在SQL中,IN和EXISTS(以及它们的否定形式NOT IN和NOT EXISTS)是常用的子查询条件,用于检查某个值是否在子查询结果集中存在。虽然它们可以实现类似的功能,但在语法、性能和行为上存在一些差异。 IN IN 用于检…

欧路词典简介 欧路词典是一款功能强大的跨平台词典软件,支持Mac、iOS、Android、Windows等多种操作系统。以下是对欧路词典的详细介绍: 核心功能与特点 支持多种词典格式:欧路词典支持加载MDict、灵格斯、Babyl…
PyPI简介 PyPI是一个在线存储库,用于托管和分发Python软件包。它为Python开发者提供了一个集中管理和查找第三方库的地方。PyPI上的每个包都有一个唯一的名称和版本号,用户可以通过pip(Python的包管理工具)来安…
在 Python 中,导入模块是使用库功能的基本方式。Python 标准库提供了大量的模块,涵盖了广泛的功能和工具,供开发者使用。与导入模块相关的 Python 标准库主要包括 importlib 和 pkgutil,这两个库提供了对模块和…

数据加密概述 数据加密在现代信息安全中是至关重要的,因为它提供了一种有效的方法来保护信息的机密性、完整性和可用性。以下是一些需要数据加密的主要原因: 保护隐私:加密可以防止个人和敏感信息被未经授权的…

在Python使用过程中免不了与本地文件的一些交互,中间涉及到文件目录的访问,文件的读写等。先前整理过一篇Python文件的读写操作,今天主要从标准库的角度重新梳理,完善现有的知识体系。 pathlib:面向对象的文…

Unicodedata简介 unicodedata模块是Python标准库中的一个模块,用于处理Unicode字符数据。Unicode是一种字符编码标准,它能够为世界上几乎所有的字符提供唯一的编号,支持多语言文本的表示。它提供了一些工具和函数…
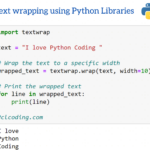
Textwrap简介 textwrap是Python标准库中的一个模块,专门用于处理和格式化文本。它提供了多种方法,可以轻松地将文本格式化为指定宽度的段落、调整缩进、处理长字符串的换行等操作。textwrap模块非常适合用于生成命…
Difflib简介 difflib是Python标准库中的一个模块,用于比较序列,尤其是字符串序列。它提供了一些类和函数,可以用于计算两个序列之间的差异,生成差异报告,以及帮助实现文本合并等功能。 产生背景 文本比较…

Python的string模块提供了一组用于处理字符串的常量和函数,方便用户进行各种字符串操作。虽然Python的字符串类型本身已经非常强大,但string模块提供了一些额外的工具和符号集,简化了特定类型的字符串操作。 常…






