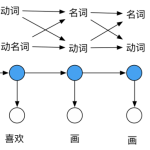
词性标注(Part-of-Speech tagging 或 POS tagging),又称词类标注或者简称标注,是指为分词 结果中的每个单词标注一个正确的词性的程序,也即确定每个词是名词、动词、形容词或其他词性的过程。词主要可以分为以下…
结巴分词 就是前面说的中文分词,这里需要介绍的是一个分词效果较好,使用起来像但方便的Python模块:结巴。 结巴中文分词采用的算法 基于Trie树结构实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成…

NLTK简介 NLTK (Natural Language Toolkit)是由宾夕法尼亚大学计算机和信息科学使用 python 语言实现的一种自然语言工具包,其收集的大量公开数据集、模型上提供了全面、易用的接口,涵盖了分词、词性标注(Part-Of-…
情感分析是一种常见的自然语言处理(NLP)方法的应用,特别是在以提取文本的情感内容为目标的分类方法中。通过这种方式,情感分析可以被视为利用一些情感得分指标来量化定性数据的方法。尽管情绪在很大程度上是主观…
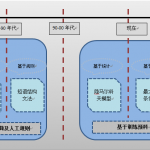
完整的中文自然语言处理过程一般包括以下五种中文处理核心技术:分词、词性标注、命名实体识别、依存句法分析、语义分析。其中,分词是中文自然语言处理的基础,搜素引擎、文本挖掘、机器翻译、关键词提取、自动摘…
FastText简介 fastText是Facebook于2016年开源的一个词向量计算和文本分类工具,在文本分类任务中,fastText(浅层网络)往往能取得和深度网络相媲美的精度,却在训练时间上比深度网络快许多数量级。在标准的多核CP…

GloVe简介 GloVe的全称叫 Global Vectors for Word Representation,它是一个基于全局词频统计(count-based & overall statistics)的词表征(word representation)工具。 Glove与LSA的区别 LSA(Latent Semant…
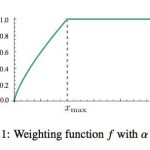
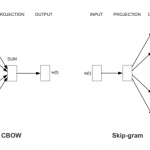
word2vec是Google在2013年推出的一个NLP工具,它的特点是将所有的词向量化,这样词与词之间就可以定量的去度量他们之间的关系,挖掘词之间的联系。word2vec工具主要包含两个模型:跳字模型(skip-gram)和连续词袋…






