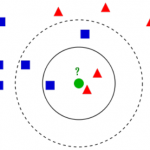
什么是K-近邻算法? K近邻法(k-nearest neighbor, k-NN)是1967年由Cover T和Hart P提出的一种基本分类与回归方法。它的工作原理是:存在一个样本数据集合,也称作为训练样本集,并且样本集中每个数据都存在标签,即…
上一篇Folium 的文章中,针对 Choropleth 的使用有过简单的介绍,但是对于如何调整分级样式图等,没有进一步的阐述。这篇文章结果自己的使用经验做些简单的总结。 生成 Choropleth 分级着色图的方法目前主要有两种…
Folium简介 Folium是一个基于leaflet.js的Python地图库,其中,Leaflet是一个非常轻的前端地图可视化库。即可以使用Python语言调用Leaflet的地图可视化能力。它不单单可以在地图上展示数据的分布图,还可以使用Vinc…
先前的文章中介绍了基于密度的聚类方法DBSCAN,今天要学习的是 HDBSCAN。单从名字上看,两者必然存在一定的关系。我们先来看看官方的介绍: HDBSCAN - Hierarchical Density-Based Spatial Clustering of Applicati…
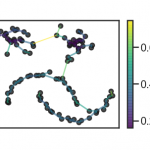
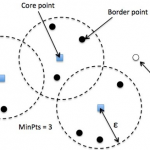
在前面介绍的DBSCAN算法中,有两个初始参数Eps(邻域半径)和minPts(Eps邻域最小点数)需要手动设置,并且聚类的结果对这两个参数的取值非常敏感,不同的取值将产生不同的聚类结果。为了克服DBSCAN算法这一缺点,提…
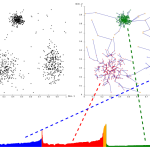
K-Means算法和MeanShift算法都是基于距离的聚类算法,基于距离的聚类算法的聚类结果是球状的簇,当数据集中的聚类结果是非球状结构时,基于距离的聚类算法的聚类效果并不好。 与基于距离的聚类算法不同的是,基…
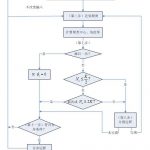
ISODATA算法(Iterative Self Organizing Data Analysis Techniques Algorithm,迭代自组织数据分析方法)和K-Means算法是相似的算法,都是属于无监督的聚类分析方法,但是 在之前介绍的K-Means算法中,有两大缺陷…
大部分聚类方法针对的是多维数据,现实场景中还有可能存在以为数据的情况,针对以为数组的聚类和多维的数据有很大的不同,今天就来实战演练下: 需求内容:分析订单的价格分布 常见方案:按照100为梯度,分析不…
在学习聚类算法得时候并没有涉及到评估指标,主要原因是聚类算法属于非监督学习,并不像分类算法那样可以使用训练集或测试集中得数据计算准确率、召回率等。那么如何评估聚类算法得好坏呢?好的聚类算法,一般要求类…

异常监控系统 Skyline的文章中,详细介绍了 Skyline 的架构,今天主要分享的是自己在部署 Skyline 中的一些记录。 项目地址:https://github.com/earthgecko/skyline 参考文档:https://earthgecko-skyline.read…