在数据统计分析中,经常会遇到需要对时间进行格式转化或其他层面的内容。由于每种数据库自带的相关函数存在一定的差异,所以经常会记不得如何使用。今天做下简单的梳理。 在开始学习日期/时间函数先,先来了解下…

Python有很多Web框架:Django、Flask、Tornodo、web.py。我们可以基于这些框架来开发我们的网站。这些框架其实是给我们封装了很多底层的实现。比如WSGI、模板、映射等功能。为了在使用这些框架时对其有更深入的了解…
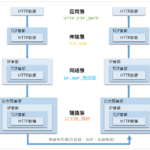
WSGI (Python Web Server Gateway Interface) 为 Web Server 和 Python Web Application 之间提供了标准的数据通道。是 Python 界的一个广泛的可用的 WEB API 规范,使 web server 提供更加规范的 API,给 web Appl…

PEP 全称是 Python Enhancement Proposal,翻译成中文是 Python 改进提案。为什么会有 C 语言的风格指南?原因是 Python 本身是由 C 语言实现的。这里整理的是PEP 7 -- Style Guide for C Code 的翻译。 介绍 这…

Python编码规范PEP8文章中提到了PEP257,Docstring书写规范。什么是Docstring?简单的说Docstring是一种文档字符串,用于解释构造的作用。我们在函数、类或方法中将它放在首位来描述其作用。我们用三个单引号或双引…

对于Web系统来说,客户端一般就是浏览器,客户端与服务器之间使用HTTP协议通讯。在Python的Web开发中,服务器与Python Web应用之间交互的协议就是WSGI。它由PEP 333提出,并在PEP 3333中做了补充。如果你也想阅读WS…
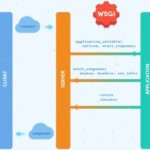
MySQL数据库索引结构 在MySQL中,索引属于存储引擎级别的概念,不同存储引擎对索引的实现方式是不同的,MySQL存储引擎MyISAM、InnoDB文章中,我们讲到了两者在存储结构上的差异。下面主要讨论MyISAM和InnoDB两个存…
Git 是由 Linux Torvalds 开发的一个版本控制系统,现如今正在被全世界大量开发者使用。许多公司喜欢使用基于 Git 版本控制的 GitHub 代码托管。GitHub 是现如今全世界最大的代码托管网站。许多大型公司现如今也将…

博客先前部署在阿里云上马上就要过期,正好双11腾讯云做活动,所以将服务器迁移到腾讯云。迁移的同时打算换个操作系统部署,将原有的CentOS7.4更换为Ubuntu20.04LTS。 其他环境基本不变,还是和以前一样使用Nginx+…

什么是Session? 在计算机科学领域来说,尤其是在网络领域,session是一种持久网络协议,在用户(或用户代理)端和服务器端之间创建关联,从而起到交换数据包的作用机制,session在网络协议(例如telnet或FTP)中是…