用户画像在互联网相关的各个行业都被提及,从产品经理到市场营销再到大数据。感觉自己负责的产品不与用户画像扯上点关系就很Low。但用户画像到底是什么其实没有多少人能说的明白。 在我的理解里,用户画像可以分为…
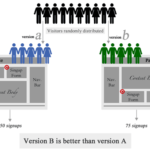
A/B测试是我们在日常工作中经常使用的工具,A/B测试的核心就是:确定两个元素或版本(A和B)哪个版本更好,你需要同时实验两个版本。最后,选择最好的版本使用。 A/B比较困难的点是确定在什么时候可以终止实验。…
在日常工作中用到的比较多的还是树回归模型,由于LightGBM不需要的类别数据进行预处理所以用得特别多,中间涉及到超参数优化时通常使用随机参数优化方法。在算法模型自动超参数优化方法中有提到了Optuna,平时工作…

在机器学习数据预处理阶段经常需要对数据进行缺失值处理。关于缺失值的处理并没有想象中的那么简单。以下为一些经验分享。 数据缺失类型 完全随机丢失(MCAR,Missing Completely at Random):某个变量是否缺…
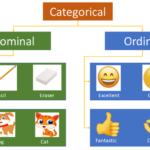
类别型特征(categorical feature)主要是指职业,血型等在有限类别内取值的特征。它的原始输入通常是字符串形式,大多数算法模型不接受数值型特征的输入,针对数值型的类别特征会被当成数值型特征,从而造成训练的…
什么是信用评分卡模型? 评分卡模型又叫做信用评分卡模型,最早由美国信用评分巨头 FICO 公司于 20 世纪 60 年代推出,在信用风险评估以及金融风险控制领域中广泛使用。银行利用评分卡模型对客户的信用历史数据的多…
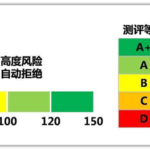
APP黑产简介 随着厂商的业务体系越来越庞大,各类优惠活动的次数相应的也越发频繁,尤其是一些有“新用户”限制的活动,导致黑灰产从业人员需要更多的新设备获取利益,而改机工具可以解决黑灰产在移动端的设备成本问…
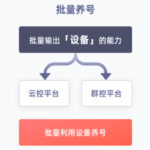
设备ID,简单来说就是一串符号(或者数字),映射现实中硬件设备。如果这些符号和设备是一一对应的,可称之为“唯一设备ID(Unique Device Identifier)”。不幸的是,对于Android平台而言,没有稳定的API可以让开发…

iOS中的设备唯一标识 在iOS7之前,曾经有过很多获取设备唯一标识的方法。但是它们都先后被苹果禁止掉了。这些被禁止掉的包括UDID、Mac地址、OpenUDID。在iOS7之后,我们可以选择的唯一标识有IDFA、IDFV、DeviceToke…
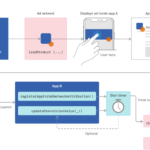
为了应付黑产,需要对 Android 设备进行安全性检测来确定风险的大小。 Android 安全机制 Android 采用分层的系统架构,由下往上分别是 linux 内核层、硬件抽象层、系统运行时库层、应用程序框架层和应用程序层。A…






