Apache Arrow 是一个跨语言的开发平台,用于处理和分析大数据。它的主要目标是提高数据分析的速度和效率,尤其是在需要在不同系统或编程语言之间共享数据时。 Apache Arrow 简介 产生背景 Apache Arrow 的产生背…
Apache Avro简介 Apache Avro是一种数据序列化系统,广泛用于数据的高效存储与传输,尤其是在大数据处理和分布式系统中。它最初由Hadoop项目开发,旨在解决数据序列化时的兼容性、效率和可移植性问题。 Avro(读音…

GraphQL简介 GraphQL是由Facebook开发的一种用于构建API的查询语言和运行时环境。与传统的REST API不同,GraphQL允许客户端灵活地指定所需的数据结构,从而实现更高效的客户端-服务器交互。 GraphQL的核心概念 …
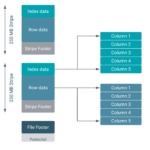
Apache Parquet 简介 Apache Parquet 是一种列式存储格式,专为高效处理大规模数据而设计。它最初由 Twitter 和 Cloudera 开发,现在是 Apache 软件基金会的顶级项目。Parquet 的设计目标是优化存储效率和查询性能…
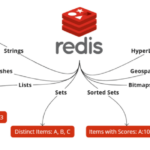
Redis简介 Redis是一个开源的高性能键值存储系统,其全称为“Remote Dictionary Server”。它被广泛用作内存缓存、数据库、消息中间件和分布式锁等场景。 Redis的特点 高性能:Redis的读写速度非常快,能读的速…
dbt简介 dbt (data build tool)是一个开源的数据转换和建模工具,由 dbt Labs 开发和维护。dbt 旨在简化数据仓库中的数据转换和建模过程,帮助数据工程师和分析师高效地管理和执行数据管道。dbt 核心(dbt-core)是…
Zeppelin简介 Apache Zeppelin是一个开源的Notebook工具,旨在为数据科学家、数据工程师和分析师提供一个交互式的环境,用于数据探索、可视化和协作分析。它支持多种后端数据处理引擎,使用户能够在一个统一的界面…
StackStorm简介 StackStorm是一个开源的事件驱动自动化平台,旨在通过自动化工作流来协调和管理IT基础设施、应用程序和服务。它结合了事件监控、反应规则和自动化操作,为DevOps团队提供了一种强大的工具,用于管理…

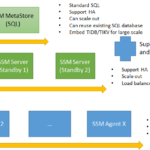
SSM(Smart Storage Manager)简介 SSM(Smart Storage Manager)是一个由 Intel 开源的 HDFS 存储管理系统,致力于提供 HDFS 数据的智能管理方案。 SSM 的核心功能 SSM 的核心功能主要围绕数据的智能管理展开,…
Snakemake简介 Snakemake是一个用于创建可重现和可扩展的数据分析管道的工作流管理系统。它广泛应用于生物信息学、数据科学和科学研究领域,帮助用户自动化和管理复杂的数据处理任务。Snakemake的设计灵感来自GNU M…