print(subset.shape) # 输出: (10, 10)
压缩与分块存储
with h5py.File("data.hdf5", "w") as f:
# 启用压缩(gzip)和分块存储
dset = f.create_dataset(
"compressed_data",
shape=(1000, 1000),
dtype=np.float32,
chunks=(100, 100), # 分块大小
compression="gzip", # 压缩算法(可选"lzf"更快但压缩率低)
compression_opts=9 # 压缩级别(0-9)
)
dset[:] = np.random.rand(1000, 1000)
高级功能
数据类型支持
基础类型:整型、浮点型、布尔型、字符串。
复杂类型:
复合类型(类似结构化数组):
# 创建复合数据类型(类似结构化数组)
dt = np.dtype([("name", "S10"), ("value", np.float64)])
data = np.array([("Alice", 3.14), ("Bob", 6.28)], dtype=dt)
with h5py.File("structured.hdf5", "w") as f:
dset = f.create_dataset("structured_data", data=data)
# 读取复合数据
with h5py.File("structured.hdf5", "r") as f:
print(f["structured_data"][0]["name"]) # 输出: b'Alice'
可变长度数据(VLEN):
dt = h5py.vlen_dtype(np.int32)
dset = f.create_dataset("vlen_data", (5,), dtype=dt)
dset[0] = [1, 2, 3] # 每个元素可以是不同长度的数组
数据存储优化
分块存储(Chunking):
将数据集分割为固定大小的块,支持快速部分读写和压缩。
示例:
dset = f.create_dataset("chunked", shape=(1000, 1000), chunks=(100, 100))压缩(Compression):
支持 gzip、lzf、szip 等算法。
示例:
dset = f.create_dataset("compressed", data=data, compression="gzip", compression_opts=9)内存映射(Memory Mapping):
直接访问磁盘数据,避免加载整个数据集到内存。
示例:
dset = f["large_dataset"] subset = dset[1000:2000, :] # 仅读取指定部分到内存可扩展数据集(Resizable Datasets)
动态调整数据集大小,适合流式数据或增量更新。
示例:
with h5py.File("resizeable.hdf5", "w") as f: # 创建可扩展数据集(maxshape设置为None表示无限扩展) dset = f.create_dataset("dynamic_data", shape=(10,), maxshape=(None,), dtype=np.int32) dset[:] = np.arange(10) # 扩展数据集 dset.resize((20,)) dset[10:20] = np.arange(10, 20)并行HDF5(Parallel I/O)
使用MPI实现多进程同时读写同一文件(需安装 h5py 的并行版本)。
示例:
from mpi4py import MPI comm = MPI.COMM_WORLD f = h5py.File("parallel.h5", "w", driver="mpio", comm=comm)过滤器(Filters)
自定义预处理数据(如加密、校验和)。
示例:注册自定义过滤器(需实现C语言插件)。
引用与软链接
对象引用:跨组引用数据集或组。
软链接:类似符号链接,指向其他路径。
示例:
f["link_to_data"] = h5py.SoftLink("/group1/dataset1")与NumPy的深度集成
零拷贝操作:数据集直接返回NumPy数组。
dset = f.create_dataset("numpy_data", data=np.arange(100)) array = dset[:] # 直接转换为NumPy数组广播规则:支持NumPy风格的切片和索引。
dset[0:10, :] = np.zeros((10, dset.shape[1]))实际应用场景
保存和读取NumPy数组
# 保存多个数组到同一文件 with h5py.File("arrays.hdf5", "w") as f: f.create_dataset("array1", data=np.random.rand(100)) f.create_dataset("array2", data=np.random.rand(200, 200)) # 读取数组 with h5py.File("arrays.hdf5", "r") as f: array1 = f["array1"][:] array2 = f["array2"][:]保存模型参数
model_params = { "weights": np.random.rand(256, 128), "bias": np.random.rand(128), "learning_rate": 0.001 } with h5py.File("model.hdf5", "w") as f: for key, value in model_params.items(): if isinstance(value, np.ndarray): f.create_dataset(key, data=value) else: f.attrs[key] = value科学数据存储
存储实验数据(如传感器数据、3D模型、时间序列)。
示例:保存多通道传感器数据:
with h5py.File("sensor_data.h5", "w") as f: for channel in ["temperature", "pressure"]: data = np.random.rand(1000) f.create_dataset(f"sensors/{channel}", data=data) f["sensors"].attrs["sampling_rate"] = 1000 # Hz机器学习模型参数
保存模型权重、超参数和训练元数据。
示例:
model = { "weights": np.random.rand(256, 128), "bias": np.random.rand(128), "learning_rate": 0.001 } with h5py.File("model.h5", "w") as f: for key, value in model.items(): if isinstance(value, np.ndarray): f.create_dataset(key, data=value) else: f.attrs[key] = value大规模数据处理
分块处理TB级数据(如天文图像、基因组数据)。
示例:逐块处理大型数据集:
with h5py.File("big_data.h5", "r") as f: dset = f["images"] for i in range(0, dset.shape[0], 100): chunk = dset[i:i+100, :, :] # 每次读取100张图像 process(chunk)性能优化技巧
分块大小选择
原则:根据访问模式调整 chunks,例如:
- 按行访问:chunks=(1, N)
- 按列访问:chunks=(M, 1)
- 随机访问小块数据:较小的分块(如1KB-1MB)。
压缩与速度权衡
- gzip:高压缩率但较慢。
- lzf:快速压缩但压缩率低。
- 建议:对冷数据(不频繁访问)启用压缩。
避免频繁文件操作
- 尽量使用 with 语句集中读写,减少文件打开/关闭次数。
常见问题
文件占用无法删除
- 原因:文件未正确关闭。
- 解决:始终使用 with 语句或手动调用 close()。
字符串类型报错
dt = h5py.string_dtype(encoding="utf-8")
dset = f.create_dataset("text", data=["你好", "世界"], dtype=dt)
内存不足
解决:
- 使用分块存储或 File 的 libver="latest" 参数启用更高效的内存管理。
- 用分块存储(chunks=True)或逐块读写数据。
参考链接:
- HDF5快速上手全攻略-CSDN博客
- 官方文档:h5py Documentation
- HDF5教程:HDF5 for Python


