EquivalenceClassTransformation (Eclat) 是频繁项挖掘和关联性分析的另外一种常用的算法,与 Apriori 和 FP-growth 不同的是,Eclat 采用垂直数据格式。所谓的垂直数据格式,就是从对原有数据进行倒排。 Apriori …
CatBoost是俄罗斯的搜索巨头Yandex在2017年开源的机器学习库,是Gradient Boosting(梯度提升)+Categorical Features(类别型特征),也是基于梯度提升决策树的机器学习框架。 CatBoost 简介 CatBoost这个名字来…
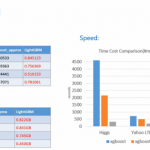
上一篇文章介绍了一个梯度提升决策树模型XGBoost,这篇文章我们继续学习一下GBDT模型的另一个进化版本:LightGBM。LigthGBM是boosting集合模型中的新进成员,由微软提供,它和XGBoost一样是对GBDT的高效实现,原理…
在上一篇Boosting方法的介绍中,对XGBoost有过简单的介绍。为了更还的掌握XGBoost这个工具。我们再来对它进行更加深入细致的学习。 什么是XGBoost? 全称:eXtreme Gradient Boosting 作者:陈天奇(华盛顿大学博…
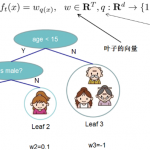
什么是K-近邻算法? K近邻法(k-nearest neighbor, k-NN)是1967年由Cover T和Hart P提出的一种基本分类与回归方法。它的工作原理是:存在一个样本数据集合,也称作为训练样本集,并且样本集中每个数据都存在标签,即…
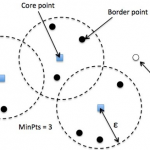
在前面介绍的DBSCAN算法中,有两个初始参数Eps(邻域半径)和minPts(Eps邻域最小点数)需要手动设置,并且聚类的结果对这两个参数的取值非常敏感,不同的取值将产生不同的聚类结果。为了克服DBSCAN算法这一缺点,提…
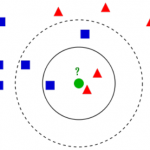
K-Means算法和MeanShift算法都是基于距离的聚类算法,基于距离的聚类算法的聚类结果是球状的簇,当数据集中的聚类结果是非球状结构时,基于距离的聚类算法的聚类效果并不好。 与基于距离的聚类算法不同的是,基…
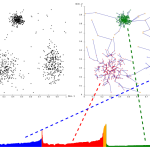
ISODATA算法(Iterative Self Organizing Data Analysis Techniques Algorithm,迭代自组织数据分析方法)和K-Means算法是相似的算法,都是属于无监督的聚类分析方法,但是 在之前介绍的K-Means算法中,有两大缺陷…
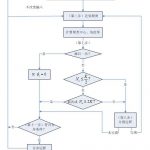
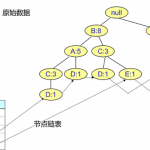
在Apriori算法的学习中,我们了解到Apriori算法需要不断生成候选项目队列和不断得扫描整个数据库进行比对,I/O是很大的瓶颈。为了解决这个问题,FP-Growth利用了巧妙的数据结构,无论多少数据,只需要扫描两次数据…
在前面的文章中介绍了基本的线性回归模型 属于全局的模型(除局部加权线性回归外),在线性回归模型中,其前提是假设全局的数据之间是线性的,通过拟合所有的样本点,训练得到最终的模型。然而现实中的很多问题是非…