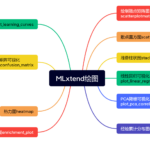
Mlxtend 简介 Mlxtend 是一个Python开源库,全称为 “machine learning extensions”(机器学习扩展)。由 Sebastian Raschka 创建并维护,其核心目标是提供一系列在日常数据科学和机器学习任务中非常实用的工具和扩…
在线旅游平台通过整合多个供应商的酒店资源,为用户提供一站式比价服务。酒店聚合能力直接影响用户体验:一方面需要确保信息准确,避免"到店无单"的风险;另一方面要保证信息的实时性,帮助用户快速决策。 业务挑…
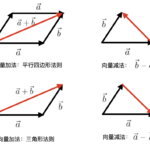
在线性代数中,向量和矩阵是重要的概念。向量是一种特殊的矩阵,矩阵也是一种特殊的向量。一个n维向量,可以写成nx1的矩阵,或者1xn的矩阵,分别叫做列向量与行向量。单个向量可以视为一阶矩阵,多个向量组合在一起…
Scikit-Opt 简介 scikit-opt 是一个封装了多种启发式算法的 Python 代码库,可以用于解决优化问题。虽然它的名字与著名的机器学习库 scikit-learn 相似,但两者并没有直接的隶属关系。 核心特点: 多算法支…
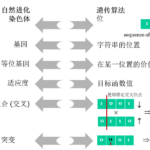
在机器学习或者人工智能领域,人们首先会考虑算法的学习方式。在机器学习领域,主要分为:监督学习,非监督学习,半监督学习和强化学习。监督学习主要用于回归和分类;半监督学习主要用于分类,回归,半监督聚类;无…
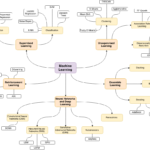
在机器学习数据预处理阶段经常需要对数据进行缺失值处理。关于缺失值的处理并没有想象中的那么简单。以下为一些经验分享。 数据缺失类型 完全随机丢失(MCAR,Missing Completely at Random):某个变量是否缺…
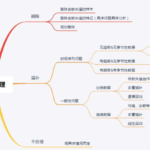
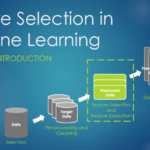
特征选择是特征工程里的一个重要问题,其目标是寻找最优特征子集。特征选择能剔除不相关(irrelevant)或冗余(redundant)的特征,从而达到减少特征个数,提高模型精确度,减少运行时间的目的。另一方面,选取出真正相…
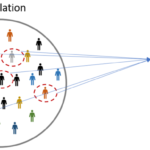
在分析数据或进行算法模型训练前有时需要先对数据进行抽样,这里整理了抽样的一些知识点。 什么情况下需要会用到抽样? 数据量太大,计算能力不足。 抽样调查,小部分数据即可反应全局情况。 时效要求,通过…
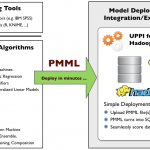
公司大部分应用的使用的是JAVA开发,要想使用Python模型非常困难,网上搜索了下,可以先将生成的模型转换为PMML文件后即可在JAVA中直接调用。 PMML简介 模型预测标记语言(Predictive Model Markup Language)是由…
NLTK简介 NLTK (Natural Language Toolkit)是由宾夕法尼亚大学计算机和信息科学使用 python 语言实现的一种自然语言工具包,其收集的大量公开数据集、模型上提供了全面、易用的接口,涵盖了分词、词性标注(Part-Of-…