情感分析是一种常见的自然语言处理(NLP)方法的应用,特别是在以提取文本的情感内容为目标的分类方法中。通过这种方式,情感分析可以被视为利用一些情感得分指标来量化定性数据的方法。尽管情绪在很大程度上是主观的,但是情感量化分析已经有很多有用的实践,比如企业分析消费者对产品的反馈信息,或者检测在线评论中的差评信息。
最简单的情感分析方法是利用词语的正负属性来判定。句子中的每个单词都有一个得分,乐观的单词得分为+1,悲观的单词则为-1。然后我们对句子中所有单词得分进行加总求和得到一个最终的情感总分。很明显,这种方法有许多局限之处,最重要的一点在于它忽略了上下文的信息。例如,在这个简易模型中,因为“not”的得分为-1,而“good”的得分为+1,所以词组“not good”将被归类到中性词组中。尽管词组“not good”中包含单词“good”,但是人们仍倾向于将其归类到悲观词组中。
另外一个常见的方法是将文本视为一个“词袋”。我们将每个文本看出一个1*N的向量,其中N表示文本词汇的数量。该向量中每一列都是一个单词,其对应的值为该单词出现的频数。这些数据可以被应用到机器学习分类算法中(比如Logistic回归或者支持向量机),从而预测未知数据的情感状况。需要注意的是,这种有监督学习的方法要求利用已知情感状况的数据作为训练集。虽然这个方法改进了之前的模型,但是它仍然忽略了上下文的信息和数据集的规模情况。例如,句子“这部电影糟糕透了”和“一个乏味,空洞,没有内涵的作品”在情感分析中具有很高的语义相似度,但是它们的BOW表示的相似度为0。又如,句子“一个空洞,没有内涵的作品”和“一个不空洞而且有内涵的作品”的BOW相似度很高,但实际上它们的意思很不一样。
Word2Vec和Doc2Vec
Google开发的Word2Vec的方法,该方法可以在捕捉语境信息的同时压缩数据规模。Word2Vec实际上是两种不同的方法:Continuous Bag of Words (CBOW)和Skip-gram。CBOW的目标是根据上下文来预测当前词语的概率。Skip-gram刚好相反:根据当前词语来预测上下文的概率。这两种方法都利用人工神经网络作为它们的分类算法。起初,每个单词都是一个随机N维向量。经过训练之后,该算法利用CBOW或者Skip-gram的方法获得了每个单词的最优向量。
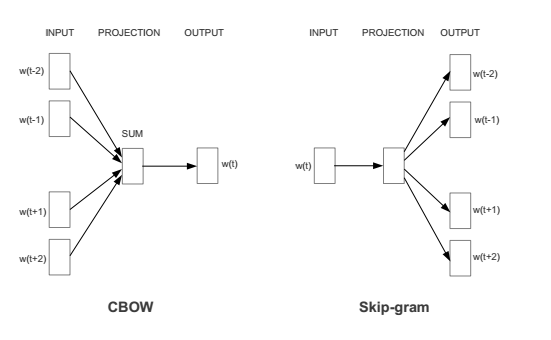
现在这些词向量已经捕捉到上下文的信息。我们可以利用基本代数公式来发现单词之间的关系(比如,“king”–“man”+“woman”=“queen”)。这些词向量可以代替词袋用来预测未知数据的情感状况。该模型的优点在于不仅考虑了语境信息还压缩了数据规模(通常情况下,词汇量规模大约在300个单词左右而不是之前模型的100000个单词)。因为神经网络可以替我们提取出这些特征的信息,所以我们仅需要做很少的手动工作。但是由于文本的长度各异,我们可能需要利用所有词向量的平均值作为分类算法的输入值,从而对整个文本文档进行分类处理。
然而,即使上述模型对词向量进行平均处理,我们仍然忽略了单词之间的排列顺序对情感分析的影响。作为一个处理可变长度文本的总结性方法,Quoc Le和Tomas Mikolov提出了Doc2Vec方法。除了增加一个段落向量以外,这个方法几乎等同于Word2Vec。和Word2Vec一样,该模型也存在两种方法:Distributed Memory (DM)和Distributed Bag of Words (DBOW)。DM试图在给定上下文和段落向量的情况下预测单词的概率。在一个句子或者文档的训练过程中,段落ID保持不变,共享着同一个段落向量。DBOW则在仅给定段落向量的情况下预测段落中一组随机单词的概率。
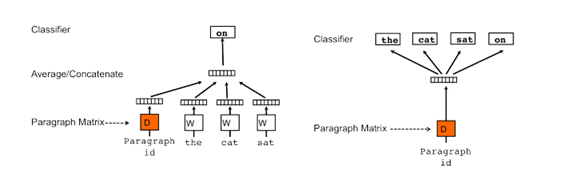
一旦开始被训练,这些段落向量可以被纳入情感分类器中而不必对单词进行加总处理。这个方法是当前最先进的方法,当它被用于对IMDB电影评论数据进行情感分类时,该模型的错分率仅为7.42%。当然如果我们无法真正实施的话,一切都是浮云。幸运的是,genism(Python软件库)中Word2Vec和Doc2Vec的优化版本是可用的。
Word2Vec与情感分析
Word2Vec可以识别单词之间重要的关系。这使得它在许多NLP项目和我们的情感分析案例中非常有用。将它运用到情感分析案例之前,让我们先来测试下Word2Vec对单词的分类能力。我们将利用三个分类的样本集:食物、运动和天气单词集合,我们可以从EnchantedLearning下载得到这三个数据集。这里Word2Vec使用训练好的词向量文件:GoogleNews-vectors-negative300.bin
# 获取分类词
import requests
import re
from django.utils.html import strip_tags
pattern = re.compile("<div class=wordlist-item>(.*?)</div>")
def get_dict(category):
url = "https://www.enchantedlearning.com/wordlist/{0}.shtml".format(category)
r = requests.get(url)
item_list = re.findall(pattern, r.text)
for item in item_list:
with open("./data/"+category+"_words.txt", 'a', encoding='utf-8') as f:
f.write(strip_tags(item)+'\n')
if __name__ == "__main__":
get_dict("sports")
get_dict("food")
get_dict("weather")
由于这是一个300维的向量,为了在2D视图中对其进行可视化,我们需要利用Scikit-Learn中的降维算法t-SNE处理源数据。
import numpy as np
import gensim
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
model = gensim.models.KeyedVectors.load_word2vec_format('./data/GoogleNews-vectors-negative300.bin', binary=True)
with open('./data/food_words.txt', 'r') as infile:
food_words = infile.readlines()
with open('./data/sports_words.txt', 'r') as infile:
sports_words = infile.readlines()
with open('./data/weather_words.txt', 'r') as infile:
weather_words = infile.readlines()
def get_word_vecs(words):
vecs = []
for word in words:
word = word.replace('\n', '')
try:
vecs.append(model[word].reshape((1, 300)))
except KeyError:
continue
vecs = np.concatenate(vecs)
return np.array(vecs, dtype='float') # TSNE expects float type values
food_vecs = get_word_vecs(food_words)
sports_vecs = get_word_vecs(sports_words)
weather_vecs = get_word_vecs(weather_words)
ts = TSNE(2)
reduced_vecs = ts.fit_transform(np.concatenate((food_vecs, sports_vecs, weather_vecs)))
# color points by word group to see if Word2Vec can separate them
for i in range(len(reduced_vecs)):
if i< len(food_vecs):
color = 'b' # food words colored blue
elif len(food_vecs) <= i< (len(food_vecs) + len(sports_vecs)):
color = 'r' # sports words colored red
else:
color = 'g' # weather words colored green
plt.plot(reduced_vecs[i, 0], reduced_vecs[i, 1], marker='o', color=color, markersize=8)
plt.show()
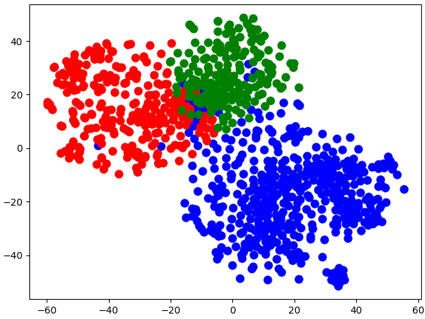
从上图可以看出,Word2Vec很好地分离了不相关的单词,并对它们进行聚类处理。
Word2Vec情感分析实战
Emoji推文的情感分析
利用emoji表情对我们的数据添加模糊的标签。笑脸表情:-)表示乐观情绪,皱眉标签:-(表示悲观情绪。总的400000条推文被分为乐观和悲观两组数据。我们随机从这两组数据中抽取样本,构建比例为8:2的训练集和测试集。随后,我们对训练集数据构建Word2Vec模型,其中分类器的输入值为推文中所有词向量的加权平均值。
训练数据:https://github.com/udaykeith/Meetup-4thNov
#导入数据并构建Word2Vec模型:
from sklearn.model_selection import train_test_split
from gensim.models.word2vec import Word2Vec
import numpy as np
from sklearn.preprocessing import scale
from sklearn.linear_model import SGDClassifier
from sklearn.metrics import roc_curve, auc
import matplotlib.pyplot as plt
with open('twitter_data/pos_tweets.txt', 'r', encoding="utf-8") as infile:
pos_tweets = infile.readlines()
with open('twitter_data/neg_tweets.txt', 'r', encoding="utf-8") as infile:
neg_tweets = infile.readlines()
# use 1 for positive sentiment, 0 for negative
y = np.concatenate((np.ones(len(pos_tweets)), np.zeros(len(neg_tweets))))
x_train, x_test, y_train, y_test = train_test_split(np.concatenate((pos_tweets, neg_tweets)), y, test_size=0.2)
def clean_text(corpus):
corpus = [z.lower().replace('\n', '').split() for z in corpus]
return corpus
x_train = clean_text(x_train)
x_test = clean_text(x_test)
# Initialize model and build vocab
n_dim = 300
twitter_w2v = Word2Vec(size=n_dim, min_count=10)
twitter_w2v.build_vocab(x_train)
# Train the model over train_reviews (this may take several minutes)
twitter_w2v.train(x_train, epochs=twitter_w2v.epochs, total_examples=twitter_w2v.corpus_count)
# 获得推文中所有词向量的平均值
# Build word vector for training set by using the average value of all word vectors in the tweet, then scale
def build_word_vector(text, size):
vec = np.zeros(size).reshape((1, size))
count = 0.
for word in text:
try:
vec += twitter_w2v.wv[word].reshape((1, size))
count += 1.
except KeyError:
continue
if count != 0:
vec /= count
return vec
# 调整数据集的量纲是数据标准化处理的一部分,我们通常将数据集转化成服从均值为零的高斯分布,这说明数值大于均值表示乐观,反之则表示悲观。
train_vecs = np.concatenate([build_word_vector(z, n_dim) for z in x_train])
train_vecs = scale(train_vecs)
# Train word2vec on test tweets
twitter_w2v.train(x_test, epochs=twitter_w2v.epochs, total_examples=twitter_w2v.corpus_count)
# 建立测试集向量并对其标准化处理:
# Build test tweet vectors then scale
test_vecs = np.concatenate([build_word_vector(z, n_dim) for z in x_test])
test_vecs = scale(test_vecs)
lr = SGDClassifier(loss='log', penalty='l1')
lr.fit(train_vecs, y_train)
print('Test Accuracy: %.2f' % lr.score(test_vecs, y_test))
# Create ROC curve
pred_probas = lr.predict_proba(test_vecs)[:, 1]
fpr, tpr, _ = roc_curve(y_test, pred_probas)
roc_auc = auc(fpr, tpr)
plt.plot(fpr, tpr, label='area=%.2f' % roc_auc)
plt.plot([0, 1], [0, 1], 'k--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.legend(loc='lower right')
plt.show()
返回结果:Test Accuracy: 0.73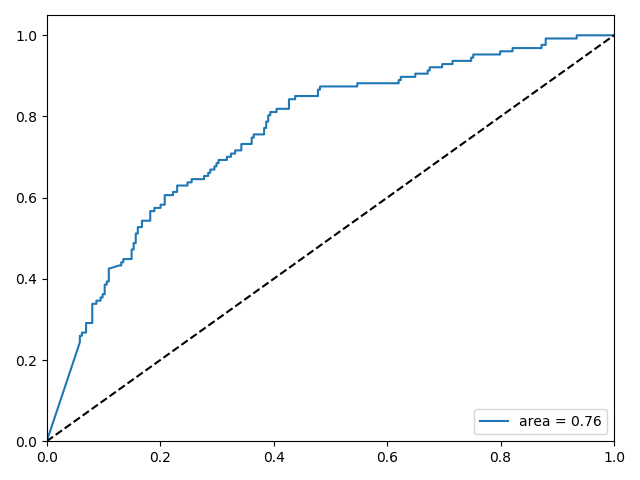
在没有创建任何类型的特性和最小文本预处理的情况下,利用Scikit-Learn构建的简单线性模型的预测精度为73%。有趣的是,删除标点符号会影响预测精度,这说明Word2Vec模型可以提取出文档中符号所包含的信息。处理单独的单词,训练更长时间,做更多的数据预处理工作,和调整模型的参数都可以提高预测精度。使用人工神经网络(ANNs)模型可以提高5%的预测精度。需要注意的是,Scikit-Learn没有提供ANN分类器的实现工具,所以利用了创建的自定义库:https://github.com/mczerny/NNet
from NNet import NeuralNet
nnet = NeuralNet(100, learn_rate=1e-1, penalty=1e-8)
maxiter = 1000
batch = 150
_ = nnet.fit(train_vecs, y_train, fine_tune=False, maxiter=maxiter, SGD=True, batch=batch, rho=0.9)
print('Test Accuracy: %.2f' % nnet.score(test_vecs, y_test))
执行后的结果为Test Accuracy: 0.67,反而更差了。另外NNet在执行时会报错,需要对报错的地方进行修复,代码混乱,不建议使用。
利用Doc2Vec分析IMDB电影评论数据
训练数据集:http://ai.stanford.edu/~amaas/data/sentiment/
使用Word2Vec进行情感分析
import numpy as np
import matplotlib.pyplot as plt
import gensim
from gensim.utils import open
from gensim.models import Word2Vec
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import scale
from sklearn.metrics import roc_curve, auc
import random
# 读取影评内容
with open('./imdb_data/pos.txt', 'r', encoding='utf-8') as infile:
pos_reviews = []
line = infile.readline()
while line:
pos_reviews.append(line)
line = infile.readline()
with open('./imdb_data/neg.txt', 'r', encoding='utf-8') as infile:
neg_reviews = []
line = infile.readline()
while line:
neg_reviews.append(line)
line = infile.readline()
with open('./imdb_data/unsup.txt', 'r', encoding='utf-8') as infile:
unsup_reviews = []
line = infile.readline()
while line:
unsup_reviews.append(line)
line = infile.readline()
# 数据划分,1代表积极情绪,0代表消极情绪
y = np.concatenate((np.ones(len(pos_reviews)), np.zeros(len(neg_reviews))))
x_train, x_test, y_train, y_test = train_test_split(np.concatenate((pos_reviews, neg_reviews)), y, test_size=0.2)
def labelize_reviews(reviews):
for i, v in enumerate(reviews):
yield gensim.utils.simple_preprocess(v, max_len=100)
x_train_tag = list(labelize_reviews(x_train))
x_test_tag = list(labelize_reviews(x_test))
unsup_reviews_tag = list(labelize_reviews(unsup_reviews))
model = Word2Vec(size=200, window=10, min_count=1)
# 对所有评论创建词汇表
all_data = x_train_tag
all_data.extend(x_test_tag)
all_data.extend(unsup_reviews_tag)
model.build_vocab(all_data)
def sentences_perm(sentences):
shuffled = list(sentences)
random.shuffle(shuffled)
return (shuffled)
for epoch in range(10):
print('EPOCH: {}'.format(epoch))
model.train(sentences_perm(all_data), total_examples=model.corpus_count, epochs=1)
def build_word_vector(text, size=200):
vec = np.zeros(size).reshape((1, size))
count = 0.
for word in text:
try:
vec += model[word]
count += 1.
except KeyError:
continue
if count != 0:
vec /= count
return vec
train_vecs = np.concatenate([build_word_vector(gensim.utils.simple_preprocess(z, max_len=200)) for z in x_train])
test_vecs = np.concatenate([build_word_vector(gensim.utils.simple_preprocess(z, max_len=200)) for z in x_test])
train_vecs = scale(train_vecs)
test_vecs = scale(test_vecs)
classifier = LogisticRegression()
classifier.fit(train_vecs, y_train)
print(classifier.score(test_vecs, y_test))
y_prob = classifier.predict_proba(test_vecs)[:, 1]
fpr, tpr, _ = roc_curve(y_test, y_prob)
roc_auc = auc(fpr, tpr)
plt.plot(fpr, tpr, label='area=%.2f' % roc_auc)
plt.plot([0, 1], [0, 1], 'k--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.legend(loc='lower right')
plt.show()
最终的得分为0.8859使用Doc2Vec进行情感分析
利用词向量均值对推文进行分析效果不错,这是因为推文通常只有十几个单词,所以即使经过平均化处理仍能保持相关的特性。一旦我们开始分析段落数据时,如果忽略上下文和单词顺序的信息,那么我们将会丢掉许多重要的信息。在这种情况下,最好是使用Doc2Vec来创建输入信息。
from gensim.utils import open, simple_preprocess
from gensim.models.doc2vec import TaggedDocument
from gensim.models import Doc2Vec
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_curve, auc
import matplotlib.pyplot as plt
import random
# 读取影评内容
with open('./imdb_data/pos.txt', 'r', encoding='utf-8') as infile:
pos_reviews = []
line = infile.readline()
while line:
pos_reviews.append(line)
line = infile.readline()
with open('./imdb_data/neg.txt', 'r', encoding='utf-8') as infile:
neg_reviews = []
line = infile.readline()
while line:
neg_reviews.append(line)
line = infile.readline()
with open('./imdb_data/unsup.txt', 'r', encoding='utf-8') as infile:
unsup_reviews = []
line = infile.readline()
while line:
unsup_reviews.append(line)
line = infile.readline()
# 数据划分
# 1代表积极情绪,0代表消极情绪
y = np.concatenate((np.ones(len(pos_reviews)), np.zeros(len(neg_reviews))))
x_train, x_test, y_train, y_test = train_test_split(np.concatenate((pos_reviews, neg_reviews)), y, test_size=0.2)
# 创建TaggedDocument对象
# Gensim的Doc2Vec工具要求每个文档/段落包含一个与之关联的标签。我们利用TaggedDocument进行处理。
# 格式形如"TRAIN_i"或者"TEST_i",其中"i"是索引
def labelize_reviews(reviews, label_type):
for i, v in enumerate(reviews):
label = '%s_%s' % (label_type, i)
yield TaggedDocument(simple_preprocess(v, max_len=100), [label])
x_train_tag = list(labelize_reviews(x_train, 'train'))
x_test_tag = list(labelize_reviews(x_test, 'test'))
unsup_reviews_tag = list(labelize_reviews(unsup_reviews, 'unsup'))
# 实例化Doc2vec模型
# 下面我们实例化两个Doc2Vec模型,DM和DBOW。
# gensim文档建议多次训练数据,并且在每一步(pass)调节学习率(learning rate)或者用随机顺序输入文本。
# 接着我们收集了通过模型训练后的电影评论向量。
# DM和DBOW会进行向量叠加,这是因为两个向量叠加后可以获得更好的结果
size = 100
model_dm = Doc2Vec(min_count=1, window=10, vector_size=size, sample=1e-3, negative=5, workers=3,
epochs=10)
model_dbow = Doc2Vec(min_count=1, window=10, vector_size=size, sample=1e-3, negative=5, dm=0, workers=3,
epochs=10)
# 对所有评论创建词汇表
all_data = x_train_tag
all_data.extend(x_test_tag)
all_data.extend(unsup_reviews_tag)
model_dm.build_vocab(all_data)
model_dbow.build_vocab(all_data)
def sentences_perm(sentences):
shuffled = list(sentences)
random.shuffle(shuffled)
return (shuffled)
for epoch in range(10):
print('EPOCH: {}'.format(epoch))
model_dm.train(sentences_perm(all_data), total_examples=model_dm.corpus_count, epochs=1)
model_dbow.train(sentences_perm(all_data), total_examples=model_dbow.corpus_count, epochs=1)
# 获取生成的向量
# 获取向量有两种方式,一种是根据上面我们定义的标签来获取,另一种通过输入一篇文章的内容来获取这篇文章的向量。
# 更推荐使用第一种方式来获取向量。
# 第一种方法
train_arrays_dm = np.zeros((len(x_train), 100))
train_arrays_dbow = np.zeros((len(x_train), 100))
for i in range(len(x_train)):
tag = 'train_' + str(i)
train_arrays_dm[i] = model_dm.docvecs[tag]
train_arrays_dbow[i] = model_dbow.docvecs[tag]
train_arrays = np.hstack((train_arrays_dm, train_arrays_dbow))
test_arrays_dm = np.zeros((len(x_test), 100))
test_arrays_dbow = np.zeros((len(x_test), 100))
for i in range(len(x_test)):
tag = 'test_' + str(i)
test_arrays_dm[i] = model_dm.docvecs[tag]
test_arrays_dbow[i] = model_dbow.docvecs[tag]
test_arrays = np.hstack((test_arrays_dm, test_arrays_dbow))
# 第二种
def get_vecs(model, corpus):
vecs = []
for i in corpus:
vec = model.infer_vector(simple_preprocess(i, max_len=300))
vecs.append(vec)
return vecs
train_vecs_dm = get_vecs(model_dm, x_train)
train_vecs_dbow = get_vecs(model_dbow, x_train)
train_vecs = np.hstack((train_vecs_dm, train_vecs_dbow))
# 预测
classifier = LogisticRegression()
classifier.fit(train_arrays, y_train)
print(classifier.score(test_arrays, y_test))
y_prob = classifier.predict_proba(test_arrays)[:, 1]
fpr, tpr, _ = roc_curve(y_test, y_prob)
roc_auc = auc(fpr, tpr)
plt.plot(fpr, tpr, label='area=%.2f' % roc_auc)
plt.plot([0, 1], [0, 1], 'k--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.legend(loc='lower right')
plt.show()
最终得分为:0.8911
参考链接:


