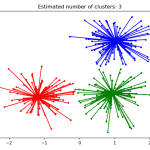
主题模型是用来在非结构数据中无监督的发现隐含主题信息的一类重要工具,比较成熟和常用的算法有基于矩阵分解(如:SVD分解)的LSA(Latent Semantic Analysis), 引入概率方法代替SVD的pLSA(Probabilistic Latent…
DBSCAN (Density-Based Spatial Clustering of Applications with Noise) 是一种常用于聚类分析的算法,它可以很好地应用于经纬度数据的聚类。这种算法特别适合处理大规模的空间数据集,并且能够识别出噪声点。在先…
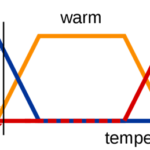
Fuzzy C-Means简介 模糊理论 模糊控制是自动化控制领域的一项经典方法。其原理则是模糊数学、模糊逻辑。1965,L.A. Zadeh发表模糊集合“Fuzzy Sets”的论文,首次引入隶属度函数的概念,打破了经典数学“非0即1”的局限…
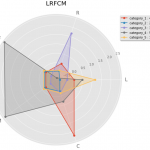
谈到用户分类模型,最被谈及的应该就是RFM模型了。大部分人常把RFM模型挂在嘴边,而在实际使用中的却很难真正的利用起来。这里暂时不去讨论RFM是好是坏。今天的介绍的是另外一个拓展的模型:航空公司客户价值分析模…
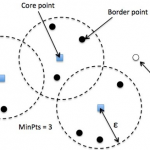
K-Means算法和MeanShift算法都是基于距离的聚类算法,基于距离的聚类算法的聚类结果是球状的簇,当数据集中的聚类结果是非球状结构时,基于距离的聚类算法的聚类效果并不好。 与基于距离的聚类算法不同的是,基…
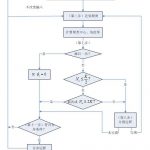
ISODATA算法(Iterative Self Organizing Data Analysis Techniques Algorithm,迭代自组织数据分析方法)和K-Means算法是相似的算法,都是属于无监督的聚类分析方法,但是 在之前介绍的K-Means算法中,有两大缺陷…
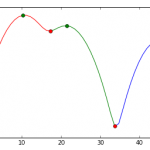
大部分聚类方法针对的是多维数据,现实场景中还有可能存在以为数据的情况,针对以为数组的聚类和多维的数据有很大的不同,今天就来实战演练下: 需求内容:分析订单的价格分布 常见方案:按照100为梯度,分析不…
在学习聚类算法得时候并没有涉及到评估指标,主要原因是聚类算法属于非监督学习,并不像分类算法那样可以使用训练集或测试集中得数据计算准确率、召回率等。那么如何评估聚类算法得好坏呢?好的聚类算法,一般要求类…

标签传播算法(label propagation)简介 半监督学习 机器学习可以大体分为三大类:监督学习、非监督学习和半监督学习。 监督学习可以认为是我们有非常多的labeled标注数据来train一个模型,期待这个模型能学习到…
Affinity Propagation算法简介 AP (Affinity Propagation)通常被翻译为近邻传播算法或者亲和力传播算法。AP算法的基本思想是将全部数据点都当作潜在的聚类中心(称之为exemplar),然后数据点两两之间连线构成一个网…