在“卷积神经网络”中我们探究了如何使用二维卷积神经网络来处理二维图像数据。在之前的语言模型和文本分类任务中,我们将文本数据看作是只有一个维度的时间序列,并很自然地使用循环神经网络来表征这样的数据。其实,我们也可以将文本当作一维图像,从而可以用一维卷积神经网络来捕捉临近词之间的关联。
TextCNN简介
TextCNN是利用卷积神经网络对文本进行分类的算法,由Yoon Kim在《Convolutional Neural Networks for Sentence Classification》中提出。
TextCNN结构图:
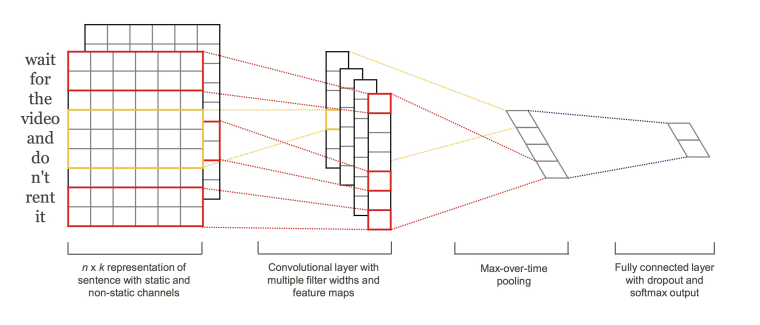
第一层将单词嵌入到低维矢量中。下一层使用多个过滤器大小对嵌入的单词向量执行卷积。例如,一次滑动3,4或5个单词。接下来,将卷积层的结果最大池化为一个长特征向量,添加dropout正则,并使用softmax对结果进行分类。与传统图像的CNN网络相比, textCNN在网络结构上没有任何变化(甚至更加简单了), 从图中可以看出textCNN其实只有一层卷积, 一层max-pooling, 最后将输出外接softmax来n分类。
与图像当中CNN的网络相比,textCNN最大的不同便是在输入数据的不同:图像是二维数据, 图像的卷积核是从左到右, 从上到下进行滑动来进行特征抽取。自然语言是一维数据, 虽然经过word-embedding生成了二维向量,但是对词向量做从左到右滑动来进行卷积没有意义. 比如”今天”对应的向量[0,0,0,0,1], 按窗口大小为1*2从左到右滑动得到[0,0],[0,0],[0,0],[0,1]这四个向量, 对应的都是”今天”这个词汇, 这种滑动没有帮助.
TextCNN的成功, 不是网络结构的成功, 而是通过引入已经训练好的词向量来在多个数据集上达到了超越benchmark的表现,进一步证明了构造更好的embedding, 是提升nlp各项任务的关键能力。
TextCNN最大优势网络结构简单, 在模型网络结构如此简单的情况下,通过引入已经训练好的词向量依旧有很不错的效果,在多项数据数据集上超越benchmark。网络结构简单导致参数数目少, 计算量少, 训练速度快,在单机单卡的v100机器上,训练165万数据, 迭代26万步,半个小时左右可以收敛。
TextCNN流程
Word Embedding分词构建词向量
textcnn使用预先训练好的词向量作embedding layer。对于数据集里的所有词,因为每个词都可以表征成一个向量,因此我们可以得到一个嵌入矩阵M, M里的每一行都是词向量。这个M可以是静态(static)的,也就是固定不变。可以是非静态(non-static)的,也就是可以根据反向传播更新。
如图所示, textCNN首先将”今天天气很好,出来玩”分词成”今天/天气/很好/,/出来/玩, 通过word2vec或者GLOV等embedding方式将每个词成映射成一个5维(维数可以自己指定)词向量, 如”今天”->[0,0,0,0,1], “天气”->[0,0,0,1,0], “很好”->[0,0,1,0,0]等等。
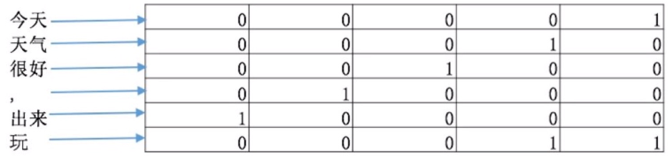
这样做的好处主要是将自然语言数值化,方便后续的处理。从这里也可以看出不同的映射方式对最后的结果是会产生巨大的影响, nlp当中目前最火热的研究方向便是如何将自然语言映射成更好的词向量。我们构建完词向量后,将所有的词向量拼接起来构成一个6*5的二维矩阵,作为最初的输入。
Convolution卷积
输入一个句子,首先对这个句子进行切词,假设有s个单词。对每个词,跟句嵌入矩阵M, 可以得到词向量。假设词向量一共有d维。那么对于这个句子,便可以得到s行d列的矩阵$A \epsilon R^{s \times d}$。我们可以把矩阵A看成是一幅图像,使用卷积神经网络去提取特征。由于句子中相邻的单词关联性总是很高的,因此可以使用一维卷积。卷积核的宽度就是词向量的维度d,高度是超参数,可以设置。
假设有一个卷积核,是一个宽度为d,高度为h的矩阵w,那么w有h∗d个参数需要被更新。对于一个句子,经过嵌入层之后可以得到矩阵$\epsilon R^{s \times d}$。$A[i:j]$表示A的第i行到第j行,那么卷积操作可以用如下公式表示:$o_i = w \cdot A[i:i+h-1]$
叠加上偏置b, 在使用激活函数f激活, 得到所需的特征。公式如下:$c_i = f(o_i + b)$
对一个卷积核,可以得到特征$c \epsilon R^{s-h+1}$, 总共$s−h+1$个特征。我们可以使用更多高度不同的卷积核,得到更丰富的特征表达。
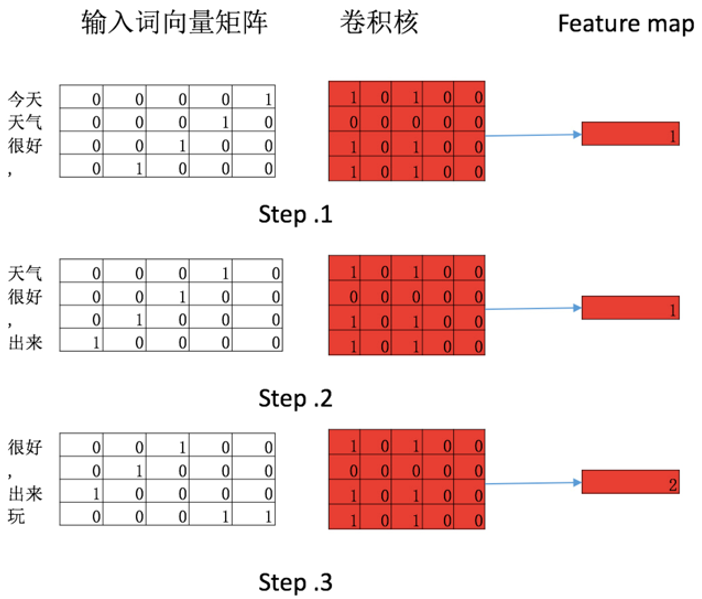
卷积是一种数学算子。我们用一个简单的例子来说明一下
- 1将”今天”/”天气”/”很好”/”,”对应的4*5矩阵与卷积核做一个pointwise的乘法然后求和, 便是卷积操作
- 2将窗口向下滑动一格(滑动的距离可以自己设置), “天气”/”很好”/”,”/”出来”对应的4*5矩阵与卷积核(权值不变)继续做pointwise乘法后求和
- 3将窗口向下滑动一格(滑动的距离可以自己设置)”很好”/”,”/”出来”/”玩”对应的4*5矩阵与卷积核(权值不变)继续做pointwise乘法后求和
feature_map便是卷积之后的输出, 通过卷积操作将输入的6*5矩阵映射成一个3*1的矩阵,这个映射过程和特征抽取的结果很像,于是便将最后的输出称作feature map。一般来说在卷积之后会跟一个激活函数,在这里为了简化说明需要,我们将激活函数设置为f(x)=xchannel
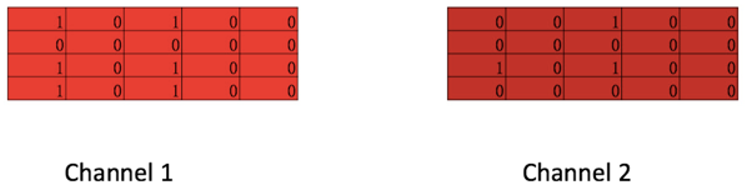
在CNN中常常会提到一个词channel, 图中深红矩阵与浅红矩阵便构成了两个channel统称一个卷积核, 从这个图中也可以看出每个channel不必严格一样, 每个4*5矩阵与输入矩阵做一次卷积操作得到一个feature map. 在计算机视觉中,由于彩色图像存在R,G,B三种颜色, 每个颜色便代表一种channel。根据原论文作者的描述, 一开始引入channel是希望防止过拟合(通过保证学习到的vectors不要偏离输入太多)来在小数据集合获得比单channel更好的表现,后来发现其实直接使用正则化效果更好。不过使用多channel相比与单channel, 每个channel可以使用不同的word embedding, 比如可以在no-static(梯度可以反向传播)的channel来finetune词向量,让词向量更加适用于当前的训练。对于channel在textCNN是否有用, 从论文的实验结果来看多channels并没有明显提升模型的分类能力, 七个数据集上的五个数据集单channel的textCNN表现都要优于多channels的textCNN。

我们在这里也介绍一下论文中四个model的不同:
- CNN-rand(单channel), 设计好embedding_size这个Hyperparameter后, 对不同单词的向量作随机初始化, 后续BP的时候作调整.
- CNN-non-static (单 channel), pre-trained vectors + finetuning, 即拿 word2vec 训练好的词向量初始化, 训练过程中再对它们微调.
- CNN-multiple channel (多 channels), 类比于图像中的 RGB 通道, 这里也可以用 static 与 non-static 搭两个通道来做.
CNN-static (单 channel), 拿 pre-trained vectors from word2vec, FastText or GloVe 直接用, 训练过程中不再调整词向量.
Pooling 池化
不同尺寸的卷积核得到的特征 (feature map) 大小也是不一样的,因此我们对每个 feature map 使用池化函数,使它们的维度相同。最常用的就是 1-max pooling,提取出 feature map 照片那个的最大值。这样每一个卷积核得到特征就是一个值,对所有卷积核使用 1-max pooling,再级联起来,可以得到最终的特征向量,这个特征向量再输入 softmax layer 做分类。这个地方可以使用 dropout 防止过拟合。
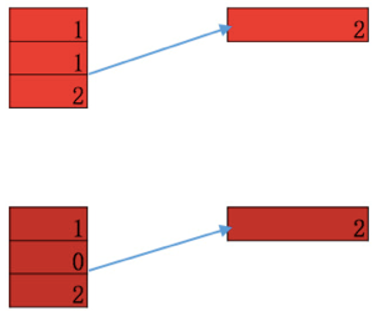
得到 feamap=[1,1,2] 后, 从中选取一个最大值 [2] 作为输出, 便是 max-pooling。max-pooling 在保持主要特征的情况下, 大大降低了参数的数目, 从图中可以看出 feature map 从三维变成了一维, 好处有如下两点:
- 降低了过拟合的风险, feature map=[1,1,2] 或者 [1,0,2] 最后的输出都是 [2], 表明开始的输入即使有轻微变形, 也不影响最后的识别。
- 参数减少, 进一步加速计算。
pooling 本身无法带来平移不变性 (图片有个字母 A, 这个字母 A 无论出现在图片的哪个位置, 在 CNN 的网络中都可以识别出来),卷积核的权值共享才能。max-pooling 的原理主要是从多个值中取一个最大值,做不到这一点。cnn 能够做到平移不变性,是因为在滑动卷积核的时候,使用的卷积核权值是保持固定的 (权值共享), 假设这个卷积核被训练的就能识别字母 A, 当这个卷积核在整张图片上滑动的时候,当然可以把整张图片的 A 都识别出来。
使用 softmax k 分类
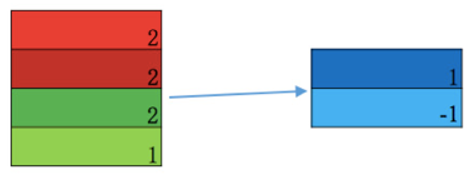
如图所示, 我们将 max-pooling 的结果拼接起来, 送入到 softmax 当中, 得到各个类别比如 label 为 1 的概率以及 label 为 -1 的概率。如果是预测的话,到这里整个 textCNN 的流程遍结束了。如果是训练的话,此时便会根据预测 label 以及实际 label 来计算损失函数, 计算出 softmax 函数, max-pooling 函数, 激活函数以及卷积核函数四个函数当中参数需要更新的梯度, 来依次更新这四个函数中的参数,完成一轮训练。
总结
以上过程可以用下图直观表示:
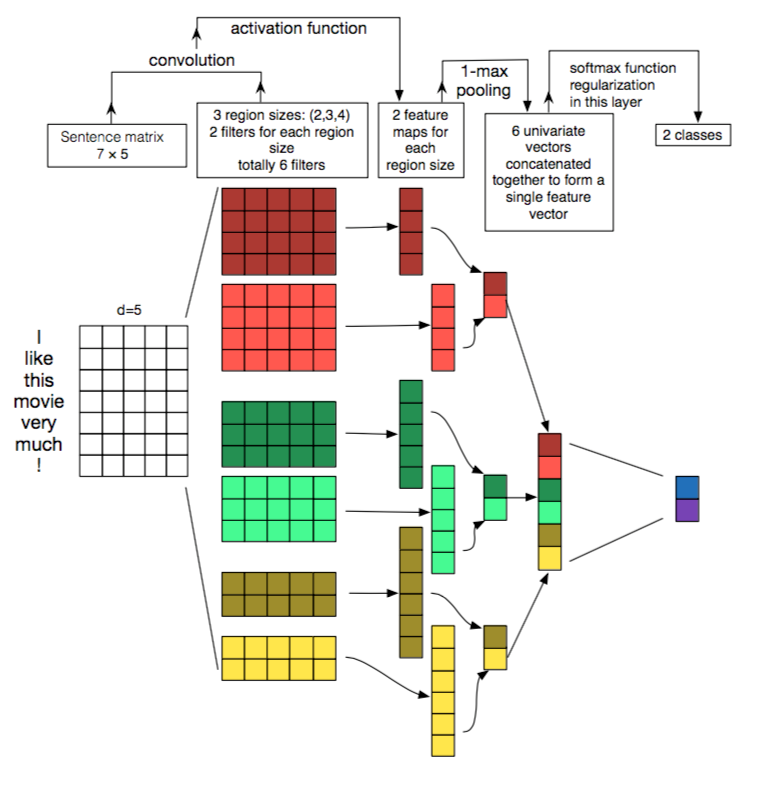
- 这里 word embedding 的维度是 5。对于句子 i like this movie very much。可以转换成如上图所示的矩阵
- 有 6 个卷积核,尺寸为 (2×5) (2×5), (3×5) (3×5), 4×5 4×5,每个尺寸各 2 个.
- AA 分别与以上卷积核进行卷积操作,再用激活函数激活。每个卷积核都得到了特征向量 (feature maps)
- 使用 1-max pooling 提取出每个 feature map 的最大值,然后在级联得到最终的特征表达。
- 将特征输入至 softmax layer 进行分类, 在这层可以进行正则化操作 (l2-regulariation)
使用 Keras 搭建卷积神经网络来进行情感分析
在自然语言领域,卷积的作用在于利用文字的局部特征。一个词的前后几个词必然和这个词本身相关,这组成该词所代表的词群。词群进而会对段落文字的意思进行影响,决定这个段落到底是正向的还是负向的。对比传统方法,利用词包,和 TF-IDF 等,其思想有相通之处。但最大的不同点在于,传统方法是人为构造用于分类的特征,而深度学习中的卷积让神经网络去构造特征。以上便是卷积在自然语言处理中有着广泛应用的原因。接下来介绍如何利用 Keras 搭建卷积神经网络来处理情感分析的分类问题。
下面的代码构造了卷积神经网络的结构:
from keras.layers import Dense, Dropout, Activation, Flatten from keras.layers import Conv1D, MaxPooling1D from keras.models import Sequential from keras.layers.embeddings import Embedding from keras.datasets import imdb import numpy as np from keras.preprocessing import sequence (X_train, y_train), (X_test, y_test) = imdb.load_data() max_word = 400 X_train = sequence.pad_sequences(X_train, maxlen=max_word) X_test = sequence.pad_sequences(X_test, maxlen=max_word) vocab_size = np.max([np.max(X_train[i]) for i in range(X_train.shape[0])]) + 1 #这里 1 代表空格,其索引被认为是 0。 model = Sequential() model.add(Embedding(vocab_size, 64, input_length=max_word)) model.add(Conv1D(filters=64, kernel_size=3, padding='same', activation='relu')) model.add(MaxPooling1D(pool_size=2)) model.add(Dropout(0.25)) model.add(Conv1D(filters=128, kernel_size=3, padding='same', activation='relu')) model.add(MaxPooling1D(pool_size=2)) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(64, activation='relu')) model.add(Dense(32, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy', optimizer='rmsprop', metrics=['accuracy']) print(model.summary()) model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=20, batch_size=100) scores = model.evaluate(X_test, y_test, verbose=1) print(scores)
整个模型的结构如下:
Model: "sequential_1" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= embedding_1 (Embedding) (None, 400, 64) 5669568 _________________________________________________________________ conv1d_1 (Conv1D) (None, 400, 64) 12352 _________________________________________________________________ max_pooling1d_1 (MaxPooling1 (None, 200, 64) 0 _________________________________________________________________ dropout_1 (Dropout) (None, 200, 64) 0 _________________________________________________________________ conv1d_2 (Conv1D) (None, 200, 128) 24704 _________________________________________________________________ max_pooling1d_2 (MaxPooling1 (None, 100, 128) 0 _________________________________________________________________ dropout_2 (Dropout) (None, 100, 128) 0 _________________________________________________________________ flatten_1 (Flatten) (None, 12800) 0 _________________________________________________________________ dense_1 (Dense) (None, 64) 819264 _________________________________________________________________ dense_2 (Dense) (None, 32) 2080 _________________________________________________________________ dense_3 (Dense) (None, 1) 33 ================================================================= Total params: 6,528,001 Trainable params: 6,528,001 Non-trainable params: 0 _________________________________________________________________
TextCNN的超参数调参
在最简单的仅一层卷积的TextCNN结构中,下面的超参数都对模型表现有影响:
- 初始化词向量。使用word2vec和golve都可以,不要使用one-hot vectors
- 卷积核的尺寸。1-10之间,具体情况具体分析,对最终结果影响较大。一般来讲,句子长度越长,卷积核的尺寸越大。另外,可以在寻找到了最佳的单个filter的大小后,尝试在该filter的尺寸值附近寻找其他合适值来进行组合。实践证明这样的组合效果往往比单个最佳filter表现更出色
- 每种尺寸卷积核的数量。100-600之间,对模型性能影响较大,需要注意的是增加卷积核的数量会增加训练模型的实践。主要考虑的是当增加特征图个数时,训练时间也会加长,因此需要权衡好。当特征图数量增加到将性能降低时,可以加强正则化效果,如将dropout率提高过5
- 激活函数的选择。使用relu函数
- dropout rate。0-0.5,当增加卷积核的数量时,可以尝试增加dropout rate,甚至可以大于0.5
- 池化的选择。1-max pooling表现最佳
- 正则项。相对于其他超参数来说,影响较小点
参考链接:


