文章内容如有错误或排版问题,请提交反馈,非常感谢!
Implicit简介
Implicit是一个开源的协同过滤项目,其包含多种流行的推荐算法,主要应用场景是针对隐性反馈行为进行推荐。包含的算法主要有:
- ALS(alternating least squares),最小交替二乘法
- BRP(Bayesian Personalized Ranking),贝叶斯个性化排序
- Logistic Matrix Factorization
- 使用Cosine, TF-IDF或BM25的近邻模型
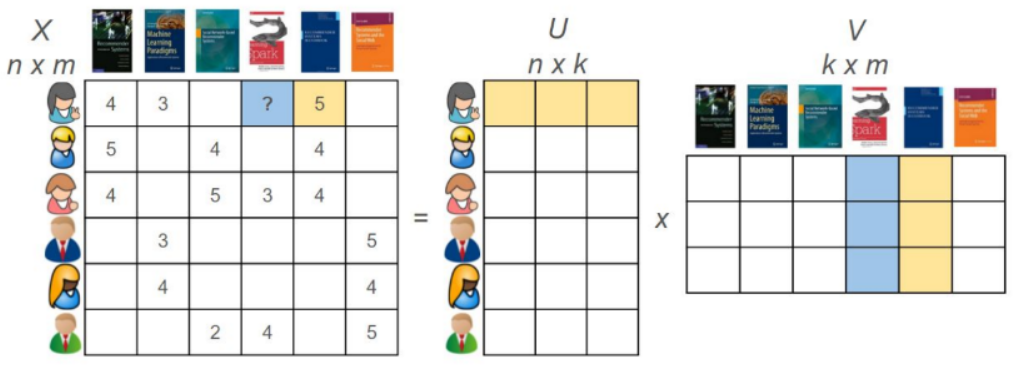
Implicit使用
数据准备
Implicit输入需要使用的数据格式为user_id/item_id/rating,其中对于隐性评分的场景,可以根据具体情况进行设置,比如:
- 按照浏览时间设置不同的rating
- 按照浏览深度设置不同的rating(是否看过图片、点评等)
- 按照不同行为设置不同的rating(浏览、收藏、加购)
模型训练
import pandas as pd
import numpy as np
import scipy.sparse as sparse
import implicit
df = pd.read_csv("./data/user_visit.csv")
df['user_label'], user_idx = pd.factorize(df['user_id'])
df['item_label'], item_idx = pd.factorize(df['item_id'])
sparse_item_user = sparse.csr_matrix((df['rating'].astype(float), (df['item_label'], df['user_label'])))
sparse_user_item = sparse.csr_matrix((df['rating'].astype(float), (df['user_label'], df['item_label'])))
model = implicit.als.AlternatingLeastSquares(factors=50, regularization=0.1, iterations=50)
model.fit(sparse_item_user)
data = {
'model.item_factors': model.item_factors,
'model.user_factors': model.user_factors,
'item_labels': item_idx,
}
als_model_file = "user_visit.npz"
np.savez(als_model_file, **data)
注意:
- 这里使用了ALS算法,具体模型参数怎么调优目前还没有好的解决方案,给出的参数是随意给的。
- 这里将模型结果存储到.npz文件中,便于后期直接使用,而不是每次使用时都要训练。
- 需要对原先的user_id,item_id进行重新编码,否则会报错
模型使用
#加载模型 data = np.load(als_model_file, allow_pickle=True) model = implicit.als.AlternatingLeastSquares(factors=data['model.item_factors'].shape[1]) model.item_factors = data['model.item_factors'] model.user_factors = data['model.user_factors'] model._YtY = model.item_factors.T.dot(model.item_factors) item_labels = data['item_labels'] #基于酒店推荐: item_id = 1024 item_lable = list(item_labels).index(item_id) related = model.similar_items(item_lable, N=10) for item_lable, score in related: print(item_labels[item_lable], score) #基于用户推荐 user_id = 10 user_label = list(user_idx).index(user_id) sparse_user_items = sparse_item_user.T.tocsr() recommendations = model.recommend(user_label, sparse_user_items) for item_id, score in recommendations: print(item_idx[item_id], score)
实时推荐
实时推荐的方案是使用离线模型结合实时行为进行推荐,而不是把整个模型部署到线上实时运行。中间主要区别是用户ID是不存在的,所以不能使用userid进行直接推荐。具体实现方式如下:
item_ids = [1024, 2046] item_weights = [2, 3] user_label = 0 user_items = None item_lb = [list(item_labels).index(i) for i in item_ids] user_ll = [0]*len(item_ids) confidence = [10]*len(item_ids) if item_weights is None else item_weights user_items = sparse.csr_matrix((confidence, (user_ll, item_lb))) recommendations = model.recommend(user_label, user_items, N=10, recalculate_user=True) for item_id, score in recommendations: print(item_labels[item_id], score) #根据返回的结果,获取推荐理由: itemid = list(item_labels).index(2048) model.explain(user_label, user_items, itemid, user_weights=None, N=1)
参考资料:
- https://github.com/benfred/implicit
- https://implicit.readthedocs.io/en/latest/index.html
- https://github.com/redbubble/pyrec
- Predicting User Preferences in Python using Alternating Least Squares
Building a Collaborative Filtering Recommender System with ClickStream Data


