Fuzzy C-Means简介
模糊理论
模糊控制是自动化控制领域的一项经典方法。其原理则是模糊数学、模糊逻辑。1965,L.A. Zadeh发表模糊集合“Fuzzy Sets”的论文,首次引入隶属度函数的概念,打破了经典数学“非0即1”的局限性,用[0,1]之间的实数来描述中间状态。
很多经典的集合(即:论域U内的某个元素是否属于集合A,可以用一个数值来表示。在经典集合中,要么0,要么1)不能描述很多事物的属性,需要用模糊性词语来判断。比如天气冷热程度、人的胖瘦程度等等。模糊数学和模糊逻辑把只取1或0二值(属于/不属于)的普通集合概念推广0~1区间内的多个取值,即隶属度。用“隶属度”来描述元素和集合之间的关系。
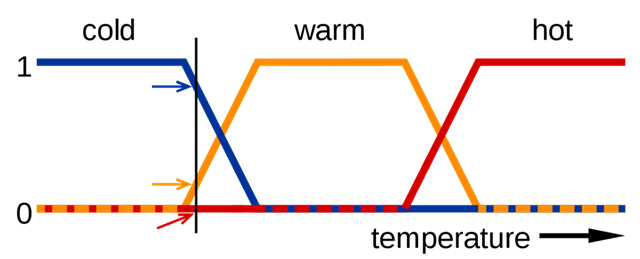
如图所示,对于冷热程度,我们采取三个模糊子集:冷、暖、热。对于某一个温度,可能同时属于两个子集。要进一步具体判断,我们就需要提供一个描述“程度”的函数,即隶属度。
例如,身高可以分为“高”、“中等”、“矮”三个子集。取论域U(即人的身高范围)为[1.0,3.0],单位m。在U上定义三个隶属度函数来确定身高与三个模糊子集的关系:
$$\mu_{\text{矮}}(x)=\begin{cases}1&1.0\leq x\leq1.50\\\frac{1.65-x}{0.15}&1.50\leq x\leq1.65\\0&1.65<x\leq3.0\end{cases}$$
模糊规则的设定:
- 专家的经验和知识,藉由询问经验丰富的专家,在获得系统的知识后,将知识改为…THEN….的型式。
- 操作员的操作模式,记录熟练的操作员的操作模式,并将其整理为…THEN….的型式。
- 自学习,设定的模糊规则可能存在偏差,模糊控制器能依设定的目标,增加或修改模糊控制规则
FCM初识
FCM的C跟K-Means的K是一样的,指的是聚类的数目。F—Fuzzy是模糊的意思,指的是“一个事件发生的程度”。用在我们的聚类上面,第一条记录以怎样的概率或者说程度属于第一类,又以怎样的程度属于第二类等等。跟传统的聚类有所区别的地方就是,他改变了传统分类的时候非此即彼的一个现象,一个对象可以以不同的程度同时属于多个类。这个其实是跟我们的现实世界是更契合的。比如说,“秃与不秃”,一个人有多少发量就说他是秃的。

所以说,“模糊”概念的提出,更能描述现实。模糊的程度我们用模糊函数$\mu_A(x)$来衡量他表示的是集合X中的元素x对集合A的隶属程度。
FCM算法是一种基于划分的聚类算法,它的思想就是使得被划分到同一簇的对象之间相似度最大,而不同簇之间的相似度最小。模糊C均值算法是普通C均值算法的改进,普通C均值算法对于数据的划分是硬性的,而FCM则是一种柔性的模糊划分。
情景:假设现在有一群人,要将他们自动分成大人和小孩两类,以身高作为分类标准(若身高大于160cm为大人,小于160cm为小孩)。现有一人身高为100cm,那么根据上述标准,不难判断,他会被划分到小孩一组。但是如果他的身高为159cm,该如何划分呢?
- IDEA1:无论如何159cm总是小于160cm,应该被分到小孩组。
- IDEA2:159cm很接近160cm,更偏离小孩组,应该被分到大人组。
以上两种说法体现了普通C均值算法(HCM)和模糊C均值算法(FCM)的差异:
- 普通C均值算法在分类时有一个硬性标准,根据该标准进行划分,分类结果非此即彼。(IDEA1)
- 模糊C均值算法更看重隶属度,即更接近于哪一方,隶属度越高,其相似度越高。(IDEA2)
由以上叙述不难判断,用模糊C均值算法来进行组类划分会使结果更加准确!
Fuzzy C-Means算法原理
基础概念
隶属度函数
隶属度函数是表示一个对象x隶属于集合A的程度的函数,通常记做$\mu_A(x)$,其自变量范围是所有可能属于集合A的对象(即集合A所在空间中的所有点),$\mu_A(x)$的取值范围是[0,1],即$0<=\mu_A(x)<=1$。越接近于1表示隶属度越高,反之越低。
模糊集合
一个定义在空间X={x}上的隶属度函数就定义了一个模糊集合A,即这个模糊集合里的元素对某一标准的隶属度是基本相近的。在聚类的问题中,可以把聚类生成的簇看成一个个模糊集合,因此,每个样本点对簇的隶属度就在[0,1]区间内。
FCM原理
模糊c均值聚类融合了模糊理论的精髓。相较于k-means的硬聚类,模糊c提供了更加灵活的聚类结果。因为大部分情况下,数据集中的对象不能划分成为明显分离的簇,指派一个对象到一个特定的簇有些生硬,也可能会出错。故,对每个对象和每个簇赋予一个权值,指明对象属于该簇的程度。当然,基于概率的方法也可以给出这样的权值,但是有时候我们很难确定一个合适的统计模型,因此使用具有自然地、非概率特性的模糊c均值就是一个比较好的选择。
简单地说,就是要最小化目标函数$J_m$:(在一些资料中也定义为SSE即误差的平方和)
$$J_m=\sum_{i=1}^N\sum_{j=1}^Cu_{ij}^m\left\|x_i-c_j\right\|^2,1\leq m<\infty$$
m是一个模糊化程度的参数,待会我们会提到它对算法性能的影响。这个算法有一个约束条件,就是某一个元素对所有类别的隶属程度的值加起来要等于1。
i,j是类标号;$u_{ij}$表示样本属于j类的隶属度。i表示第i个样本,x是具有d维特征的一个样本。是j簇的中心,也具有d维度。||*||可以是任意表示距离的度量。
聚类要达到的最终效果就是类内相似度差异最小,类间相似度差异最大,这个时候点和中心的加权距离之和就是最小的。所以我们我们只要使得目标函数取得最小值就可以了。所以最优解的的表达式就是:
$$\min(J_m(U,V))=\min(\sum_{i=1}^c\sum_{j=1}^nu_{ij}^md_{ij}^2)$$
对于有约束条件的求极值问题,一般使用拉格朗日乘子法解决。先构造拉格朗日函数:
$$F=\sum_{i=1}^c\sum_{j=1}^nu_{ij}^md_{ij}^2+\sum_{j=1}^n\lambda_j(\sum_{i=1}^cu_{ij}-1)$$
函数中共有三个变量,$u_{ij}$,$v_i$,和$\lambda_j$,分别求偏导,得到U和V的最优解
$$u_{ij}=\left[{\sum\limits_{k=1}^c{(\frac{d_{ij}}{d_{kj}})}^{\frac{2}{m-1}}\right]^{-1}$$
$$v_{i}=\frac{\sum_{j=1}^{n}x_{j}\mu^{_{ij}^{m}}}{\sum_{j=1}^{n}\mu_{ij}^{m}}$$
注:对于单个样本,它对于每个簇的隶属度之和为1。
迭代的终止条件为:
$$\max_{ij}{\left|u_{ij}^{(k+1)}-u_{ij}^{(k)}\right|}<\varepsilon_i$$
其中k是迭代步数,是误差阈值。上式含义是,继续迭代下去,隶属程度也不会发生较大的变化。即认为隶属度不变了,已经达到比较优(局部最优或全局最优)状态了。该过程收敛于目标$J_m$的局部最小值或鞍点。
抛开复杂的算式,这个算法的意思就是:给每个样本赋予属于每个簇的隶属度函数。通过隶属度值大小来将样本归类。
算法步骤

- 初始化设定聚类个数 c (1<c<n),模糊指数 m (m>1),最大迭代数 T,收敛的精度 ε,用随机数初始化隶属度矩阵 U(0)
- 计算质心,FCM 中的质心有别于传统质心的地方在于,它是以隶属度为权重做一个加权平均。
- 更新模糊伪划分,即更新权重(隶属度)。简单地说,如果 x 越靠近质心 c,则隶属度越高,反之越低。
- 重复优化过程,直到满足如下的终止条件
参数的选择
前面提到,在应用 FCM 对给定数据集进行聚类分析时,需要涉及两个参数的选取问题:c 和 m。只有选取正确了才能得到好的聚类效果。所以说怎样选取好的参数是关键所在。
聚类数目 c 的选择
对 c 的选取我们有一个评价指标,就是 L(c) 这个函数,分子表示的是类间距离之和,分母表示的是类内间距之和,因此整个 L 的值就越大越好。
$$\mathrm{L}(c)=\frac{\sum_{i=1}^c\sum_{j=1}^nu_{ij}^m\left\|v_i-\bar{x}\right\|^2/(c-1)}{\sum_{i=1}^c\sum_{j=1}^nu_{ij}^m\left\|x_j-v_i\right\|^2/(n-c)}$$
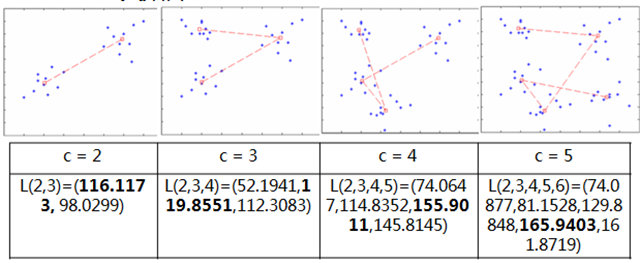
下面四个图是论文里面对不同的 c 做的一个实验,表格第一行指的是最佳的分类数目,第二行是 L 函数对不同分类数目的值,可以看到用 L 函数就可以选择出最佳的 c。
模糊系数 m 的选择
另外,目标函数里面的 m 值也是需要我们确定好的。那这个 m 值我们怎样选择呢,首先 m 代表的是模糊 C 平均算法的模糊系数,它可以影响分类的准确程度。
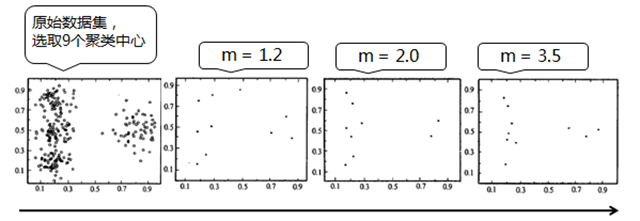
我们看下面四张图,第一个图是原始的数据集,我们给定 c 等于 9,2,3,4 这三个图里我们只给出中心向量,当 m=1.2 的时候,这 9 个点比较分散,这样就会受噪声点的影响比较大,远离了我们的主流,而当 m=3.5 的时候这些点又比较集中,对偏离主流的点的控制力又比较弱。
通常来说,m 选取 2.0 是比较合理的。
FCM的Python实现
```python
# -*- coding: utf-8 -*-
"""
Created on Wed Mar 27 10:51:45 2019
@author: youxinlin
"""
import copy
import math
import random
import time
global MAX # 用于初始化隶属度矩阵U
MAX = 10000.0
global Epsilon # 结束条件
Epsilon = 0.0000001
def import_data_format_iris(file):
"""
file这里是输入文件的路径,如iris.txt.
格式化数据,前四列为data,最后一列为类标号(有0,1,2三类)
如果是你自己的data,就不需要执行此段函数了。
"""
data = []
cluster_location = []
with open(str(file), 'r') as f:
for line in f:
current = line.strip().split(",") # 对每一行以逗号为分割,返回一个list
current_dummy = []
for j in range(0, len(current)-1):
current_dummy.append(float(current[j])) # current_dummy存放data
# 下面注这段话提供了一个范例:若类标号不是0,1,2之类数字时该怎么给数据集
j += 1
if current[j] == "Iris-setosa\n":
cluster_location.append(0)
elif current[j] == "Iris-versicolor\n":
cluster_location.append(1)
else:
cluster_location.append(2)
data.append(current_dummy)
print("加载数据完毕")
return data
# return data, cluster_location
def randomize_data(data):
"""
该功能将数据随机化,并保持随机化顺序的记录
"""
order = list(range(0, len(data)))
random.shuffle(order)
new_data = [[] for i in range(0, len(data))]
for index in range(0, len(order)):
new_data[index] = data[order[index]]
return new_data, order
def de_randomise_data(data, order):
"""
此函数将返回数据的原始顺序,将randomise_data()返回的order列表作为参数
"""
new_data = [[] for i in range(0, len(data))]
for index in range(len(order)):
new_data[order[index]] = data[index]
return new_data
def print_matrix(list):
"""
以可重复的方式打印矩阵
"""
for i in range(0, len(list)):
print(list[i])
def initialize_U(data, cluster_number):
"""
这个函数是隶属度矩阵U的每行加起来都为1.此处需要一个全局变量MAX.
"""
global MAX
U = []
for i in range(0, len(data)):
current = []
rand_sum = 0.0
for j in range(0, cluster_number):
dummy = random.randint(1, int(MAX))
current.append(dummy)
rand_sum += dummy
for j in range(0, cluster_number):
current[j] = current[j] / rand_sum
U.append(current)
return U
def distance(point, center):
"""
该函数计算2点之间的距离(作为列表)。我们指欧几里德距离。闵可夫斯基距离
"""
if len(point) != len(center):
return -1
dummy = 0.0
for i in range(0, len(point)):
dummy += abs(point[i] - center[i]) ** 2
return math.sqrt(dummy)
def end_conditon(U, U_old):
"""
结束条件。当U矩阵随着连续迭代停止变化时,触发结束
"""
global Epsilon
for i in range(0, len(U)):
for j in range(0, len(U[0])):
if abs(U[i][j] - U_old[i][j]) > Epsilon:
return False
return True
def normalise_U(U):
"""
在聚类结束时使U模糊化。每个样本的隶属度最大的为1,其余为0
"""
for i in range(0, len(U)):
maximum = max(U[i])
for j in range(0, len(U[0])):
if U[i][j] != maximum:
U[i][j] = 0
else:
U[i][j] = 1
return U
# m的最佳取值范围为[1.5,2.5]
def fuzzy(data, cluster_number, m):
"""
这是主函数,它将计算所需的聚类中心,并返回最终的归一化隶属矩阵U.
参数是:簇数(cluster_number)和隶属度的因子(m)
"""
# 初始化隶属度矩阵U
U = initialize_U(data, cluster_number)
# print_matrix(U)
# 循环更新U
while(True):
# 创建它的副本,以检查结束条件
U_old = copy.deepcopy(U)
# 计算聚类中心
C = []
for j in range(0, cluster_number):
current_cluster_center = []
for i in range(0, len(data[0])):
dummy_sum_num = 0.0
dummy_sum_dum = 0.0
for k in range(0, len(data)):
# 分子
dummy_sum_num += (U[k][j] ** m) * data[k][i]
# 分母
dummy_sum_dum += (U[k][j] ** m)
# 第i列的聚类中心
current_cluster_center.append(dummy_sum_num / dummy_sum_dum)
# 第j簇的所有聚类中心
C.append(current_cluster_center)
# 创建一个距离向量, 用于计算U矩阵。
distance_matrix = []
for i in range(0, len(data)):
current = []
for j in range(0, cluster_number):
current.append(distance(data[i], C[j]))
distance_matrix.append(current)
# 更新U
for j in range(0, cluster_number):
for i in range(0, len(data)):
dummy = 0.0
for k in range(0, cluster_number):
# 分母
dummy += (distance_matrix[i][j] / distance_matrix[i][k]) ** (2 / (m - 1))
U[i][j] = 1 / dummy
if end_conditon(U, U_old):
print("结束聚类")
break
print("标准化U")
U = normalise_U(U)
return U
def checker_iris(final_location):
"""
和真实的聚类结果进行校验比对
"""
right = 0.0
for k in range(0, 3):
checker = [0, 0, 0]
for i in range(0, 50):
for j in range(0, len(final_location[0])):
if final_location[i + (50 * k)][j] == 1: # i+(50*k)表示j表示第j类
checker[j] += 1 # checker分别统计每一类分类正确的个数
right += max(checker) # 累加分类正确的个数
print('分类正确的个数是:', right)
answer = right / 150 * 100
return "准确率:" + str(answer) + "%"
if __name__ == '__main__':
# 加载数据
data = import_data_format_iris("iris.txt")
# print_matrix(data)
# 随机化数据
```data, order = randomize_data(data)
#print_matrix(data)
start = time.time()
#现在我们有一个名为data的列表,它只是数字
#我们还有另一个名为cluster_location的列表,它给出了正确的聚类结果位置
#调用模糊C均值函数
final_location = fuzzy(data, 3, 2)
#还原数据
final_location = de_randomise_data(final_location, order)
# print_matrix(final_location)
#准确度分析
print(checker_iris(final_location))
print("用时:{0}".format(time.time() - start))
参考链接:



“聚类要达到的最终效果就是类内相似度最小,类间相似度最大,这个时候点和中心的加权距离之和就是最小的。”这个是不是讲反了呢?
是的 感谢指正