Word2vec是Google于2013年开源推出的一个用于获取词向量的工具包,关于它的介绍可以看先前整理的Word2Vec原理。
获取和处理中文语料
维基百科的中文语料库质量高、领域广泛而且开放,非常适合作为语料用来训练。相关链接:
- https://dumps.wikimedia.org/
- https://dumps.wikimedia.org/zhwiki/
- https://dumps.wikimedia.org/zhwiki/latest/zhwiki-latest-pages-articles.xml.bz2
有了语料后我们需要将其提取出来,因为wiki百科中的数据是以XML格式组织起来的,所以我们需要寻求些方法。查询之后发现有两种主要的方式:gensim的wikicorpus库,以及wikipediaExtractor。
WikiExtractor
WikipediaExtractor是一个用Python写的维基百科抽取器,使用非常方便。下载之后直接使用这条命令即可完成抽取,运行时间很快。执行以下命令。
相关链接:
相关命令:
git clone https://github.com/attardi/wikiextractor.git python ./wikiextractor/WikiExtractor.py -b 2048M -o extracted zhwiki-latest-pages-articles.xml.bz2
相关说明:
- -b 2048M表示的是以128M为单位进行切分,默认是1M。
- extracted:需要将提取的文件存放的路径;
- zhwiki-latest-pages-articles.xml.bz2:需要进行提取的.bz2文件的路径
二次处理:
通过WikipediaExtractor处理时会将一些特殊标记的内容去除了,但有时这些并不影响我们的使用场景,所以只要把抽取出来的标签和一些空括号、「」、『』、空书名号等去除掉即可。
import re
import sys
import codecs
def filte(input_file):
p1 = re.compile('[(\(][,;。?!\s]*[)\)]')
p2 = re.compile('《》')
p3 = re.compile('「')
p4 = re.compile('」')
p5 = re.compile('<doc(.*)>')
p6 = re.compile('</doc>')
p7 = re.compile('『』')
p8 = re.compile('『')
p9 = re.compile('』')
p10 = re.compile('-\{.*?(zh-hans|zh-cn):([^;]*?)(;.*?)?\}-')
outfile = codecs.open('std_' + input_file, 'w', 'utf-8')
with codecs.open(input_file, 'r', 'utf-8') as myfile:
for line in myfile:
line = p1.sub('', line)
line = p2.sub('', line)
line = p3.sub('“', line)
line = p4.sub('”', line)
line = p5.sub('', line)
line = p6.sub('', line)
line = p7.sub('', line)
line = p8.sub('“', line)
line = p9.sub('”', line)
line = p10.sub('', line)
outfile.write(line)
outfile.close()
if __name__ == '__main__':
input_file = sys.argv[1]
filte(input_file)import re
保存后执行python filte.py wiki_00即可进行二次处理。
gensim的wikicorpus库
转化程序:
# -*- coding: utf-8 -*-
from gensim.corpora import WikiCorpus
import os
class Config:
data_path = '/home/qw/CodeHub/Word2Vec/zhwiki'
zhwiki_bz2 = 'zhwiki-latest-pages-articles.xml.bz2'
zhwiki_raw = 'zhwiki_raw.txt'
def data_process(_config):
i = 0
output = open(os.path.join(_config.data_path, _config.zhwiki_raw), 'w')
wiki = WikiCorpus(os.path.join(_config.data_path, _config.zhwiki_bz2), lemmatize=False, dictionary={})
for text in wiki.get_texts():
output.write(''.join(text) + '\n')
i += 1
if i % 10000 == 0:
print('Saved ' + str(i) + ' articles')
output.close()
print('Finished Saved ' + str(i) + ' articles')
config = Config()
data_process(config)
化繁为简
维基百科的中文数据是繁简混杂的,里面包含大陆简体、台湾繁体、港澳繁体等多种不同的数据。有时候在一篇文章的不同段落间也会使用不同的繁简字。这里使用opencc来进行转换。
opencc -i zhwiki_raw.txt -o zhswiki_raw.txt -c t2s.json
中文分词
这里直接使用jieba分词的命令行进行处理:
python -m jieba -d ""./zhswiki_raw.txt > ./zhswiki_cut.txt
转换成utf-8格式
非UTF-8字符会被删除
$ iconv -c -t UTF-8 -o zhwiki.utf8.txt zhwiki.zhs.txt
参考链接:https://github.com/lzhenboy/word2vec-Chinese
word2vec模型训练
C语言版本word2vec
项目地址:
安装:
git clone https://github.com/tmikolov/word2vec.git cd word2vec make
训练词向量
./word2vec -train "input.txt" -output "output.model" -cbow 1 -size 128 -window 8 -negative 25 -hs 0 -sample 1e-4 -threads 8 -binary 1 -iter 15
- -train “input.txt”表示在指定的语料库上训练模型
- -output 结果输入文件,即每个词的向量
- -cbow 是否使用cbow模型,0表示使用skip-gram模型,1表示使用cbow模型,默认情况下是skip-gram模型,cbow模型快一些,skip-gram模型效果好一些
- -size 表示输出的词向量维数
- -window 8 训练窗口的大小为8 即考虑一个单词的前八个和后八个单词(实际代码中还有一个随机选窗口的过程,窗口大小<=5)
- -negative 表示是否使用NEG方,0表示不使用,其它的值目前还不是很清楚
- -hs 是否使用HS方法,0表示不使用,1表示使用
- -sample 表示采样的阈值,如果一个词在训练样本中出现的频率越大,那么就越会被采样
- -binary 表示输出的结果文件是否采用二进制存储,0表示不使用(即普通的文本存储,可以打开查看),1表示使用,即vectors.bin的存储类型
- -threads 20 线程数
- -iter 15 迭代次数
除了上面所讲的参数,还有:
- -alpha 表示学习速率
- -min-count 表示设置最低频率,默认为5,如果一个词语在文档中出现的次数小于该阈值,那么该词就会被舍弃
- -classes 表示词聚类簇的个数,从相关源码中可以得出该聚类是采用k-means
计算相似词
./distance可以看成计算词与词之间的距离,把词看成向量空间上的一个点,distance看成向量空间上点与点的距离。
./word2vec/distance ./word2vec.word2vec.model
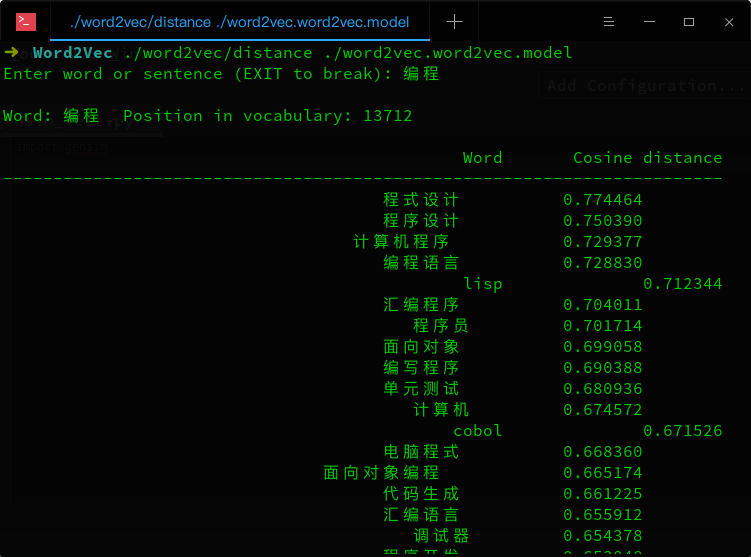
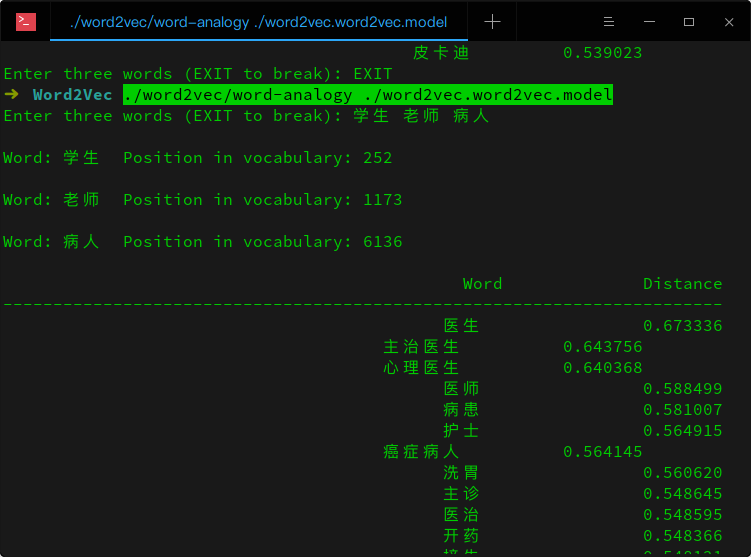
词语类比
给定三个词语A、B、C,返回(A-B+C)语义最近的词语及相似列表
./word2vec/word-analogy ./word2vec.word2vec.model
聚类
将经过分词后的语料中的词聚类并按照类别排序:
nohup ./word2vec -train resultbig.txt -output classes.txt -cbow 0 -size 200 -window 5 -negative 0 -hs 1 -sample 1e-3 -threads 12 -classes 500 & sort classes.txt -k 2 -n > classes_sorted.txt
短语分析
先利用经过分词的语料得出包含词和短语的文件phrase.txt,再训练该文件中词与短语的向量表示。
./word2phrase -train resultbig.txt -output sogouca_phrase.txt -threshold 500 -debug 2 ./word2vec -train sogouca_phrase.txt -output vectors_sogouca_phrase.bin -cbow 0 -size 300 -window 10 -negative 0 -hs 1 -sample 1e-3 -threads 8 -binary 1
Python版的Word2Vec
项目地址:https://github.com/danielfrg/word2vec
安装:pip install word2vec
整体使用和C语言版类似:
import word2vec
# word2vec.word2phrase('data/mytext', 'data/mytext-phrases', verbose=True)
word2vec.word2vec('data/mytext', 'data/mytext.bin', size=200, verbose=True, threads=4, sample=0, min_count=0)
# word2vec.word2clusters('data/mytext', 'data/mytext-clusters.txt', 100, verbose=True)
默认参数及可传入的值:
def word2vec(train, output, size=100, window=5, sample='1e-3', hs=0,
negative=5, threads=12, iter_=5, min_count=5, alpha=0.025,
debug=2, binary=1, cbow=1, save_vocab=None, read_vocab=None,
verbose=False):
"""
word2vec execution
Parameters for training:
train
Use text data from to train the model
output
Use to save the resulting word vectors/word clusters
size
Set size of word vectors; default is 100
window
Set max skip length between words; default is 5
sample
Set threshold for occurrence of words. Those that appear with
higher frequency in the training data will be randomly
down-sampled; default is 0 (off), useful value is 1e-5
hs
Use Hierarchical Softmax; default is 1 (0=not used)
negative
Number of negative examples; default is 0, common values are 5-10
(0=not used)
threads
Use threads (default 1)
min_count
This will discard words that appear less than times; default
is 5
alpha
Set the starting learning rate; default is 0.025
debug
Set the debug mode (default=2=more info during training)
binary
Save the resulting vectors in binary mode; default is 0 (off)
cbow
Use the continuous back of words model; default is 1 (skip-gram
model)
save_vocab
The vocabulary will be saved to
read_vocab
The vocabulary will be read from, not constructed from the
training data
verbose
Print output from training
Python包Gensim
gensim是一个很好用的Python NLP的包,不光可以用于使用word2vec,还有很多其他的API可以用。它封装了google的C语言版的word2vec。当然我们可以可以直接使用C语言版的word2vec来学习,但是个人认为没有gensim的python版来的方便。安装gensim是很容易的,使用”pip install gensim”即可。
项目地址:https://github.com/RaRe-Technologies/gensim
gensim提供的word2vec主要功能:
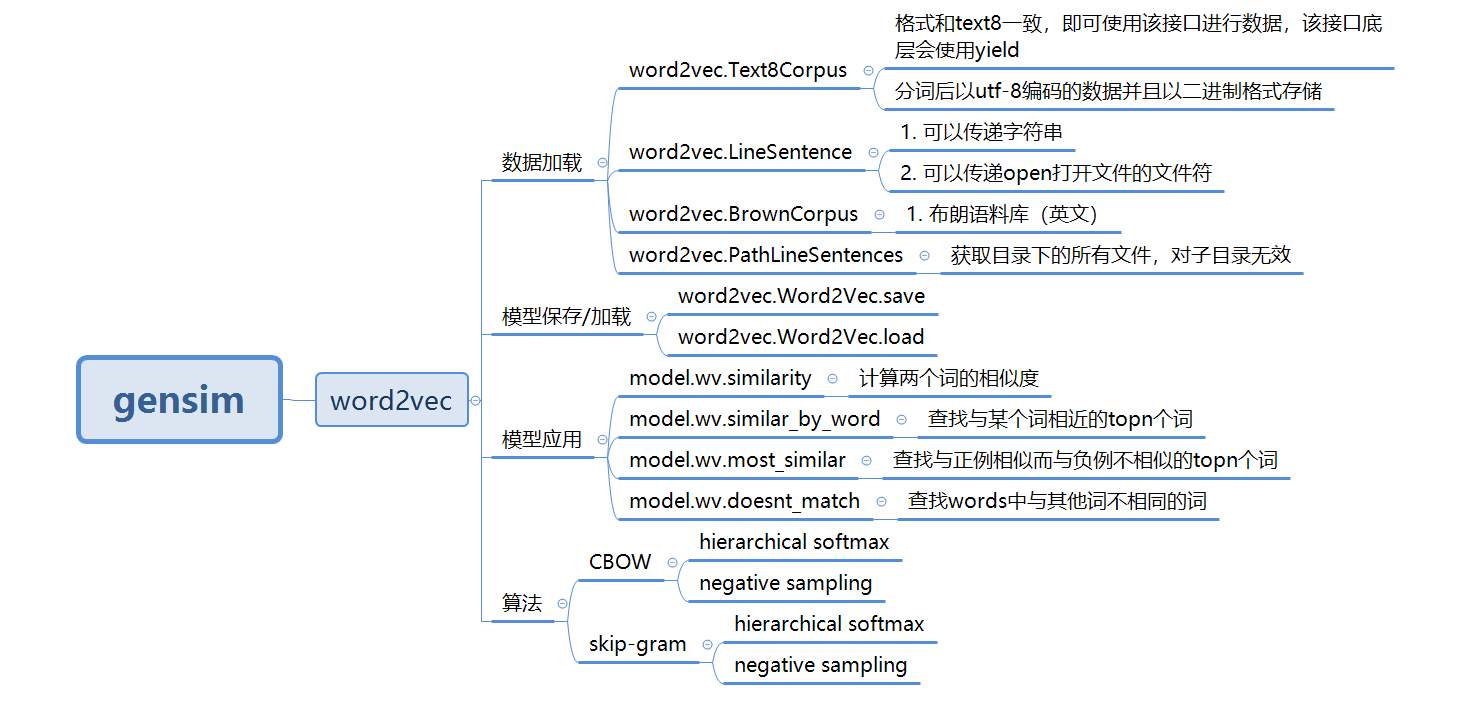
在gensim中,word2vec相关的API都在包gensim.models.word2vec中。和算法有关的参数都在类gensim.models.word2vec.Word2Vec中。算法需要注意的参数有:
- sentences: 我们要分析的语料,可以是一个列表,或者从文件中遍历读出。后面我们会有从文件读出的例子。
- size: 词向量的维度,默认值是100。这个维度的取值一般与我们的语料的大小相关,如果是不大的语料,比如小于100M的文本语料,则使用默认值一般就可以了。如果是超大的语料,建议增大维度。
- window:即词向量上下文最大距离,这个参数在我们的算法原理篇中标记为,window越大,则和某一词较远的词也会产生上下文关系。默认值为5。在实际使用中,可以根据实际的需求来动态调整这个window的大小。如果是小语料则这个值可以设的更小。对于一般的语料这个值推荐在[5,10]之间。
- sg: 即我们的word2vec两个模型的选择了。如果是0,则是CBOW模型,是1则是Skip-Gram模型,默认是0即CBOW模型。
- hs: 即我们的word2vec两个解法的选择了,如果是0,则是Negative Sampling,是1的话并且负采样个数negative大于0,则是Hierarchical Softmax。默认是0即Negative Sampling。
- negative: 即使用Negative Sampling时负采样的个数,默认是5。推荐在[3,10]之间。这个参数在我们的算法原理篇中标记为neg。
- cbow_mean: 仅用于CBOW在做投影的时候,为0,则算法中的为上下文的词向量之和,为1则为上下文的词向量的平均值。在我们的原理篇中,是按照词向量的平均值来描述的。个人比较喜欢用平均值来表示,默认值也是1,不推荐修改默认值。
- min_count: 需要计算词向量的最小词频。这个值可以去掉一些很生僻的低频词,默认是5。如果是小语料,可以调低这个值。
- iter: 随机梯度下降法中迭代的最大次数,默认是5。对于大语料,可以增大这个值。
- alpha: 在随机梯度下降法中迭代的初始步长。算法原理篇中标记为,默认是0.025。
- min_alpha: 由于算法支持在迭代的过程中逐渐减小步长,min_alpha给出了最小的迭代步长值。随机梯度下降中每轮的迭代步长可以由iter,alpha,min_alpha一起得出。这部分由于不是word2vec算法的核心内容,因此在原理篇我们没有提到。对于大语料,需要对alpha, min_alpha, iter一起调参,来选择合适的三个值。
以上就是gensim word2vec的主要的参数,可以看到相关的参数与C语言的版本类似。最简单的示例:
#引入 word2vec
from gensim.models import word2vec
#引入日志配置
import logging
logging.basicConfig(format='%(asctime)s:%(levelname)s:%(message)s', level=logging.INFO)
#引入数据集
raw_sentences = ["the quick brown fox jumps over the lazy dogs", "yoyoyoyo you go home now to sleep"]
#切分词汇
sentences = [s.split() for s in raw_sentences]
#构建模型
model = word2vec.Word2Vec(sentences, min_count=1)
#进行相关性比较
print(model.wv.similarity('dogs', 'you'))
使用小说《人民的名义》作为语料进行训练:
#-*- coding: utf-8 -*-
import jieba
from gensim.models import word2vec
jieba.suggest_freq('沙瑞金', True)
jieba.suggest_freq('田国富', True)
jieba.suggest_freq('高育良', True)
jieba.suggest_freq('侯亮平', True)
jieba.suggest_freq('钟小艾', True)
jieba.suggest_freq('陈岩石', True)
jieba.suggest_freq('欧阳菁', True)
jieba.suggest_freq('易学习', True)
jieba.suggest_freq('王大路', True)
jieba.suggest_freq('蔡成功', True)
jieba.suggest_freq('孙连城', True)
jieba.suggest_freq('季昌明', True)
jieba.suggest_freq('丁义珍', True)
jieba.suggest_freq('郑西坡', True)
jieba.suggest_freq('赵东来', True)
jieba.suggest_freq('高小琴', True)
jieba.suggest_freq('赵瑞龙', True)
jieba.suggest_freq('林华华', True)
jieba.suggest_freq('陆亦可', True)
jieba.suggest_freq('刘新建', True)
jieba.suggest_freq('刘庆祝', True)
def preprocess_in_the_name_of_people():
with open("data/in_the_name_of_people.txt", mode='rb') as f:
doc = f.read()
doc_cut = jieba.cut(doc)
result = ''.join(doc_cut)
result = result.encode('utf-8')
with open("data/in_the_name_of_people_cut.txt", mode='wb') as f2:
f2.write(result)
#使用 Text8Corpus 接口加载数据
def train_in_the_name_of_people():
sent = word2vec.Text8Corpus(fname="data/in_the_name_of_people_cut.txt")
model = word2vec.Word2Vec(sentences=sent)
model.save("data/in_the_name_of_people.model")
#使用 LineSentence 接口加载数据
def train_line_sentence():
with open("data/in_the_name_of_people_cut.txt", mode='rb') as f:
sent = word2vec.LineSentence(f)
model = word2vec.Word2Vec(sentences=sent)
model.save("data/line_sentnce.model")
#使用 PathLineSentences 接口加载数据
def train_PathLineSentences():
#传递目录,遍历目录下的所有文件
sent = word2vec.PathLineSentences("./data/")
print(sent)
model = word2vec.Word2Vec(sentences=sent)
model.save("data/PathLineSentences.model")
#数据加载与训练分开
def train_left():
sent = word2vec.Text8Corpus(fname="data/in_the_name_of_people_cut.txt")
#定义模型
model = word2vec.Word2Vec()
#构造词典
model.build_vocab(sentences=sent)
#模型训练
model.train(sentences=sent, total_examples=model.corpus_count, epochs=model.epochs)
model.save("data/left.model")
if __name__ == "__main__":
preprocess_in_the_name_of_people()
#模型加载与使用
train_in_the_name_of_people()
model = word2vec.Word2Vec.load("data/in_the_name_of_people.model")
print(model.wv.most_similar("吃饭"))
print(model.wv.similarity("省长", "省委书记"))
train_line_sentence()
model2 = word2vec.Word2Vec.load("data/line_sentnce.model")
print(model2.wv.similarity("李达康", "市委书记"))
top3 = model2.wv.similar_by_word(word="李达康", topn=3)
print(top3)
#报编码错误,暂时未找到原因
#train_PathLineSentences()
#model3 = word2vec.Word2Vec.load("data/PathLineSentences.model")
#print(model3.similarity("李达康", "书记"))
#print(model3.wv.similarity("李达康", "书记"))
#print(model3.wv.doesnt_match(words=["李达康", "高育良", "赵立春"]))
train_left()
model4 = word2vec.Word2Vec.load("data/left.model")
print(model4.wv.similarity("李达康", "书记"))
print(model.wv.doesnt_match(u"沙瑞金 高育良 李达康 刘庆祝".split()))
总结
以上为使用 Word2Vec 训练词向量的流程,你可以自己训练后应用到生产环境中。除了维基百科的语料,另外也可以使用搜狗开源的新闻语料。另外更加推荐腾讯放出词向量数据(已跑好的模型)。该数据包含 800 多万中文词汇,相比现有的公开数据,在覆盖率、新鲜度及准确性上大幅提高。


