公司大部分应用的使用的是JAVA开发,要想使用Python模型非常困难,网上搜索了下,可以先将生成的模型转换为PMML文件后即可在JAVA中直接调用。
PMML简介
模型预测标记语言(Predictive Model Markup Language)是由Dr. Robert Lee Grossman提出的一种基于XML的存储模型的格式标准。这里的模型是指那些由数据挖掘和机器学习算法生成的预测模型。PMML为不同的数据分析软件或者编程语言,提供了一种轻松共享预测分析模型的方式。它支持常见的模型,比如逻辑回归和前馈神经网络等。
PMML是一套与平台和环境无关的模型表示语言,是目前表示机器学习模型的实际标准。从2001年发布的PMML1.1,到2019年最新4.4,PMML标准已经由最初的6个模型扩展到了17个模型,并且提供了挖掘模型(MiningModel)来组合多模型。作为一个开放的成熟标准,PMML由数据挖掘组织DMG(Data Mining Group)开发和维护,经过十几年的发展,得到了广泛的应用,有超过30家厂商和开源项目(包括SAS,IBM SPSS,KNIME,RapidMiner等主流厂商)在它们的数据挖掘分析产品中支持并应用PMML。
PMML的作用
一个机器学习的上线过程,主要包括:分析、特征工程、模型训练、调优、上线。其中,PMML的便捷性,主要体现在模型上线的过程中。
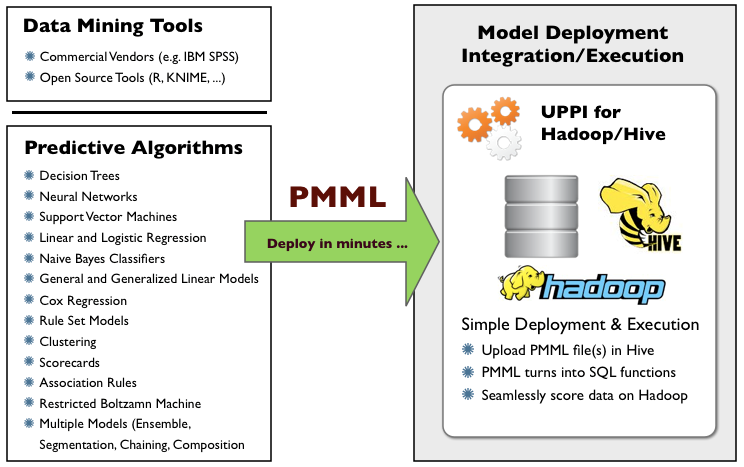
模型上线是将训练好的模型有效地应用于生产环境的过程。一般而言,生产环境和数据分析人员所使用的环境差距巨大。
例如,线上DMP是基于Hadoop的,计算框架用的Spark+MR。线下人员建模主要使用的是R、Python中的sklearn库以及部分使用keras。如果没有PMML,因为不同的系统采用不同的方式呈现其计算,模型上线时就必须经历一个漫长的、容易出现错误和误呈现的翻译过程。此外,还需要对模型结构了解非常深入的工程人员。比如,将R中的LR迁移至Java中,就需要工程人员根据训练好模型的参数,裸写一个JAVA类。
以最简单的LR为例,就是一个数据表示权重向量,权重向量和参数向量相乘之后求一次激活函数。但复杂一点的模型,就要求对模型结构了解非常深入的工程人员,严格按照模型的计算逻辑,来编写该类。
有了PMML,就可以从应用程序A到B再到C轻松共享模型,并且在训练完成之后,迅速将模型上线(只需替换模型文件即可)。现在的实践就是,线下分析人员,使用R等训练好一版的模型之后,导出为PMML,在线上只需替换该PMML文件即可。
PMML包含数据预处理和数据后处理(即模型预测结果的处理)和预测模型本身,见下图:
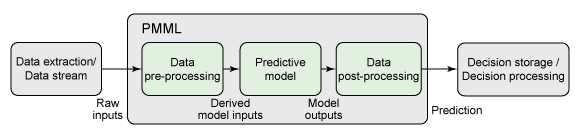
PMML文件的结构遵从了用于构建预测模型的常用步骤。
- 文头件:包含了PMML文档的基本信息,例如模型的版权信息,模型的描述,以及生成该文件所用软件的信息(比如软件的名字和版本)。头文件中也会包含该PMML文件的生成时间。
- 数据字典:包含了模型可能用到的所有字段名。并定义了字段的类型,可以是连续型(continuous)、类别型(categorical)、定序型(ordinal)。和字段值的类型,如String、Double。
- 数据挖掘模式:数据挖掘模式,可以看做是模型的一个看门人。所有进入模型的数据,必须经过数据挖掘模式。每个模型都包含且只包含一个数据挖掘模式,用于列出该模型使用的数据。数据挖掘模式包含针对特定模型不同的信息,相对的,数据字典中定义则是稳定的,不会随模型变化而变化。数据挖掘模式的主要目的是列出使用模型需要的数据。数据挖掘模式也定义了每个字段的使用用途(激活、追加、目标)以及针对空值、非法数据的策略。
- 数据转化:数据转化操作可以用于对进入模型之前的数据进行预处理。类比python sklearn中的DataFrameMapper,以及Spark中特征预处理相关算子。PMML定义了如下简单的数据转化操作:标准化、离散化、值映射、自定义函数、聚合
- 模型:包含了模型的定义和结构信息。
- 输出:定义了模型输出。对于一个分类任务来说,输出可以包括预测类及与所有可能类相关的概率。
- 目标:定义了应用于模型输出的后处理步骤。对于一个回归任务来说,此步骤支持将输出转变为人们很容易就可以理解的分数(预测结果)。
- 模型解释:定义了将测试数据传递至模型时获得的性能度量标准(与训练数据相对)。这些度量标准包括字段相关性、混淆矩阵、增益图及接收者操作特征(ROC)曲线图。
- 模型验证:定义了一个包含输入数据记录和预期模型输出的示例集。这是非常重要的一个步骤,因为在应用程序之间移动模型时,该模型需要通过匹配测试。这样就可以确保,在呈现相同的输入时,新系统可以生成与旧系统同样的输出。如果实际情况是这样的话,一个模型将被认为经过了验证,且随时可用于实践。
PMML的优点
- 平台无关性。PMML可以让模型部署环境脱离开发环境,实现跨平台部署,是PMML区别于其他模型部署方法最大的优点。比如使用Python建立的模型,导出PMML后可以部署在Java生产环境中。
- 互操作性。这就是标准协议的最大优势,实现了兼容PMML的预测程序可以读取其他应用导出的标准PMML模型。
- 广泛支持性。已取得30余家厂商和开源项目的支持,通过已有的多个开源库,很多重量级流行的开源数据挖掘模型都可以转换成PMML。
- 可读性。PMML模型是一个基于XML的文本文件,使用任意的文本编辑器就可以打开并查看文件内容,比二进制序列化文件更安全可靠。
PMML的缺点
- 支持不了所有的数据预处理和后处理操作。虽然PMML已经支持了几乎所有的标准数据处理方式,但是对用户一些自定义操作,还缺乏有效的支持,很难放到PMML中。
- 模型类型支持有限。特别是缺乏对深度学习模型的支持,PMML下一版0会添加对深度模型的支持,目前Nyoka可以支持Keras等深度模型,但生成的是扩展的PMML模型。
- PMML是一个松散的规范标准,有的厂商生成的PMML有可能不太符合标准定义的Schema,并且PMML规范允许厂商添加自己的扩展,这些都对使用这些模型造成了一定障碍。
PMML的使用
以LightGBM为例:
将生成的模型导出为txt格式
import pandas as pd
from lightgbm import LGBMClassifier
iris_df = pd.read_csv("xml/iris.csv")
d_x = iris_df.iloc[:,0:4].values
d_y = iris_df.iloc[:,4].values
model = LGBMClassifier(
boosting_type='gbdt', objective="multiclass", nthread=8, seed=42)
model.n_classes = 3
model.fit(d_x, d_y, feature_name=iris_df.columns.tolist()[0:-1])
model.booster_.save_model("xml/lightgbm.txt")
使用工具将txt模型转化为pmml格式
java -jar converter-executable-1.2-SNAPSHOT.jar --lgbm-input lightgbm.txt --pmml-output lightgbm.pmml
在JAVA代码中直接调用
备注,调用前需要引入如下架包:https://github.com/jpmml/jpmml-evaluator,示例代码:
package com.pmmldemo.test;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStream;
import java.util.HashMap;
import java.util.LinkedHashMap;
import java.util.List;
import java.util.Map;
import org.dmg.pmml.FieldName;
import org.dmg.pmml.PMML;
import org.jpmml.evaluator.Evaluator;
import org.jpmml.evaluator.FieldValue;
import org.jpmml.evaluator.InputField;
import org.jpmml.evaluator.ModelEvaluator;
import org.jpmml.evaluator.ModelEvaluatorFactory;
import org.jpmml.evaluator.TargetField;
public class PMMLPrediction {
public static void main(String[] args) throws Exception {
String pathxml = "lightgbm.pmml";
Map<String, Double> map = new HashMap<String, Double>();
//拼装模型参数
map.put("sepal_length", 5.1);
map.put("sepal_width", 3.5);
map.put("petal_length", 1.4);
map.put("petal_width", 0.2);
predictLrHeart(map, pathxml);
}
public static void predictLrHeart(Map<String, Double> irismap, String pathxml) throws Exception {
PMML pmml;
//模型导入
File file = new File(pathxml);
InputStream inputStream = new FileInputStream(file);
try (InputStream is = inputStream) {
pmml = org.jpmml.model.PMMLUtil.unmarshal(is);
ModelEvaluatorFactory modelEvaluatorFactory = ModelEvaluatorFactory
.newInstance();
ModelEvaluator<?> modelEvaluator = modelEvaluatorFactory
.newModelEvaluator(pmml);
Evaluator evaluator = (Evaluator) modelEvaluator;
List<InputField> inputFields = evaluator.getInputFields();
//过模型的原始特征,从画像中获取数据,作为模型输入
Map<FieldName, FieldValue> arguments = new LinkedHashMap<>();
for (InputField inputField : inputFields) {
FieldName inputFieldName = inputField.getName();
Object rawValue = irismap
.get(inputFieldName.getValue());
FieldValue inputFieldValue = inputField.prepare(rawValue);
arguments.put(inputFieldName, inputFieldValue);
}
Map<FieldName, ?> results = evaluator.evaluate(arguments);
List<TargetField> targetFields = evaluator.getTargetFields();
//对于分类问题等有多个输出。
for (TargetField targetField : targetFields) {
FieldName targetFieldName = targetField.getName();
Object targetFieldValue = results.get(targetFieldName);
System.err.println("target: " + targetFieldName.getValue()
+ " value: " + targetFieldValue);
}
}
}
}
PMML工具集
模型转换库,生成PMML文件
Python模型:
- Nyoka,支持Scikit-Learn,LightGBM,XGBoost,Statsmodels和Keras。
- JPMML系列,比如JPMML-SkLearn、JPMML-XGBoost、JPMML-LightGBM等,提供命令行程序导出模型到PMML。
R模型:
Spark:
模型评估库,读取PMML
Java:
- JPMML-Evaluator,纯Java的PMML预测库,开源协议是AGPLV3。
- PMML4S,使用Scala开发,方便在Scala和Java中使用,接口简单好用,开源协议是常用的宽松协议Apache2。
Python:
- PyPMML,Python库调用PMML,PyPMML是PMML4S包装的Python接口。
Spark:
PySpark:
REST API:
- AI-Serving,同时为PMML模型提供REST API和gRPC API,开源协议Apache2。
- Openscoring,提供REST API,开源协议AGPLV3。


