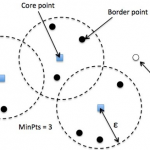
矩阵分解简介 推荐领域的人一般都会听说过十年前 Netflix Prize 的比赛,随着 Netflix Prize 推荐比赛的成功举办,近年来隐语义模型(Latent Factor Model,LFM)受到越来越多的关注。隐语义模型最早在文本挖掘领域…
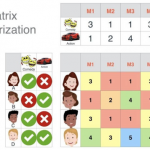
神经网络简介 神经网络的结构模仿生物神经网络,生物神经网络中的每个神经元与其他神经元相连,当它"兴奋"时,向下一级相连的神经元发送化学物质,改变这些神经元的电位;如果某神经元的电位超过一个阈值,则被激活…
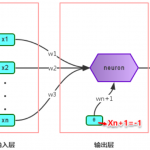
普通RNN存在的问题 循环神经网络(Recurrent Neural Network,RNN)是一种用于处理序列数据的神经网络。相比一般的神经网络来说,他能够处理序列变化的数据。比如某个单词的意思会因为上文提到的内容不同而有不同的…
情感分析是一种常见的自然语言处理(NLP)方法的应用,特别是在以提取文本的情感内容为目标的分类方法中。通过这种方式,情感分析可以被视为利用一些情感得分指标来量化定性数据的方法。尽管情绪在很大程度上是主观…
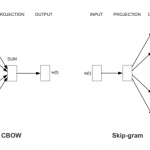
在“卷积神经网络”中我们探究了如何使用二维卷积神经网络来处理二维图像数据。在之前的语言模型和文本分类任务中,我们将文本数据看作是只有一个维度的时间序列,并很自然地使用循环神经网络来表征这样的数据。其实…
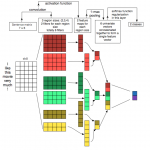
CatBoost是俄罗斯的搜索巨头Yandex在2017年开源的机器学习库,是Gradient Boosting(梯度提升)+Categorical Features(类别型特征),也是基于梯度提升决策树的机器学习框架。 CatBoost 简介 CatBoost这个名字来…
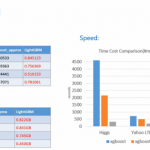
上一篇文章介绍了一个梯度提升决策树模型XGBoost,这篇文章我们继续学习一下GBDT模型的另一个进化版本:LightGBM。LigthGBM是boosting集合模型中的新进成员,由微软提供,它和XGBoost一样是对GBDT的高效实现,原理…
集成学习 集成学习是通过训练若干个弱学习器,并通过一定的结合策略,从而形成一个强学习器。有时也被称为多分类器系统(multi-classifier system)、基于委员会的学习(committee-based learning)等。 集成学…
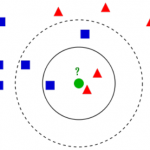
什么是K-近邻算法? K近邻法(k-nearest neighbor, k-NN)是1967年由Cover T和Hart P提出的一种基本分类与回归方法。它的工作原理是:存在一个样本数据集合,也称作为训练样本集,并且样本集中每个数据都存在标签,即…
K-Means算法和MeanShift算法都是基于距离的聚类算法,基于距离的聚类算法的聚类结果是球状的簇,当数据集中的聚类结果是非球状结构时,基于距离的聚类算法的聚类效果并不好。 与基于距离的聚类算法不同的是,基…