近年来,深度学习技术在自然语言处理领域中得到了广泛应用。基于深度神经网络的模型已经在词性标注、命名实体识别、情感分类等诸多任务上显著超越了传统模型。用深度学习技术来处理自然语言文本,离不开文本的向量化,即把一段文本转化成一个n维的向量。在大量任务中,作为千变万化的文本向量化网络架构的共同底层,嵌入层(Embedding Layer)负责词汇(文本的基本单元)到向量(神经网络计算的核心对象)的转换,是自然语言通向深度神经网络的入口。大量的学界研究和业界实践证明,使用大规模高质量的词向量初始化嵌入层,可以在更少的训练代价下得到性能更优的深度学习模型。
腾讯AI Lab词向量数据简介

腾讯AI Lab此次公开的中文词向量数据包含800多万中文词汇,其中每个词对应一个200维的向量。相比现有的中文词向量数据,腾讯AI Lab的中文词向量着重提升了以下3个方面,相比已有各类中文词向量大大改善了其质量和可用性:
腾讯AI Lab词向量的特点
- 覆盖率(Coverage):该词向量数据包含很多现有公开的词向量数据所欠缺的短语,比如“不念僧面念佛面”、“冰火两重天”、“煮酒论英雄”、“皇帝菜”、“喀拉喀什河”等。以“喀拉喀什河”为例,利用腾讯AI Lab词向量计算出的语义相似词如下:墨玉河、和田河、玉龙喀什河、白玉河、喀什河、叶尔羌河、克里雅河、玛纳斯河
- 新鲜度(Freshness):该数据包含一些最近一两年出现的新词,如“恋与制作人”、“三生三世十里桃花”、“打call”、“十动然拒”、“供给侧改革”、“因吹斯汀”等。以“因吹斯汀”为例,利用腾讯AI Lab词向量计算出的语义相似词如下:一颗赛艇、因吹斯听、城会玩、厉害了word哥、emmmmm、扎心了老铁、神吐槽、可以说是非常爆笑了
- 准确性(Accuracy):由于采用了更大规模的训练数据和更好的训练算法,所生成的词向量能够更好地表达词之间的语义关系,如下列相似词检索结果所示:
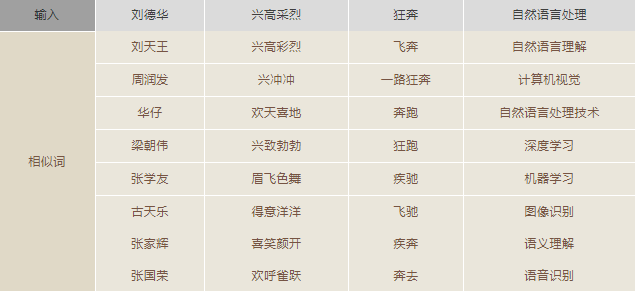
腾讯AI Lab词向量的构建
- 语料采集:训练词向量的语料来自腾讯新闻和天天快报的新闻语料,以及自行抓取的互联网网页和小说语料。大规模多来源语料的组合,使得所生成的词向量数据能够涵盖多种类型的词汇。而采用新闻数据和最新网页数据对新词建模,也使得词向量数据的新鲜度大为提升。
- 词库构建:除了引入维基百科和百度百科的部分词条之外,还实现了Shi等人于2010年提出的语义扩展算法,可从海量的网页数据中自动发现新词——根据词汇模式和超文本标记模式,在发现新词的同时计算新词之间的语义相似度。
- 训练算法:腾讯AI Lab采用自研的Directional Skip-Gram (DSG)算法作为词向量的训练算法。DSG算法基于广泛采用的词向量训练算法Skip-Gram (SG),在文本窗口中词对共现关系的基础上,额外考虑了词对的相对位置,以提高词向量语义表示的准确性。
项目地址:https://ai.tencent.com/ailab/nlp/en/download.html
腾讯AI Lab词向量的使用
词向量数据的加载与使用
# -*- coding: utf-8 -*-
from gensim.models import KeyedVectors
file = 'Tencent_AILab_ChineseEmbedding.txt'
wv_from_text = KeyedVectors.load_word2vec_format(file, binary=False)
wv_from_text.save('Tencent_AILab_ChineseEmbedding.bin')
model = KeyedVectors.load('Tencent_AILab_ChineseEmbedding.bin')
print(model.most_similar(positive=['女','国王'], negative=['男'], topn=1))
print(model.doesnt_match("上海 成都 广州 北京".split(" ")))
print(model.similarity('女人', '男人'))
print(model.most_similar('特朗普', topn=10))
print(model.n_similarity(["中国","北京"], ["俄罗斯","莫斯科"]))
总体老说腾讯AI Lab开源的这份中文词向量的覆盖度比较高,精度也比较高。但是词向量里含有大量停用词,导致文件比较大加载速度较慢(数分钟),而且内存消耗较大,实际使用时根据场景需要裁剪以节省性能。由于这个词向量就是按照训练的词频进行排序的,前100w就能把我们的常用词覆盖到了。这里有已经裁剪好的数据:https://github.com/cliuxinxin/TX-WORD2VEC-SMALL
Tencent_AILab_ChineseEmbedding读入与高效查询比较常见的读入方式:
import numpy as np
def load_embedding(path):
embedding_index = {}
f = open(path, encoding='utf8')
for index, line in enumerate(f):
if index == 0:
continue
values = line.split(' ')
word = values[0]
coefs = np.asarray(values[1:], dtype='float32')
embedding_index[word] = coefs
f.close()
return embedding_index
load_embedding('Tencent_AILab_ChineseEmbedding.txt')
这样纯粹就是以字典的方式读入,当然用于建模没有任何问题,但是笔者想在之中进行一些相似性操作,最好的就是重新载入gensim.word2vec系统之中,但载入时可能发生如下报错:
ValueError: invalid vector on line 418987 (is this really the text format?)
仔细一查看,发现原来一些词向量的词就是数字,譬如-0.2121或 57851,所以一直导入不进去。只能自己用txt读入后,删除掉这一部分,保存的格式参考下面。
54 是 -0.119938 0.042054504 -0.02282253 -0.10101332 中国人 0.080497965 0.103521846 -0.13045108 -0.01050107 你 -0.0788643 -0.082788676 -0.14035964 0.09101376 我 -0.14597991 0.035916027 -0.120259814 -0.06904249
第一行是一共5个词,每个词维度为4.
然后清洗完毕之后,就可以读入了:
wv_from_text = gensim.models.KeyedVectors.load_word2vec_format('Tencent_AILab_ChineseEmbedding_refine.txt', binary=False)
但是又是一个问题,占用内存太大,导致不能查询相似词:
wv_from_text.init_sims(replace=True) #神奇,很省内存,可以运算most_similar
该操作是指model已经不再继续训练了,那么就锁定起来,让Model变为只读的,这样可以预载相似度矩阵,对于后面得相似查询非常有利。
未知词、短语向量补齐与域内相似词搜索
未知词语、短语的补齐手法是参考FastText的用法,当出现未登录词或短语的时候,会:先将输入词进行n-grams,然后去词表之中查找,查找到的词向量进行平均。主要函数可见:
import numpy as np
def compute_ngrams(word, min_n, max_n):
# BOW, EOW = ('<', '>') # Used by FastText to attach to all words as prefix and suffix
extended_word = word
ngrams = []
for ngram_length in range(min_n, min(len(extended_word), max_n)+1):
for i in range(0, len(extended_word)-ngram_length+1):
ngrams.append(extended_word[i:i+ngram_length])
return list(set(ngrams))
def wordVec(word, wv_from_text, min_n=1, max_n=3):
'''
ngrams_single/ngrams_more,主要是为了当出现oov的情况下,最好先不考虑单字词向量
'''
#确认词向量维度
word_size = wv_from_text.wv.syn0[0].shape[0]
#计算word的ngrams词组
ngrams = compute_ngrams(word, min_n=min_n, max_n=max_n)
#如果在词典之中,直接返回词向量
if word in wv_from_text.wv.vocab.keys():
return wv_from_text[word]
else:
#不在词典的情况下
word_vec = np.zeros(word_size, dtype=np.float32)
ngrams_found = 0
ngrams_single = [ng for ng in ngrams if len(ng)==1]
ngrams_more = [ng for ng in ngrams if len(ng)>1]
#先只接受2个单词长度以上的词向量
for ngram in ngrams_more:
if ngram in wv_from_text.wv.vocab.keys():
word_vec += wv_from_text[ngram]
ngrams_found += 1
#print(ngram)
#如果,没有匹配到,那么最后是考虑单个词向量
if ngrams_found == 0:
for ngram in ngrams_single:
word_vec += wv_from_text[ngram]
ngrams_found += 1
if word_vec.any():
return word_vec/max(1, ngrams_found)
else:
raise KeyError('all ngrams for word %s absent from model' % word)
vec = wordVec('千奇百怪的词向量', wv_from_text, min_n=1, max_n=3) #词向量获取
wv_from_text.most_similar(positive=[vec], topn=10) #相似词查找
compute_ngrams函数是将词条N-grams找出来,譬如:
compute_ngrams('萌萌的哒的', min_n=1, max_n=3)>>>['哒', '的哒的', '萌的', '的哒', '哒的', '萌萌的', '萌的哒', '的', '萌萌', '萌']
从词向量文件中提取词语生成自定义词库
主要应用场景:分词。(如果觉得词库太大,可以选择TOPN,目前词表是按热度排序的,所以处理起来很方便)
from tqdm import tqdm
import re
def gen_dict(input_file, output_file):
output_f = open(output_file, 'a', encoding='utf8')
with open(input_file, "r", encoding='utf-8') as f:
header = f.readline()
vocab_size, vector_size = map(int, header.split())
for i in tqdm(range(vocab_size)):
line = f.readline()
word = line.split(' ')[0]
output_f.write(word + '\n')
output_f.close()
f.close()
def gen_dict_with_chinese(input_file, output_file):
pattern = re.compile("[\u4e00-\u9fa5]")
output_f = open(output_file, 'a', encoding='utf8')
with open(input_file, "r", encoding='utf-8') as f:
lines = f.readlines()
for line in tqdm(lines):
line = line.strip()
if re.findall(pattern, line):
output_f.write(line + "\n")
output_f.close()
def gen_dict_small(input_file, output_file, size=10000):
output_f = open(output_file, 'a', encoding='utf8')
with open(input_file, "r", encoding='utf-8') as f:
f.readline()
output_f.write(str(size) + " 200\n")
for i in tqdm(range(size)):
line = f.readline()
output_f.write(line)
output_f.close()
f.close()
if __name__ == "__main__":
# gen_dict('./Tencent_AILab_ChineseEmbedding.txt',
# './dict.txt')
# gen_dict_with_chinese('./dict.txt','./dict-no-alnum.txt')
gen_dict_small(r'D:\ProgramData\Tencent_AILab_ChineseEmbedding.txt', 'dict_10000.txt', 10000)
参考链接:


